本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。

AI for security を真剣に考えるために学ぶ、エージェント設計とコンテキストエンジニアリング
1. はじめに
前回の記事では、LLMの基礎知識と2026年現在の勢力図、Function Callingの仕組み、そしてMastraを使ったワンショットのセキュリティヘッダー診断エージェントを作るところまでお伝えしました。
今回は第2弾です。前回作ったエージェントは、ユーザーの指示に対してツールを1回呼び出し、結果を分析して終わりというものでした。実際にやってみるとわかりますが、これだけでは実務に耐えません。「複数のURLを順番に調べて」「問題があったら深掘りして」「最後にレポートにまとめて」といった複合的なタスクになると、途端にエージェントの挙動が不安定になります。
「エージェントはなぜ"途中で壊れる"のか? そしてどう設計すれば安定するのか?」
今回はこの問いについて掘り下げていきます。LLMのチャットが裏側でどういうデータ構造で動いているのか、エージェントの設計パターンにはどんな種類があるのか、プロンプトはどう書けば効果的か、そして「コンテキストエンジニアリング」という新しい考え方について解説します。後半では実際にMastraでDeepResearchエージェントを組み、さらにモデルを差し替えたときの挙動差異を実験した結果もお見せします。
2. LLMチャットの内部構造を深く理解する
前回「LLMはテキストを生成しているだけ」と書きました。今回はその"テキスト"が、実際にはどういうデータ構造で流れているのかを覗いてみましょう。エージェントが壊れる原因の多くは、この内部構造の理解不足に起因します。
2.1 メッセージ履歴の構造
ChatGPTやClaude、あるいはAPI経由でLLMを使う場合、裏側ではメッセージの配列がやり取りされています。普段のチャット画面では見えませんが、実体はこんなJSONです。
[
{
"role": "system",
"content": "あなたはWebアプリケーションセキュリティの専門家です。..."
},
{
"role": "user",
"content": "https://example.com のセキュリティヘッダーを診断してください"
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"function": {
"name": "check_security_headers",
"arguments": "{\"url\": \"https://example.com\"}"
}
}
]
},
{
"role": "tool",
"tool_call_id": "call_abc123",
"content": "{\"statusCode\": 200, \"securityHeaders\": {\"contentSecurityPolicy\": null, ...}}"
},
{
"role": "assistant",
"content": "診断結果をご報告します。CSPヘッダーが未設定のため..."
}
]ポイントは4つの role です。
| role | 役割 |
system |
LLMへの「人格設定」や「行動ルール」。ユーザーには見えない裏方の指示書。前回のコードで instructions に書いた部分がここに入る |
user |
人間の入力。チャットで打ち込んだテキスト |
assistant |
LLMの応答。テキストを返すこともあれば、ツール呼び出しを「テキストとして」返すこともある |
tool |
ツールの実行結果。エージェントフレームワークがツールを実際に実行し、その結果をこのroleで会話に挿入する |
重要なのは、LLMは毎回この配列全体を入力として受け取るということです。チャットの「続き」を書いているように見えますが、実際には毎回のリクエストで過去の会話履歴をまるごと送り直しています。LLMにはステートレス、すなわち「記憶」がありません。すべてがこのメッセージ配列というコンテキストで成り立っています。
2.2 コンテキストウィンドウ管理
LLMが一度に処理できるテキスト量には上限があります。これが コンテキストウィンドウ です。前回の表で見た「128K」「200K」トークンという数字がこれにあたります。
たとえば200Kトークンは、日本語で概算すると10〜15万文字程度です。それなりの分量に見えますが、エージェントがマルチステップで動くと、ツール呼び出しの結果が次々と tool roleのメッセージとして積まれていきます。セキュリティヘッダーの診断結果、HTML全文の取得、スキャン結果…… あっという間にウィンドウが積み上がります。
ウィンドウが積み上がるとどうなるか。まず溢れてしまった場合は古いメッセージから切り捨てられるか、あるいはAPIがエラーを返します。切り捨てられた場合、LLMは途中経過を「忘れた」状態で次のステップを実行することになります。また、モデルのスペックとしてコンテキストウインドウが十分にサポートされていても常に同じクオリティで返答できるわけではありません。コンテキストウインドウが90%の空きがある状態と、20%の空きがある状態ではLLMの回答クオリティに影響が出ます。エージェントが意味不明な行動を取り始める原因の一つです。
この問題に対処する方法はいくつかあります。
| 手法 | 概要 |
| Sliding Window | 古いメッセージを単純に削除し、直近のN件だけを保持する。単純だが、重要な過去情報が失われるリスクがある |
| Compaction(要約圧縮) | コンテキストが一定量に達したら、古いメッセージ群をLLMに要約させて短い文章に圧縮する。Claude Codeなどが採用している方式 |
| Observational Memory | Mastraが2026年2月にリリースした新しいアプローチ。Observer AgentとReflector Agentという2つの裏方エージェントが会話履歴を監視し、重要な「観察事項」だけを記録していく。Compactionのような一括要約ではなく、イベントベースのログ[1] |
Andrej Karpathy(OpenAI共同創業者、元Tesla AI Director)は、LLMのコンテキストウィンドウを「RAM」に例えました[2]。RAMが溢れたらOSはどうする? ページングやスワップで対処する事が多いですね。エージェントのコンテキスト管理も、本質的には同じ問題に取り組んでいるわけです。
2.3 System Prompt設計のベストプラクティス
前回のコードでは、System Promptをこんな感じで書きました。
あなたはWebアプリケーションセキュリティの専門家です。
与えられたURLのHTTPセキュリティヘッダーを分析し、以下の観点で評価してください:
1. 各セキュリティヘッダーの有無と設定値の適切性
2. 欠落しているヘッダーがもたらすリスク(具体的な攻撃シナリオ)
3. 推奨される設定値(コピー&ペースト可能な形式で)
4. OWASP Secure Headers Projectの推奨事項との比較ワンショットの用途ならこれで十分でした。しかしマルチステップのエージェントになると、もっと構造化された指示が必要です。
