本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。

AI for security を真剣に考えるために学ぶ、LLMの現在と基礎
1. はじめに
2025年6月、セキュリティ業界にとあるニュースがでました。LLMを搭載した自律型ペネトレーションテストツール XBOW が、世界最大のバグバウンティプラットフォーム HackerOne の米国リーダーボードで #1 を獲得したというニュースです。[1] これまで、壁打ち相手としての活用が多く、セキュリティ業務へAIを取り込む試みや研究は行われてきましたが、XBOWは大きなインパクトを背負って登場したなと記憶しています。
2023年に弊社の寺田による記事 ChatGPTで脆弱性を探す でペイロード生成を検討していましたが更にステージが進んだと言ってもよいでしょう。
「AIエージェントは、セキュリティ診断のワークフローをどこまで自動化できるのか?」
筆者自身、日頃はWebアプリケーションの脆弱性診断に従事しています。2024年後半からLLMを診断業務に取り入れる試みを続けてきた中で見えてきた可能性を、ざっくりとお伝えできればと思います。今回の記事ではLLMの2026年現在の状況と基礎的な知識をお届けします。より正確な情報や最新の情報は読者の皆さまでキャッチアップをお願い致します。
2. LLMの基礎 ─ なぜ大規模言語モデルがセキュリティ業務に使われるのか
2.1 Transformerアーキテクチャ
現在のAIエージェントの「頭脳」にあたるLLM(Large Language Model)は、ほぼすべてが Transformer アーキテクチャに基づいています。2017年にGoogleの研究チームが発表した論文 "Attention Is All You Need"(超かっこいい)[2] が起源です。
Transformerの注目点は Self-Attention(自己注意機構) です。入力されたテキスト(トークン列)の中で、各トークンが他のすべてのトークンとの関連度を計算し、文脈に応じて重要な情報に「注意」を集中させます。
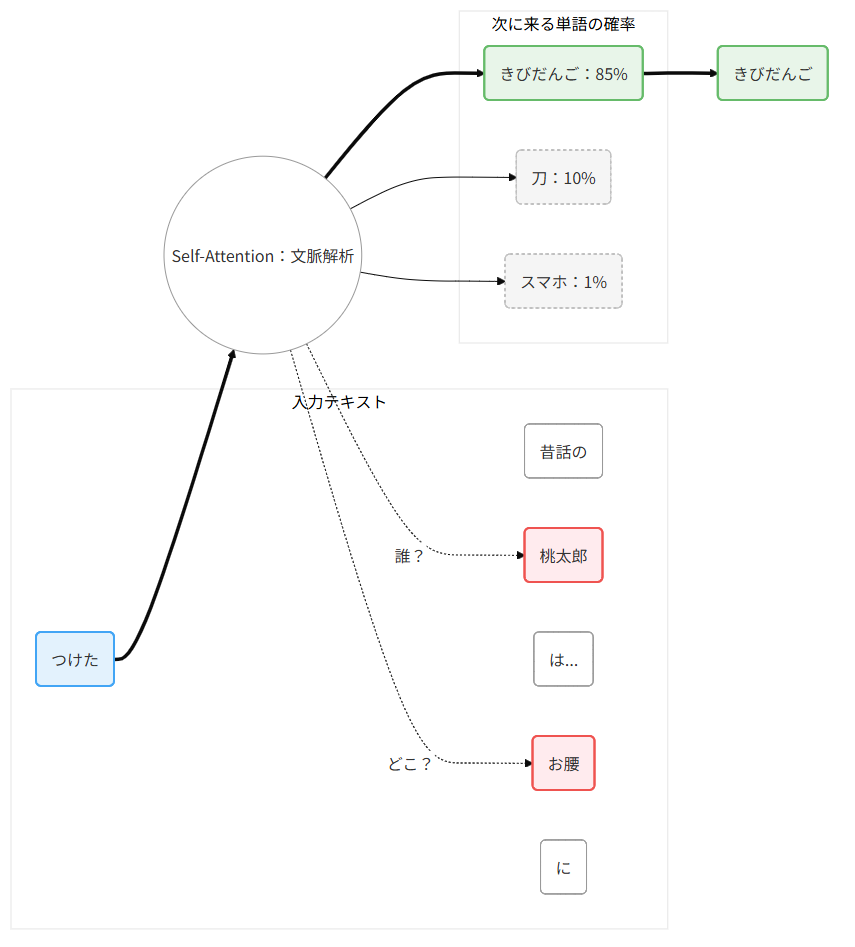
この仕組みにより、LLMは単なるパターンマッチではなく、文脈を理解したように見える推論 が可能になります。従来のパターンマッチの脆弱性検知との決定的な違いがここにあります。
2026年現在の主要モデルは、数千億〜数兆パラメータ規模に達し、2023年時点では課題だったコンテキストウインドウも、数千だったのが現在では数十万(100K~200K)トークンのコンテキストウィンドウを持ちます。これは、それなりの規模のプロジェクトにおける複数ソースコードを「読み込んで」分析できることを意味します。
膨大な脆弱性パターンの学習済み知識
学習データにはCVEデータベース、セキュリティアドバイザリ、Exploit-DB、CTFのWrite-up、OWASPのドキュメントなど、膨大なセキュリティ知識がトレーニングデータに含まれています。
そのため、従来の自動スキャナは事前に定義されたルールに従うだけですが、LLMは対象アプリケーションの文脈を解析し、その場で推論を行います。「このパラメータ名は redirect_url だからオープンリダイレクトの可能性がある」「このAPIは認証トークンを返しているがレート制限がない」といった 文脈に基づく仮説生成 が可能です。
3. 2026年のLLM勢力図
どのLLMを使えばよいというわけではありません。LLMは開発元やプロバイダによって特徴や性能、価格が異なりますし、新興勢力の追い上げなどもあります。2026年2月現在のLLM勢力図を俯瞰しましょう。
3.1 米国プロプライエタリ陣営
| プロバイダ | モデル名 | 特徴 |
価格(i/o per 1M tokens) |
| OpenAI | GPT5.2, GPT5.3-Codex | LLMブーム火付け役。動画生成なども。Microsoft連携 |
$2.50 / $10.00 (GPT-5.2) |
| Anthropic | Claude 4.6 Opus / 4.5 Sonnet | エージェント性能が高い。Claude Codeや MCPサーバーなど先進的なプロダクトの提案 |
$5.00 / $25.00 (Opus 4.6) |
| Gemini 3 Pro /Flash | Googleサービス連携に強い。独自開発のTPUで価格を抑えレスポンスも早い |
$2.00 / $12.00 (Pro) |
|
| xAI | Grok 4 | x.com(twitter)のテキストを学習。画像生成など色々物議を醸すが、コード生成特化の格安モデルなどもある。 |
$3.00 / $15.00 (Grok4) |
a16zの調査によれば、2025年のエンタープライズLLM支出は平均 $7M(前年比180%増)に達し、2026年は $11.6M に到達する見込みです[3]。
市場シェアではOpenAIが依然最大(2026年予測で53%)ですが、縮小傾向にあります。一方で Anthropicの最上位モデル利用率:顧客の75%が本番環境で最上位モデルを使用しており、OpenAIの46%を大きく上回っています[3]。
3.2 中国オープンウェイト陣営
2025年は、中国発のオープンウェイトモデルが 劇的に台頭 した年でした。DeepSeek-R1が国内ではニュースになりましたが、それ以外にも性能の高いモデルが数多く登場しています。
| 開発元 | モデル名 | 特徴 |
スペック(総パラメータ数 / コンテキスト長) |
| DeepSeek | DeepSeek-R1 / V3.2 | 低コストトレーニング。中国オープンウェエイトLLMの火付け役 |
671B / 128K |
| Alibaba | Qwen 3 | 様々な規模/用途のモデルをリリース(TTS/ Embeddings/ Rerankerなども) |
235B / 128K(拡張可能) |
| Moonshot AI | Kimi K 2.5 | オープンウェイト初の1Tパラメータ。エージェント性能を重視 |
1T(1000B) / 256K |
| Z.AI (Zhipu) | GLM-5 | 規模に対する性能が高い。4.5以降の性能向上に注目が集まっている |
774B / 200K |