<role>
あなたはWebアプリケーションセキュリティ診断の専門エージェントです。
</role>
<task_management>
タスクを受け取ったら、以下のプロセスに従ってください:
1. まず実行計画(Plan)を立て、ステップを番号付きで宣言する
2. 各ステップを [Step N/M] の形式で明示してから実行する
3. ツールの実行結果を観察し、次のステップに反映する
4. 全ステップ完了後、サマリーレポートを生成する
</task_management>
<output_format>
診断結果は以下の形式で報告すること:
- 重要度: Critical / High / Medium / Low / Info
- 該当CWE番号(あれば)
- リスクの説明(攻撃シナリオを含む)
- 推奨される設定値
</output_format>
<constraints>
- ツールの実行結果にないことを推測で補完しない
- 不確実な情報には「未確認」と明記する
- 1つのURLに対して最大5回までのツール呼び出しとする
</constraints>XMLタグやMarkdown見出しで 構造化 する手法は、Anthropicの公式ドキュメントでも推奨されています。構造化することでLLMが指示を「区別」しやすくなり、特にマルチステップ実行時の指示追従性が向上します。System Promptの設計はこの後で詳しく掘り下げます。
3. エージェントの種類
前回は自律性を4段階に分類しました。今回はシングルエージェントとマルチエージェントの構造的な違いにフォーカスし、代表的なフレームワークも紹介します。
3.1 シングルエージェント
1つのLLMインスタンスが複数のツールを使ってタスクを実行する構成です。前回作ったセキュリティヘッダー診断エージェントがこれにあたります。
シングルエージェントの長所はシンプルさです。1つのSystem Promptですべてを制御でき、コンテキストが分散しない。短めのタスクなら十分に機能します。
一方で限界もあります。タスクが複雑になるとSystem Promptが肥大化し、LLMの「注意力」が分散します。いくらハイスペックなモデルであっても、大きなコンテキストウインドウをサポートしていても、複数のタスク(偵察もスキャンも分析もレポートなど)を全部1つのLLMに任せるのは、コストもかかりますし破綻しやすい構造になります。
3.2 マルチエージェント
複数のLLMインスタンス(エージェント)が、それぞれ専門的な役割を持って協調する構成です。人間のチームと同じ発想で、偵察担当・分析担当・レポート担当のように分業します。
代表的なマルチエージェントフレームワークを2つ紹介します。
AutoGen
Microsoftの研究チームが開発した AutoGen は、マルチエージェントフレームワークの先駆けとして知られます。ただし現在は少しややこしいことになっていて、オリジナルの開発者たちがMicrosoftを離れてコミュニティ主導の AG2 として独立し、Microsoft側のAutoGen 0.4はSemantic Kernel統合に向けた完全な書き直しが進んでいます[3]。
AG2の特徴は 会話ベース の協調パターンです。GroupChat(グループチャット形式で複数エージェントが議論)と Swarm(群れのように自律分散で動作)という2つのオーケストレーションパターンを提供しています。Python製ですが筆者は深く触れていません。
CrewAI
CrewAI は「AIにチームを組ませる」というコンセプトのフレームワークです[4]。LangChainに依存せずスクラッチで構築されており、10万人以上の認定開発者コミュニティを持ちます。
CrewAIの設計は明快で、4つの基本要素で構成されます。
| 要素 | 役割 | 具体例 |
| Agent | 役割(role)と目標(goal)を持つ専門ワーカー | 偵察エージェント、脆弱性分析エージェント |
| Task | 具体的な作業単位 | 「対象URLのポートスキャンを実行せよ」 |
| Crew | エージェントのチーム | セキュリティ診断Crew |
| Tools | エージェントが使う外部機能 | Nmap連携、Burp Suite API等 |
タスク実行モードとして Sequential(順次)、Parallel(並列)、Conditional(条件分岐)を選べます。人間の組織構造を模倣するような設計は直感的でわかりやすいです。
3.3 フレームワーク比較
| フレームワーク | 言語 | 設計思想 | 強み | 注意点 |
| Autogen | Python | 会話ベースの協調。GroupChat/Swarm | 柔軟な会話パターン、研究用途に強い | AutoGenとの分裂で情報が錯綜 |
| CrewAI | Python | 役割ベースのチーム構成 | 直感的な設計、大きなコミュニティ | 高度なカスタマイズには制約あり |
| Mastra | TypeScript | Workflows + Agents + Memory | MCP対応、Memory/RAG統合、Observational Memory | エコシステムがまだ若い |
| LangGraph | Python/JS | グラフベースのオーケストレーション | 2025年10月にv1.0安定版。ビジュアルデバッグ | 学習コストが高い |
筆者はTypeScript環境で開発しているためMastraを使っていますが、Python環境であればCrewAIやLangGraphも有力な選択肢です。フレームワーク選定より重要なのは、次のセクションで解説する設計パターンの理解です。パターンを理解していれば、どのフレームワークでも応用が効きます。
4. エージェント設計パターン
エージェントの「頭脳」であるLLMにどう考えさせ、どう行動させるか。研究コミュニティでは複数の設計パターンが提案されています。ここでは実務で特に重要な4つを深掘りします。
4.1 ReAct 深掘り
前回軽く触れた ReAct(Reasoning + Acting)[5]を、もう少し丁寧に見ていきます。
ReActの基本は Thought → Action → Observation のループです。LLMが「考え」をテキストとして出力し、それに基づいて「行動」(ツール呼び出し)を行い、「観察」(ツールの結果)を得て、また「考える」。この繰り返しです。
セキュリティ診断での具体的なトレースを見てみましょう。
Thought: ユーザーはexample.comのセキュリティ診断を求めている。
まずHTTPセキュリティヘッダーを確認しよう。
Action: check_security_headers(url="https://example.com")
Observation: CSP未設定、HSTS設定済み(max-age=31536000)、X-Frame-Options未設定...
Thought: CSPとX-Frame-Optionsが未設定だ。CSPが未設定の場合、
XSSのリスクが高まる。サイトの内容を確認して、
どの程度のリスクかを評価したい。
Action: fetch_page_content(url="https://example.com")
Observation: フォーム要素あり、外部スクリプト読み込みあり...