| MiniMax | M2 / M2.5 | 更に小規模ながらも高速動作。コスパをアピール日本語性能は高くない。 |
229B / 200K |
※スペックのパラメータ数は代表的なモデルを掲載、またMoEのようなエキスパートによる実際に動作するアクティブパラメータ数は記載していません。
特に最近では Kimi K2.5のAgent Swarm技術 の発表により勢い付いています。最大100の特化エージェントを同時並行で実行し、実行時間を4.5倍短縮するという報告があります[5]。ペネトレーションテストの並列実行との相性が気になりますね。
3.3 EU・オープンソース陣営
| 開発元 | モデル名 | 特徴 |
スペック(総パラメータ数 / コンテキスト長) |
| Mistral | 3 Large | フランスのAIスタートアップ企業。最新の 3 Large は低価格で利用できる |
675B / 256K |
| Meta | Llama 3.3 / 4 Maverick | オープンウェイトの火付け役。Llama3.3をベースにした派生モデルも多く出回った。Llama 4 は 10Mトークンという長大トークンに対応。 |
400B / 10M (4 Maverick) |
| OpenAI | gpt-oss | GPT-2以来、約6年ぶりにリリースしたオープンウェイトモデル。軽量で高速に動作する。 |
120B / 128K |
Meta社のLlamaシリーズはかつては非常に注目されていましたが、最新の4では、トレンドとして求められていた、マルチモーダル性能、ToolCall性能、Agentic性能などが振るわず、あまり注目されなくなってしまいました。Mistral AIは最新のフラッグシップ Mistral 3 に DeepSeek V3のアーキテクチャ(DSA)を採用 するなど、中国モデルの技術的影響力は無視できないレベルに達しています。
以下の画像は OpenRouterと呼ばれる、世界中のLLMプロバイダをプロキシして様々なモデルが利用できるサービスです。ユーザーがどのような目的で、どのモデルをよく使うかをRankingページでレポート(2026年2月11日)しています。
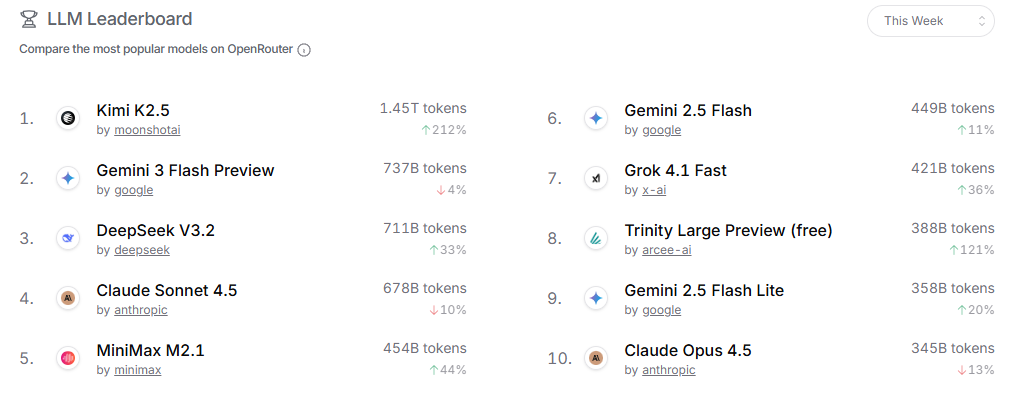
総合的な人気度で言えば、Moonshot AI のKimi K2.5がトップクラスに人気です。Google, OpenAI, Anthropicは定番ですが、 DeepSeekや MiniMaxも台頭しています。
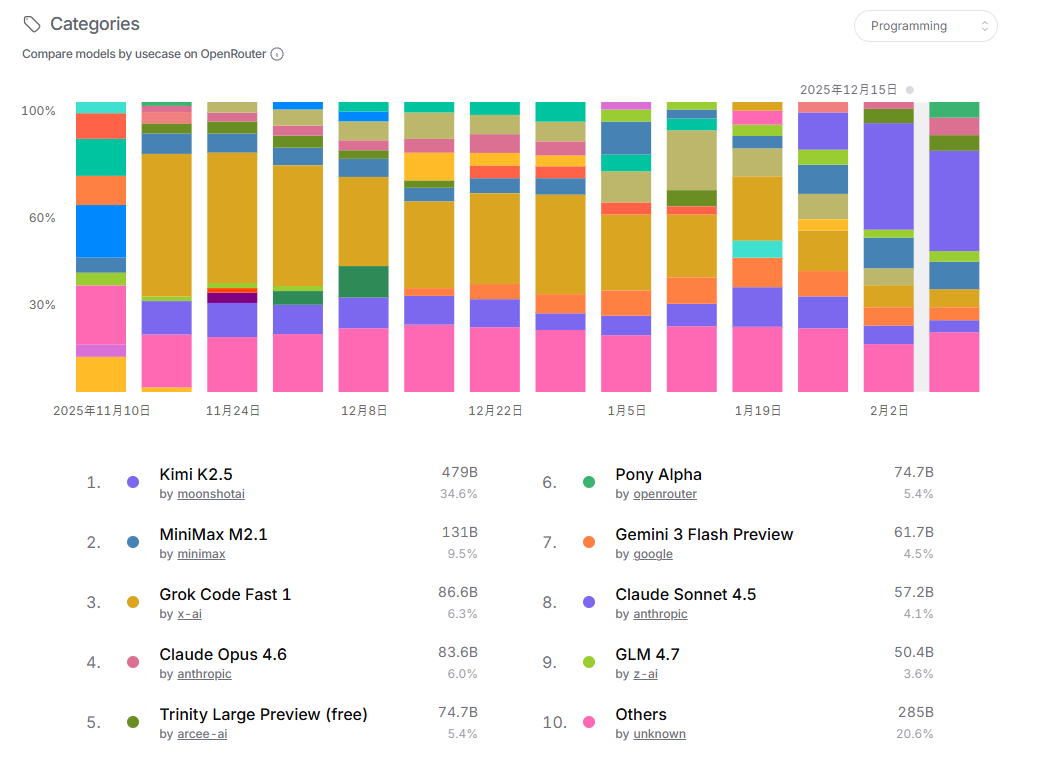
このランキングはプログラミング用途でのモデル人気ランキングです。ここでもKimi K2.5が一番人気です。コーディング性能は Claudeが非常に品質がよいのですが、コストもかかるため、より安くそれなりに成果物の品質が良いモデルが選ばれがちです。
3.4 Reasoning Modelという潮流
2025年前半から、推論(Reasoning)特化モデル が急速に台頭しました。「深く思考しています」といったダイアログを見たことがありますか?これはユーザに回答を生成する前にLLM自身で Reasoning することで回答内容の性能や品質上げる試みです。Reasoningによって数学などの複雑な問題が解けるようになってきました。