Thought: フォームと外部スクリプトがある。CSP未設定の状態では
XSSによるフォームデータの窃取リスクがCriticalレベルだ。
レポートをまとめよう。
Action: (ツール呼び出しなし。最終回答を生成)
ReActの強みは透明性です。LLMが何を考えてその行動を取ったかがThoughtとして記録されるため、デバッグしやすい。そしてLLMがツールを呼び出しやすい特徴があります。一方で弱点もあります。毎ステップでLLMに問い合わせるため、ステップ数に比例してコストと時間がかかること、そしてLLMが途中で目的を見失うことがある(特にステップ数が多くなると顕著である)ことです。
4.2 Plan-and-Execute
ReActの「毎回考える」コストを削減するために提案されたのが Plan-and-Execute パターンです[6]。BabyAGIやHuggingGPTに端を発するこの手法は、計画と実行を分離します。
[Planner LLM]
Plan:
E1: HTTPセキュリティヘッダーの取得 → check_security_headers("https://example.com")
E2: E1の結果からCSP未設定の場合 → fetch_page_content("https://example.com")
E3: E1とE2の結果を統合 → generate_report(#E1, #E2)
[Executor]
E1を実行 → 結果取得
E2を実行(E1の結果を参照)→ 結果取得
E3を実行(E1, E2の結果を参照)→ レポート生成
[Re-planner]
結果を評価し、追加ステップが必要なら再計画#E1, #E2 のように前ステップの結果を参照できるのが特徴的です。Executor側は軽量なLLM(あるいはルールベース)でも動作するため、高価なLLMはPlannerだけに使うというコスト最適化が可能です。
前回紹介したセキュリティ研究 CheckMate がまさにこのパターンで、古典的AIプランニング(PDDL等)をPlanner、LLMをExecutorとして使っていました。計画と実行の分離は、セキュリティ診断のようにワークフローが比較的決まっているタスクと相性が良いです。
4.3 Reflexion(自己反省)
Reflexion(Shinn et al., 2023)[7]は、エージェントに「反省する能力」を与えるパターンです。
人間でも、テストで間違えた問題を復習すると次は解けるようになる。Reflexionも同じ発想で、失敗した経験を言語化してメモリに保存し、次の試行で参照する仕組みです。
構成は3つのモデルから成ります。
| コンポーネント | 役割 |
| Actor | 実際にタスクを実行するエージェント |
| Evaluator | Actorの行動結果を評価する(成功/失敗の判定) |
| Self-Reflection | 失敗時に「何が悪かったか」を言語化し、次の試行に活かすためのフィードバックを生成 |

論文では、HumanEval(コーディングベンチマーク)で91% pass@1を達成し、当時のGPT-4の80%を上回りました[7]。実用的なヒューリスティックとして、「同じアクションを3サイクル繰り返したらリフレクションを発動する」「30アクション以上で非効率と判断してリフレクション」というルールが提案されています。
セキュリティ診断で言えば、「WAFに阻まれてスキャンが失敗した → なぜ失敗したかを分析 → 次はリクエスト間隔を空けるか、別のペイロードを試す」といった学習ループに応用できる考え方です。ただ仕組みが複雑になりがちでこのパターンを採用しているケースをあまり見れていません(とはいいつつプロプライエタリ製品だとそのアーキテクチャを知ることは難しいのですが)
4.5 パターン比較
| パターン | 基本動作 | 長所 | 短所 | 適用場面 |
| ReAct | Thought→Action→Observe のループ | 透明性が高い。デバッグしやすい | ステップ数に比例するコスト。目的喪失 | 汎用的。まず試すならこれ |
| Plan-and-Execute | 計画→実行→再計画 | コスト効率。計画の再利用 | 計画の質がPlannerに依存 | ワークフローが比較的定まっているタスク |
| Reflexion | 試行→評価→反省→再試行 | 失敗からの学習。精度向上 | 複数試行が前提。時間がかかる | 正解の検証が可能なタスク(コーディング等) |
実務では、これらのパターンを組み合わせて使うことが多いです。最近のコーディングエージェントは Plan-and-Executeで全体計画を立て、各ステップの実行にReActを使い、失敗したらReflexionで振り返る、といった形で進めるケースが多いです。
5. マルチエージェント構成の設計原則
設計パターンを理解した上で、複数のエージェントを「どう組むか」の原則論に入ります。
5.1 オーケストレーター型 vs ピアツーピア型
マルチエージェントの構成は、大きく2つのアーキテクチャに分かれます。
| オーケストレーター型 | ピアツーピア型 | |
| 構造 | 1つの司令塔エージェントが他のエージェントに指示を出す | 各エージェントが対等に会話・交渉して合意に至る |
| 利点 | 制御しやすい。デバッグしやすい | 柔軟。創発的な振る舞いが出やすい |
| 欠点 | 司令塔がボトルネックになる | 収束しにくい。コストが高い |
| 代表例 | CrewAIのHierarchicalプロセス、HuggingGPT | AutogenのGroupChat |
セキュリティ診断の文脈では、オーケストレーター型のほうが扱いやすいと筆者は考えています。診断ワークフローには「偵察→スキャン→分析→レポート」という比較的決まった流れがあり、司令塔がその進行を管理するのが自然です。また、比較的デバッグしやすいです。
5.2 コンテキスト共有戦略
マルチエージェントで最も悩ましいのが、エージェント間でどの程度の情報を共有するかです。
「全員に全部記憶共有をすればよい」と思うかもしれませんが、そうすると各エージェントのコンテキストウィンドウが膨れ上がり、前述の通りパフォーマンスが低下します。逆に情報を分離しすぎると、あるエージェントが別のエージェントの発見を活かせない。
実務的なアプローチとして、Blackboard方式があります。共有の「黒板」(構造化されたデータストア)を用意し、各エージェントは自分の作業結果を黒板に書き込み、必要な情報だけを黒板から読む。全会話履歴を共有するのではなく、構造化された結果だけを共有するわけです。
5.3 エラーハンドリングとフォールバック
マルチステップのエージェントでは、途中で何かが壊れることを前提に設計します。
- ToolCall失敗時のリトライ: ネットワークエラーやタイムアウトは当たり前に起きる。3回まで自動リトライなど
- ToolCall崩壊の検知: LLMが存在しないツール名を生成したり、引数の型がスキーマと合わない場合のバリデーション
- maxStepsの設定: 無限ループ防止。Mastraでは
maxStepsパラメータで制御可能 - フォールバック: メインのモデルが不安定なときに別のモデルに切り替える
5.4 セキュリティ診断への適用イメージ
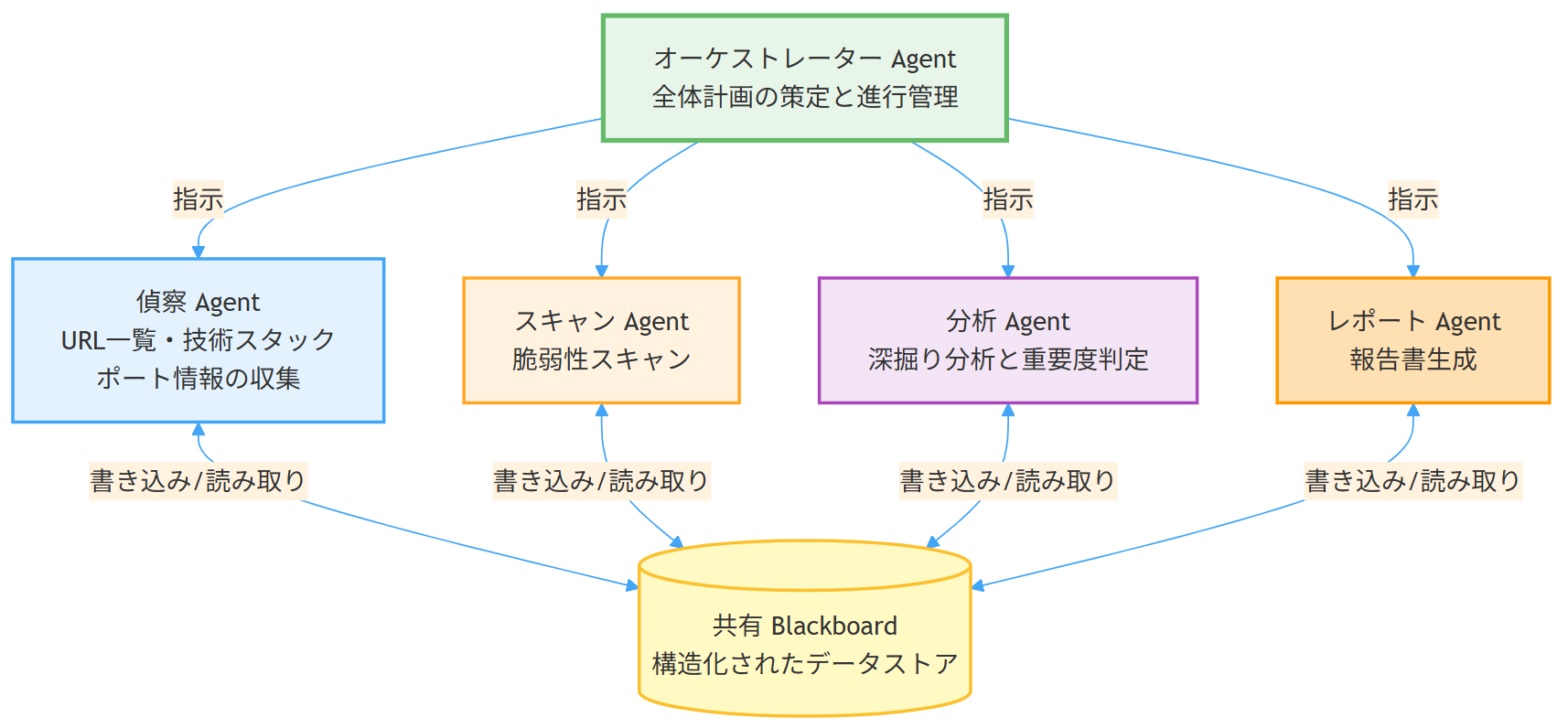
| エージェント | 役割 | 使用ツール例 |
| オーケストレーター | 全体計画の策定と進行管理 | (ツール不要。他エージェントの呼び出し) |
| 偵察 Agent | 対象のURL一覧、技術スタック、ポート情報の収集 | DNS解決、ポートスキャン、技術検出(Wappalyzer等) |
| スキャン Agent | 偵察結果に基づく脆弱性スキャン | HTTPヘッダー確認、SSL評価、リンク巡回 |
| 分析 Agent | スキャン結果の深掘り分析と重要度判定 | CVE検索、CWEマッピング |
| レポート Agent | 結果の整形と報告書生成 | Markdownレポート生成 |
これはあくまで理想的な構成イメージです。実際にはツール実行の信頼性やLLMの判断精度の問題があるため、段階的に自動化範囲を広げていくのが現実的なアプローチです。
6. セキュリティ診断エージェントのプロンプト設計
エージェントの設計パターンがわかったところで、LLMへの指示書にあたる プロンプト をどう書けば効果的か。Prompt Engineering Guide[9]を参考にしながら、セキュリティ診断に使えるテクニックを見ていきましょう。
6.1 Few-shot Prompting
LLMに「こういう形式で答えてほしい」というお手本を数例見せる手法です。出力フォーマットを揃えたい場合に非常に有効です。
以下は、セキュリティヘッダー診断結果のフォーマット例です。
### 例1
**ヘッダー**: Content-Security-Policy
**ステータス**: 未設定
**重要度**: Critical
**CWE**: CWE-693 (Protection Mechanism Failure)
**リスク**: CSPが未設定の場合、攻撃者はXSSペイロードを注入し、
任意のスクリプトを実行可能。フォームデータの窃取やセッション
ハイジャックにつながる。
**推奨設定**: `Content-Security-Policy: default-src 'self'; script-src 'self'`
### 例2
**ヘッダー**: Strict-Transport-Security
**ステータス**: 設定済み (max-age=31536000; includeSubDomains)
**重要度**: Info
**リスク**: 適切に設定されている。
**推奨設定**: 現行設定で問題なし。preloadの追加を検討してもよい。
---
上記の形式に従って、以下の診断結果を報告してください。Few-shotの例を2〜3個見せるだけで、LLMの出力品質が格段に安定します。特に重要度の判定基準を例で示すことで、CriticalとHighの境界線がLLMに伝わりやすくなります。逆に、このパターンを定義しないと、出力形式がLLM任せになってしまい思ったような出力が得られません。(内容が過剰だったりくどかったり)
6.2 Chain-of-Thought (CoT)
Chain-of-Thought は、LLMに「思考の過程」を段階的に出力させる手法です[9]。
以下のHTTPレスポンスヘッダーを分析してください。
分析にあたっては、以下のステップで思考過程を明示してください:
1. 各ヘッダーの設定値を読み取る
2. OWASPの推奨事項と照合する
3. 設定値が不適切な場合、具体的にどういう攻撃が成立するかを推論する
4. 攻撃の影響範囲と発生確率からリスクレベルを判定する
5. 修正案を提示する
ヘッダー情報:
x-frame-options: SAMEORIGIN
content-security-policy: (未設定)
strict-transport-security: max-age=86400「ステップバイステップで考えてください」と指示するだけでもある程度効果はありますが、セキュリティ分析に特化したステップを具体的に指定するほうが精度は高いです。特にHSTSの max-age=86400 のように「設定はあるが値が不十分」(推奨は31536000以上)というグレーゾーンの判定で、CoTの効果が出やすい印象があります。
6.3 ReAct Prompting
セクション4.1で解説したReActパターンをSystem Promptに直接埋め込む手法です。
あなたはセキュリティ診断エージェントです。
以下の形式で思考と行動を繰り返してください。
Thought: [現在の状況分析と次に取るべきアクション]
Action: [使用するツール名と引数]
Observation: [ツールの実行結果の考察]
... (Thought/Action/Observationを必要なだけ繰り返す)
Final Answer: [最終的な診断結果]
重要な制約:
- Observationに記載されていない情報を推測で補完しないこと
- 各Thoughtで、なぜそのActionを選んだかの理由を明記することReAct Promptingは、LLMに「考えてから行動する」習慣を強制するテンプレートです。制約条件(ステップ上限、推測の禁止)を明記することで、ハルシネーションの抑制にもつながります。
6.4 ペルソナ設定は効くのか?
「あなたは10年以上の経験を持つシニアセキュリティエンジニアです」といった ペルソナ設定 は効果があるのでしょうか。筆者も気になっていたので調べてみました。
結論から言うと、効果は不安定で過信は禁物です。
2024〜2025年にかけて複数の研究が報告されていますが、結果はまちまちです。Araujo et al.(2025)による27タスク×9モデルの大規模検証では、専門家ペルソナで最大37%の改善が見られたケースがある一方、22%のタスクでは性能が低下しました[10]。特に小規模モデルや、狭く特化したペルソナ設定では低下が顕著でした。
筆者の実感としても、ペルソナ(10年以上の経験や、優秀な~など)の有無よりも、役割を定義した文章や、先に紹介した Few-shot、CoT、構造化された指示 のほうが安定して品質に寄与します。ペルソナ設定を完全に否定するわけではありませんが、「ペルソナを書いたから大丈夫」ではなく、タスクの指示とフォーマット指定を丁寧にやるほうが投資対効果は高いです。
ただし、マルチエージェントにおける役割付与としてのペルソナは別です。CrewAIのAgent定義にroleを設定するように、複数エージェント間で役割を差別化するための手段としては有用です。これは「LLMの出力品質を上げるためのペルソナ」とは目的が違います。
7. コンテキストエンジニアリングとハーネスの基礎
ここまで、設計パターンやプロンプト技法を見てきました。しかしエージェントを実用レベルで安定させるには、もう一つ重要な概念があります。コンテキストエンジニアリングとハーネスです。