思考モデルとも言われていたりしましたが、別に思考しているわけではありません。従来のLLMはUser Prompt(ユーザの入力)に対してなにか応答を返すという仕組みです。普通の対話なら良いですが、数学など複雑な思考過程が必要な問題に対してワンショットで答えられないという問題がありました。そのため、モデルのトレーニング時に、<think></think>という出力領域を新設し、「この問題はまず、○○をして、次にXXを行ったうえで、ZZを~~」といった思考過程の文章をトレーニングさせています。自分自身で文脈を増やして推論能力を上げようという試みです。数学に強いといいますが実際に計算をしているわけではないのです。(推論のための計算はしていますが)
3.5 2026年後半の展望
ここでは触れませんがLLMを動作させるためのDRAM不足が発生したりなど、ブームが強すぎて経済的な影響が出てきています。今後より大きなモデルは登場するとは思いますが、推論のための計算コストを意識したアーキテクチャや、ハードウェア構成(キオクシアのHBFなど)の発展が考えられます。
また、それまでLLMの性能が上がることがそのまま価値となっていた時代は終わり、「LLM(エージェント)で何ができるか。何の価値提供ができるか」が求められるフェーズに入っています。LLMそのもののトレンドで言えば、ツール利用性能やコーディング性能を向上させるほか、マネタイズ分野ではAgent Swarmや Claude coWorkなど汎用的なマルチエージェントシステムが登場してきています。
【コラム】LLMは図を描けない
AIといえば画像生成も欠かせませんが、ここで言う図とは、SVG画像のことです。 SVG画像はXMLで構成されたベクター画像のことです。LLMでパワーポイント資料などを作っているときに、「ここに世界地図が欲しいから描いて」と命令したとします。ここでSVG画像を書き出すとうまく行きません。
LLMの仕組みを思い出しましょう。これまでのトークンを踏まえて次のトークンを推測することが基本動作です。SVG画像はXMLなので、描画結果をLLMが考えながら生成するわけではありません。そのためSVG画像を生成するのは高級なLLMであっても高難易度です。その代わり、LLMで図を書く場合はMarkdownによるテーブル、またはMermaidによる遷移図などの相性が良いです。個人的には、SVG編集とプレビュー機能、pathやfillの状態をガイドできる機能をLLMのツールとして連携し、マルチターンで試行錯誤させればそれなりの図はできるのではないかとは思います。あくまでワンショットで作成させること、SVGを使った作図は苦手な傾向にあり工夫が必要ということです。
4. 「エージェント」とは何か ─ チャットボットとの違い
LLMの勢力状況がわかったところで、現在のトレンドは「AIエージェント」です。「AIエージェント」とは何なのか、ChatGPTのようなチャットボットと何が違うのか、正確に理解しておく必要があります。
4.1 自律性のレベル分類
チャットボットとエージェントの違いは 「自律性」 に尽きます。エージェントと言っても様々でいくつかのタイプに分類できます。