7.1 Prompt Engineeringの先へ
2025年、Andrej Karpathyが提唱したこの概念は、「プロンプトの書き方」よりも広い問題を扱います[2]。
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step."
(コンテキストエンジニアリングとは、次のステップに必要な情報だけでコンテキストウィンドウを満たすという、繊細な技芸と科学である。)
プロンプトエンジニアリングが「LLMへの指示をどう書くか」の話だとすれば、コンテキストエンジニアリングは「LLMのコンテキストウィンドウに何を・いつ・どれだけ入れるか」という、より上流の設計問題です。
7.2 LLMの知識ベースだけでは無理がある
LLMはトレーニングデータから膨大な知識を獲得していますが、その知識には限界があります。「AIチャット画面で少し違う回答をされた。」「古い情報を吐き出す」などの経験はありますか?LLM(大規模言語モデル)はその名の通り学習した知識を数千億個のパラメータ(重み)として保存しています。知識はどこか特定の場所に保存されているのではありません。入力に応じて、その重みの組み合わせが知識を「浮かび上がらせる」ようなイメージです。そのため、LLM単体では以下のような限界(制約)があります。
- 時間的な限界: トレーニングのカットオフ日以降の情報(最新CVEなど)は知らない
- 固有の限界: 開発中のプロジェクトのソースコードや設定ファイルは学習データに含まれていない
- 精度の限界: 学習データに含まれる情報でも、正確に再現できるとは限らない(ハルシネーション)
だからこそ、エージェントが適切に動作するためには、必要な情報をお膳立てしてコンテキストに投入することが不可欠です。RAGで外部知識を検索して注入する、ツールの実行結果を挿入する、過去の会話を要約して含める。すべてコンテキストエンジニアリングの一部です。
7.3 ゴミデータのリスク
「情報が多いほどいい」とは限りません。
2025年の研究では、コンテキストに無関係な情報が混在すると、LLMの精度が24.2%低下することが報告されています[11]。高性能なモデル(Claude 4.5 Sonnet、GPT-5.2など)はノイズに対して比較的ロバストですが、性能の低いモデルではゴミデータに引っ張られて間違った回答をするリスクが顕著に高まります。
コンテキストエンジニアリングは「何を入れるか」だけでなく、「何を入れないか」の設計でもあるわけです。
7.4 プロジェクトファイルを事前に作る理由
コンテキストエンジニアリングの具体的な実践例として、コーディングエージェント界隈で普及している「プロジェクトファイル」の仕組みを紹介します。
| ツール | ファイル名 | 内容 |
| Claude Code | CLAUDE.md | プロジェクト概要、技術スタック、コマンド、アーキテクチャ方針、コードスタイル。Claude Codeが起動時に自動読み込み[12] |
| Kilo Code / 各種ツール | AGENTS.md | 2025年5月に登場したオープン標準。Kilo Code、Cursor、Windsurf、GitHub Copilotなど多数のツールが対応[13]。Claude Codeも読み込みが可能 |
なぜわざわざ別ファイルに計画を書くのか。それは ハーネスの強化とコンテキスト汚染の防止 です。
コーディングエージェントは、計画(planning)→ 実装(coding)→ デバッグ(debugging)というフェーズを行き来します。もし全フェーズの情報がコンテキストに混在すると、LLMの「注意力」が分散します。計画を外部ファイルに切り出し、各フェーズの開始時に必要な部分だけを読み込むことで、コンテキストの注意力を維持する。これがCLAUDE.mdやAGENTS.mdの本質的な役割です。
セキュリティ診断エージェントでも同じ考え方が使えます。診断対象の情報、過去の診断結果、組織固有のポリシーなどを構造化されたファイルに整理し、必要なときに必要な分だけコンテキストに投入する。
7.5 ハーネス
コンテキストエンジニアリングの実践において、プロンプトやシステムプロンプトの設計だけでは解決できない課題があります。それは、AIモデルを長時間にわたるタスク実行において安定的にコントロールすることです。この課題に対するアプローチとして注目されているのが「エージェントハーネス」という概念です。
エージェントハーネスとは
エージェントハーネスとは、AIモデルを長時間にわたるタスク実行においてコントロールするための仕組みです。単一のプロンプトだけでなく、マルチエージェント構成、会話の管理、会話圧縮、エージェント間のハンドオフなど、複合的な要素を組み合わせた実行環境全体を指します。
この概念はAnthropicが大きく言及したことで広がりました。同社はCLAUDE.mdやAGENTS.mdといったドキュメントを通じてコンテキストエンジニアリングに挑戦し、タスクの完遂率を向上させました。しかし、長期間にわたるタスクにおいては依然として課題が見えています。目指すべきは、人間の介入なしに自律的に稼働し、出力を安定させるシステムです。
コンテキスト管理におけるハーネス
長時間のタスク実行では、コンテキストウィンドウが埋まり、情報の管理が困難になります。ハーネスはこの問題に対していくつかのアプローチを提供します。
会話圧縮
最も基本的な手法が会話圧縮です。コンテキストが溜まった際に、これまでの会話を要約し、新しいエージェントインスタンスに引き継ぎます。圧縮率は高いものの、情報の欠落が起こるというトレードオフがあります。
Claudeでは、コンテキストが一定量溜まると自動的に圧縮するメカニズムが実装されています。これにより、限られたコンテキストウィンドウを効率的に活用できます。
ゴミデータの削減
会話圧縮以外にも、ツールの実行結果を削除することでゴミデータを減らすアプローチがあります。前述の、メッセージの配列の中から重要でないツールの実行結果を排除することでコンテキストの節約になり安定動作が見込まれます。特に、大量のログや中間結果が生成されるタスクでは、必要な情報だけを保持し、不要な情報を積極的に削除することが重要です。
ハンドオフ
単純な要約ではなく、引継書を作成してエージェントに渡す「ハンドオフ」という手法もあります。これは要約よりも構造化された情報を次のエージェントに引き継ぐことで、情報の欠落を最小限に抑えます。
マルチエージェント下におけるハーネス
長時間タスクの安定性を高めるために、マルチエージェント構成を活用したハーネスも有効です。
自己フィードバックループ
単一のエージェントに自己フィードバックループを組み込み、これまでの成果と反省を踏まえて次のアクションを決定させるアプローチがあります。これにより、エージェントは自律的に軌道修正できます。
プランナー・評価者・ジェネレータ構成
Anthropicは長時間エージェントの実行アーキテクチャとして、プランナー・評価者・ジェネレータをマルチエージェントで立てる構成を提案しました。
- プランナー: タスク全体の計画を立案
- ジェネレータ: 計画に基づいて実際の作業を実行
- 評価者: ジェネレータの出力を定量評価可能な物差しで監視
この構成により、計画と実行を分離し、評価者エージェントがジェネレータを継続的に監視することで、タスクの質を保ちながら長時間の自律実行を実現します。
8. DeepResearchエージェントを作ってみる
理論はここまでにして、実践に入りましょう。前回はワンショットの診断エージェントでしたが、今回はマルチエージェントでのDeepResearchを実装します。Main Agent(全体計画+最終レポート)と coResearcher Agent(個別の検索・要約)の2エージェント構成です。
DeepResearchを作る意味:LLMの知識のみでは調査研究タスクをこなすには限界があります。人間がするのと同様に検索を行い、検索結果をコンテキストとしてLLMの能力として洞察を引き出す。システムプロンプトの設計・ToolCallingの設定・コンテキストエンジニアリング・マルチエージェントの練習を一気に行える最適なテーマだからです。
※Mastra 他に細かい設定コードなども必要ですが主要なコードのみ掲載します。実際に動作させるにはMastraドキュメントを見ながらセットアップして下さい。また、僅かなバージョン違いでも文法・スキーマが異なるケースがあるのでご注意下さい
8.1 設計概要

処理の流れはこうです。
- ユーザーが調査テーマを入力(例: 「CVE-2024-XXXX の影響範囲と対策状況」)
- Main Agent がテーマを分析し、調査すべきサブクエリを生成
- coResearcher Agent が各サブクエリに対してWeb検索を実行し、結果を要約
- Main Agent が中間結果を評価し、追加調査が必要ならサブクエリを追加
- 十分な情報が集まったら、Main Agent が最終レポートを生成
検索エンジンには Tavily を使います。TavilyはAIエージェント向けのWeb検索APIで、検索結果をLLMが処理しやすい構造化されたテキストとして返してくれます[14]。検索するにはAPIキーが必要ですので、事前に取得して下さい。
8.2 ツール定義
(src/mastra/tools/tavily-search.ts)
import { createTool } from "@mastra/core/tools";
import { z } from "zod";
import { tavily } from "@tavily/core";
const tavilyClient = tavily({ apiKey: process.env.TAVILY_API_KEY! });
export const webSearchTool = createTool({
id: "web-search",
description:
"Web検索を実行し、指定したクエリに関連する最新情報を取得する。" +
"セキュリティの脆弱性情報、技術ドキュメント、ニュース記事などの" +
"調査に使用する。",
inputSchema: z.object({
query: z.string().describe("検索クエリ。具体的で明確な検索語句"),
maxResults: z.number().default(5).describe("取得する検索結果の最大数"),
}),
outputSchema: z.object({
results: z.array(
z.object({
title: z.string(),
url: z.string(),
content: z.string(),
})
),
}),
execute: async ({ context }) => {
const response = await tavilyClient.search(context.query, {
maxResults: context.maxResults,
searchDepth: "advanced",
});
return {
results: response.results.map((r) => ({
title: r.title,
url: r.url,
content: r.content,
})),
};
},
});8.3 エージェント定義
(src/mastra/agents/deep-research.ts)
import { Agent } from "@mastra/core/agent";
import { Memory } from "@mastra/memory";
import { LibSQLStore } from "@mastra/libsql";
import { webSearchTool } from "../tools/tavily-search";
// ----- coResearcher Agent -----
// 個別の検索クエリを実行し、結果を要約する専門エージェント
export const coResearcherAgent = new Agent({
name: "coResearcher",
instructions: `あなたは調査専門のリサーチアシスタントです。
<task>
与えられた検索クエリに対して、web-searchツールで情報を収集し、
以下の形式で要約してください。
</task>
<output_format>
## 調査結果: [クエリ内容]
**情報源**: [URL一覧]
**要約**: [200-400文字の要約]
**信頼度**: [高/中/低](情報源の質に基づく判定)
**追加調査の示唆**: [さらに調べるべきポイントがあれば記載]
</output_format>
<constraints>
- 検索結果に含まれない情報を推測で補完しない
- 情報源のURLを必ず明記する
- 矛盾する情報がある場合は両方を併記し、矛盾を明示する
</constraints>`,
// coResearchでは小さな調査タスクを担うので小規模モデルを選んでもよい。コスト削減・時間短縮の効果がある
model: "openrouter/anthropic/claude-haiku-4.5",
tools: { webSearchTool },
});
// ----- Main Agent -----
// 調査の全体計画を立て、coResearcherの結果を統合するオーケストレーター
export const mainResearchAgent = new Agent({
name: "MainResearcher",
instructions: `あなたはセキュリティリサーチのオーケストレーターです。
<task>
ユーザーから調査テーマを受け取り、以下のプロセスで深掘り調査を行います。
1. テーマを分析し、3〜5個の具体的な検索サブクエリを生成する