- ツール実行エージェント(単発でのツール呼び出し)
- シングルエージェント(マルチステップで、複数のツールを呼び出す)
- マルチエージェント(複数のLLMが、マルチステップで、複数のツールを呼び出す)
- 大規模エージェント(Agent Swarm。10~100のサブタスクに別れて並列でこなす)
LLMによるセキュリティ診断の自動化に関する研究が活発になったのは、マルチエージェント が実用的になってきたことが大きな理由です。重要なのは、エージェントが 「計画し、実行し、結果を観測し、戦略を修正する」ループ を自律的に回せるかどうかです。
4.2 2026年を代表するAIエージェントたち
Claude Code
Anthropicの Claude Code は、2025年5月のClaude 4ローンチと同時にコーディングエージェントとしてリリースされました。Claude Codeの特徴は ターミナルネイティブ であることです。当時のCursorやRooCodeなど、VSCode上で読み込むプラグインなどで動作するものではなく、CLIから直接プロジェクトディレクトリにアクセスし、コードベース全体を理解した上で、マルチステップのタスクを計画・実行します。その話題性と人気は凄まじく、わずか6ヶ月で$1B ARR(年間経常収益)を達成しました[6]。Claude Codeに触発されて、GoogleはGemini CLIを、オープンソースでは OpenCodeが登場しました。
面白いのが、Anthropicの社内では、Claude Codeのコードの約90%がClaude Code自身によって書かれているという事実が象徴的です[7]。
2026年に入り、Anthropicは Claude Cowork をリリース。開発者以外の一般ユーザー向けにエージェンティック機能を拡張しています。
OpenCode ─ オープンソースの対抗馬
OpenCodeは、Go製のオープンソースAIコーディングエージェントです[8]。プロバイダ非依存(OpenAI、Anthropic、ローカルモデル等に対応)が最大の強みです。
LSP(Language Server Protocol)統合による高精度なコード理解、Plan/Buildモードの切り替え、MCP対応など、Claude Codeに迫る機能群を持ちます。セキュリティ観点では、ローカルモデルとの組み合わせ によって機密コードを外部に送信せずに診断できる点が魅力です。
5. Function Calling(Tool Calling)の仕組み
エージェントの自律性を支える最も基本的な技術が Function Calling(Tool Calling) です。ここではその仕組みを簡単に理解しましょう。
5.1 LLMは「テキストを生成しているだけ」
まず、(原則)LLMは一切のAPI呼び出しや外部操作を行いません。LLMがやっていることは、関数呼び出しの構造化データを テキストとして生成 しているだけです[9]。

Function Calling の手続きを担うのは、エージェントフレームワーク(Mastra、LangGraph、CrewAI等)の役割であり、LLMの「テキスト出力」を解析して実際のAPI呼び出しに変換します。この部分は従来のプログラミングと全く変わりません。