2. coResearcherに各サブクエリの調査を依頼する
3. 中間結果を評価し、不足があれば追加サブクエリを生成する
4. 十分な情報が集まったら、最終レポートを生成する
</task>
<report_format>
# 調査レポート: [テーマ]
## エグゼクティブサマリー
[3-5行の概要]
## 詳細調査結果
### [サブトピック1]
...
### [サブトピック2]
...
## 結論と推奨事項
## 参考情報源
</report_format>
<constraints>
- サブクエリの総数は最大10個とする
- 各サブクエリは具体的で検索エンジンに適した形にする
- 最終レポートでは、情報の出典を明記する
</constraints>`,
// オーケストレーションを担うエージェントは比較的高性能なモデルが望ましい
model: "openrouter/anthropic/claude-sonnet-4.6",
tools: { webSearchTool }, // Main Agent自身も検索可能
memory: new Memory({
storage: new LibSQLStore({
url: "file:research-memory.db",
}),
}),
});8.4 Workflowによるオーケストレーション
シンプルにAgentにAgentを連携させて能動的に呼び出しでも良いのですが今回はWorkflowで
(src/mastra/workflows/deep-research-workflow.ts)
import { Workflow } from "@mastra/core/workflows";
import { z } from "zod";
import { mainResearchAgent, coResearcherAgent } from "../agents/deep-research";
export const deepResearchWorkflow = new Workflow({
name: "deep-research",
triggerSchema: z.object({
topic: z.string().describe("調査テーマ"),
}),
})
// Step 1: Main Agent がサブクエリを生成
.then("plan", async ({ inputData }) => {
const result = await mainResearchAgent.generate(
`以下のテーマについて調査計画を立ててください。
3〜5個の検索サブクエリをJSON配列で出力してください。
テーマ: ${inputData.topic}`
);
// LLMの出力からサブクエリ配列をパースする
const queries = JSON.parse(
result.text.match(/\[[\s\S]*\]/)?.[0] || "[]"
);
return { queries, topic: inputData.topic };
})
// Step 2: coResearcher が各サブクエリを並列で調査
.then("research", async ({ inputData }) => {
const results = await Promise.all(
inputData.queries.map(async (query: string) => {
const result = await coResearcherAgent.generate(
`以下のクエリについて調査してください: ${query}`
);
return { query, summary: result.text };
})
);
return {
topic: inputData.topic,
researchResults: results,
};
})
// Step 3: Main Agent が結果を統合してレポート生成
.then("report", async ({ inputData }) => {
const researchContext = inputData.researchResults
.map(
(r: { query: string; summary: string }) =>
`### ${r.query}\n${r.summary}`
)
.join("\n\n");
const report = await mainResearchAgent.generate(
`以下の調査結果を統合して、最終レポートを生成してください。
テーマ: ${inputData.topic}
調査結果:
${researchContext}`
);
return { report: report.text };
})
.commit();概念コードのため細部は省略していますが、ポイントは以下の通りです。
- Workflow で処理の流れを宣言的に定義。
.then()でステップを連結 - Step 2で並列実行。
Promise.allで複数のcoResearcherを同時に走らせる - Main Agent は計画(Step 1)とレポート統合(Step 3)に専念し、検索の実務はcoResearcherに委任
8.5 Memory Processorによるコンテキスト圧縮
長い調査セッションではコンテキストが膨らみます。Mastra 1.0 の Memory Processorを使うと、古いメッセージを自動で圧縮できます[1]。
import { Memory } from "@mastra/memory";
import { LibSQLStore } from "@mastra/libsql";
const memory = new Memory({
storage: new LibSQLStore({
url: "file:research-memory.db",
}),
// Observational Memory を有効化
// Observer: 会話の重要事項を「観察」として記録
// Reflector: 観察が溜まったら整理・圧縮
observationalMemory: {
enabled: true,
observerThreshold: 30_000, // 30Kトークンで観察開始
reflectorThreshold: 40_000, // 40Kトークンで整理開始
},
});従来のCompaction(一括要約)との違いは、Observational Memoryがイベントベースの追記ログである点です。「何が起きて、何が決まったか」を日付付きの観察事項として記録し、全文要約のような情報損失を避けます。MastraはLongMemEvalベンチマークで94.87%(gpt-5-mini使用時)を達成しています[1]。
9. まとめ ─ そして次回へ
今回はかなり盛りだくさんの内容になりました。振り返ると、
- LLMのチャットは 4つのroleを持つメッセージ配列 でやり取りされている
- コンテキストウィンドウ がRAMのような制約として存在し、溢れるとエージェントが壊れる
- エージェントの設計パターンには ReAct / Plan-and-Execute / Reflexion / LATS がある
- マルチエージェントでは オーケストレーター型 がセキュリティ診断と相性が良い
- プロンプト技法は Few-shot / CoT / ReAct Prompting を組み合わせて使う。ペルソナは過信しない
- コンテキストエンジニアリング = LLMに「何を・いつ・どれだけ」見せるかの設計
- モデルによってToolCall耐性が大きく異なる。複雑なタスクほど高性能モデルが必要
前回「LLMはテキストを生成しているだけ」と書きましたが、その「テキスト生成」を安定させて実務に使えるレベルにするには、設計パターン、プロンプト技法、コンテキスト管理、モデル選定…… やることが山のようにあります。エージェント開発は「LLMにプロンプトを投げて終わり」では到底済まないのが現実です。
しかし、今回のDeepResearch実装でも課題は残ります。エージェントは過去の調査結果を覚えていないという問題です。「先月調べたCVE-2024-XXXXの情報を踏まえて…」と言われても、前のセッションの情報は消えています。Observational Memoryでセッション内の圧縮は対処できますが、セッションを跨いだ長期的な記憶はまた別の問題です。
さらに、LLMの学習データに含まれない最新のCVE情報や、組織固有のセキュリティポリシーをどうやってエージェントに「教える」かという課題も残っています。
次回は 記憶管理(Memory) と RAG(Retrieval-Augmented Generation) に踏み込みます。LLMに"長期記憶"を与え、外部知識ベース(CVE、CWE、OWASP)と接続する技術。エージェントが「経験から学ぶ」存在になるための基盤技術です。
今回はここまで。
参考文献
[1]: Mastra, "Announcing Observational Memory", Mastra Blog, Feb 2026. https://mastra.ai/blog/observational-memory 、Mastra Research, "Observational Memory: 95% on LongMemEval". https://mastra.ai/research/observational-memory
[2]: Karpathy, A., Context Engineering Discussion, 2025. LangChain Blog, "Context Engineering for Agents". https://blog.langchain.com/context-engineering-for-agents/
[3]: AG2 Documentation. https://docs.ag2.ai/latest/docs/home/quickstart/ 、AG2 GitHub Repository. https://github.com/ag2ai/ag2
[4]: CrewAI GitHub Repository. https://github.com/crewAIInc/crewAI 、CrewAI Documentation. https://docs.crewai.com/
[5]: Yao, S., et al., "ReAct: Synergizing Reasoning and Acting in Language Models", ICLR 2023. arXiv:2210.03629
[6]: LangChain Blog, "Plan-and-Execute Agents". https://blog.langchain.com/planning-agents/ 、Wang, L., et al., "Plan-and-Solve Prompting", ACL 2023. Nakajima, Y., "BabyAGI", 2023.
[7]: Shinn, N., et al., "Reflexion: Language Agents with Verbal Reinforcement Learning", NeurIPS 2023. arXiv:2303.11366
[8]: Zhou, A., et al., "Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models", ICML 2024. arXiv:2310.04406
[9]: DAIR.AI, Prompt Engineering Guide. https://www.promptingguide.ai/jp
[10]: Araujo, et al., "Expert Persona Prompting", 2025. 27タスク×9モデルの大規模検証。Emergent Mind, https://www.emergentmind.com/topics/expert-persona-prompting
[11]: Glean, "Context engineering vs. prompt engineering", 2025. 「LLM accuracy drops by 24.2% when relevant information is embedded within longer contexts」. https://www.glean.com/perspectives/context-engineering-vs-prompt-engineering-key-differences-explained
[12]: Dometrain, "Creating the Perfect CLAUDE.md for Claude Code". https://dometrain.com/blog/creating-the-perfect-claudemd-for-claude-code/
[13]: Socket.dev, "AGENTS.md Gains Traction as an Open Format for AI Coding Agents". https://socket.dev/blog/agents-md-gains-traction-as-an-open-format-for-ai-coding-agents 、Kilo Code Docs, "Agents.md". https://kilo.ai/docs/customize/agents-md
[14]: Tavily - The Web Access Layer for AI Agents. https://tavily.com/
※本記事は2026年3月時点の情報に基づいています。LLMとAIエージェントの分野は日進月歩であり、公開時点で状況が変わっている可能性があります。技術的な正確性については、必ず一次情報をご確認ください。
おすすめ記事