ツール定義は以下のような構造化スキーマとしてLLMに渡されます:
{"name": "check_security_headers","description": "指定URLのHTTPレスポンスヘッダーを取得し、セキュリティ関連ヘッダーの有無を調べる","parameters": {"type": "object","properties": {"url": {"type": "string","description": "調査対象のURL"}},"required": ["url"]}}
LLMはこのスキーマを 文脈として受け取り 、ユーザーの要求に応じて適切な関数呼び出しを「テキストとして」生成します。なお、"Function Calling" と "Tool Calling" は実質的に同義で使われますが、後者がより広義の用語です(組み込み検索やRetrievalなども含む)[9]。
5.2 マルチステップ実行 ─ エージェントループの構造
ここがチャットボットとエージェントを分ける最大のポイントです。エージェントは 単発の関数呼び出しで終わらず、ループを回します。
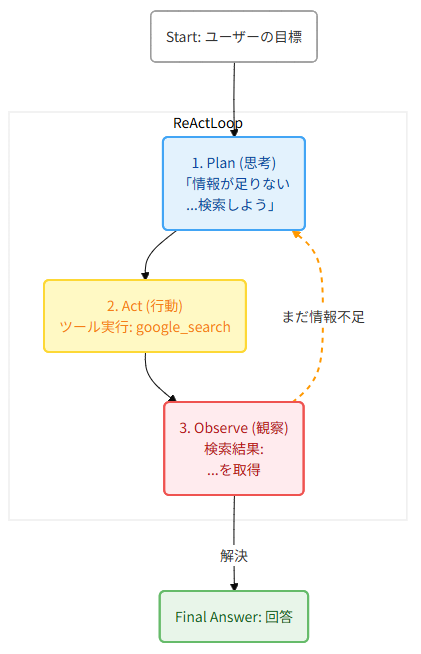
この Plan → Act → Observe のサイクルが、研究では ReAct(Reasoning + Acting)パターンと呼ばれます[10]。エージェントはこのループを 自律的に 回し、発見した情報に基づいて次のアクションを動的に決定します。
Kimi K2 Thinking では、このループが 200〜300回の連続ツール呼び出し を人間の介入なしで実行できると報告されています[11]。
ただ筆者の環境では、一定のコンテキストが溜まると、tool calling の手続きが崩壊してしまい長時間タスクが止まってしまう事象が発生しています。モデルの問題かAPIの問題か不明ですが現在はCalude が最も安定してエージェント実行できる印象です。
5.3 MCP(Model Context Protocol) ─ ツール接続の標準化
2025年にAnthropicが提唱した MCP(Model Context Protocol) は、Linux Foundationに移管され、ツールとデータへのアクセスを標準化するプロトコルとして急速に普及しました[4]。MCPの役割は「ツール接続のUSB-C」です。以前は各IDE・各ベンダーごとに個別のプラグイン統合が必要でしたが、MCPに準拠したツールは、MCPに対応する任意のエージェントから利用できます。ここでは簡単にツール連携ができるという認識で大丈夫です。
なお、MCPサーバーは、PythonまたはNode.js のパッケージマネージャーから直接起動する仕組みを取ることが多いです。npmやuvです。MCPサーバーを使いたい人は、npmレジストリから直接リポジトリを指定して起動するので、悪意のあるMCPサーバだったり、MCPサーバーとMCPクライアントの通信部分(JSONRPC等)の侵害など、AIを使う側としてのセキュリティも今後重要になってきます。
6. セキュリティ適用事例 ─ 研究最前線
6.1 研究事例
学術・研究コミュニティでも、LLMを活用したペネトレーションテストの自動化は急速に進展しています。主要な研究を整理します。
| ツール/論文名 | 発表年 | カテゴリ | 主な特徴(100文字以内) |
|---|---|---|---|
| PentestGPT | 2024 | 3モジュール自己相互作用型 | 3つの自己相互作用モジュール(Task/Reasoning/Parsing)で構成。LLMの知識を活用し、コンテキスト損失を抑えつつ偵察から攻撃までを自律実行。USENIX 2024で受賞。 |
| CAI | 2024 | モジュール式エージェント構成 | Alias Robotics開発のオープンソース・フレームワーク。モジュール式エージェントを採用し、バグバウンティやIoT機器のセキュリティ診断を追跡可能かつ軽量に自動化する。 |
| PentestAgent | 2024 | RAG統合型LLMエージェント | RAG(検索拡張生成)を統合したLLMエージェント。外部の知識ベースを参照することで、LLM単体では不足しがちな最新の脆弱性情報や攻撃手法を補完し、診断精度を向上させる。 |
| CheckMate | 2025 | 古典的プランニング統合型 | 古典的プランニング(HTN等)とLLMを統合したハイブリッド構成。構造化されたプランニングを「外部の脳」として利用し、LLMの幻覚を抑制しながら論理的で正確な攻撃手順を生成する。 |
| MAPTA | 2025 | マルチエージェント(Web特化) | ウェブ診断特化のマルチエージェント構成。オーケストレーター、実行エージェント、検証エージェントが連携し、サンドボックス環境でのツール実行とエクスプロイトの自動検証を組み合わせ、高い信頼性で脆弱性を特定。 |
| VulnBot | 2025 | 協調型マルチエージェント | 人間のテスターの協調ワークフローを模倣したマルチエージェント構成。複数の専門エージェントが情報共有と役割分担を行い、偵察から権限昇格までの一連のプロセスを自律的に完結させる。 |
| CurriculumPT | 2024 | カリキュラム学習型 | カリキュラム学習(段階的タスク管理)を採用したマルチエージェント構成。簡単なタスクから順次実行するスケジューリングにより、複雑なネットワーク環境下での診断成功率を大幅に向上させる。 |
| HackSynth | 2024 | 自律型・評価統合型 | 自律型エージェントと評価フレームワークの統合構成。LLMによる自律的な侵入テストの実行能力に加え、その性能を定量的に測定・分析する体系的な評価手法を提供することに重点を置く。 |
特筆すべきは CheckMate のアプローチです。LLMの「長期計画が苦手」という弱点を古典的AIプランニング(PDDL等)で補完する 設計 は、セキュリティエージェントだけでなくコーディングエージェントなどの様々なプロジェクトで採用され始めています。LLMは「実行と解釈」に特化させ、「計画」は別のシステムに委ねるという役割分担です。計画は実働部隊の文脈(コンテキスト)として使われるわけです。
7. Mastraでカンタンなセキュリティ診断エージェントを作ってみよう!
ここでは理論を実践に移します。TypeScriptベースのエージェントフレームワーク Mastra を使って、簡単なセキュリティ診断エージェントを実装してみましょう。
7.1 Mastraとは
Mastra[12] は、TypeScript のAIエージェントフレームワークです。
LangchainやAutoGenなどの有名なツールもありますが、ツールやMCP連携がしやすいのでよく使います。今回はこれを使用していきたいと思います。
主な特徴:
- Agents: LLMとツールを組み合わせた自律型エージェント
- Workflows:
.then(),.branch(),.parallel()による直感的なフロー制御 - RAG: ベクターDB連携機能
- Memory: 短期・長期メモリによるスレッド間コンテキスト保持(Semantic Recall)
- MCP: MCPサーバー対応
- Scores: エージェント出力の品質評価
7.2 HTTPセキュリティヘッダー診断エージェントの実装
以下は、指定URLのHTTPレスポンスヘッダーを取得し、セキュリティ上の問題を分析するエージェントの実装例です。全部は載せきれないので概念コードとしてご理解ください。 また、Mastraは進化の速度が非常に早く、バージョン差異でコードが動かないことがありますのでご注意ください。
ステップ1: プロジェクトの初期化
MastraのQuick Start Guideを参考にプロジェクトを初期化します。プロジェクトを初期化すると./agents, ./tools のディレクトリが出来ます。ここまで呼んでくださった方であればなんとなく察しが付くかもしれませんが、ToolCallingの定義を ./toolでLLMの呼び出しを./agentsで行います。
ステップ2: ツールの定義
(.
/tools/security-headers.ts)import { createTool } from "@mastra/core/tools";
import { z } from "zod";
export const securityHeadersTool = createTool({
id: "check-security-headers",
description: //LLMから認識されるツールの説明。いつどのように使うのかをコンテキストに埋め込んでLLMが適切に使えるようにする。
"指定URLにHTTPリクエストを送信し、レスポンスヘッダーを取得する。" +
"セキュリティ関連ヘッダー(CSP, HSTS, X-Frame-Options等)の" +
"有無を確認するために使用する。",
inputSchema: z.object({
url: z.string().url().describe("調査対象のURL"), //ここも、LLMから認識される。
}),
outputSchema: z.object({
statusCode: z.number(),
headers: z.record(z.string()),
securityHeaders: z.object({
contentSecurityPolicy: z.string().nullable(),
strictTransportSecurity: z.string().nullable(),
xFrameOptions: z.string().nullable(),
xContentTypeOptions: z.string().nullable(),
referrerPolicy: z.string().nullable(),
permissionsPolicy: z.string().nullable(),
}),
}),
execute: async ({ context }) => {
const { url } = context;
try {
const response = await fetch(url, {
method: "GET",
redirect: "follow",
signal: AbortSignal.timeout(10000),
});
const headers: Record<string, string> = {};
response.headers.forEach((value, key) => {
headers[key.toLowerCase()] = value;
});
return {
statusCode: response.status,
headers,
securityHeaders: {
contentSecurityPolicy:
headers["content-security-policy"] ?? null,
strictTransportSecurity:
headers["strict-transport-security"] ?? null,
xFrameOptions:
headers["x-frame-options"] ?? null,
xContentTypeOptions:
headers["x-content-type-options"] ?? null,
referrerPolicy:
headers["referrer-policy"] ?? null,
permissionsPolicy:
headers["permissions-policy"] ?? null,
},
};
} catch (error) {
return {
statusCode: 0,
headers: {},
securityHeaders: {
contentSecurityPolicy: null,
strictTransportSecurity: null,
xFrameOptions: null,
xContentTypeOptions: null,
referrerPolicy: null,
permissionsPolicy: null,
},
};
}
},
});ステップ3: エージェントの定義 (src/mastra/agents/security-auditor.ts)
import { Agent } from "@mastra/core/agent";
import { securityHeadersTool } from "../tools/security-headers";
export const securityAuditorAgent = new Agent({
name: "Security Header Auditor",
instructions: `あなたはWebアプリケーションセキュリティの専門家です。
与えられたURLのHTTPセキュリティヘッダーを分析し、以下の観点で評価してください:
1. 各セキュリティヘッダーの有無と設定値の適切性
2. 欠落しているヘッダーがもたらすリスク(具体的な攻撃シナリオ)
3. 推奨される設定値(コピー&ペースト可能な形式で)
4. OWASP Secure Headers Projectの推奨事項との比較
評価結果は、重要度(Critical/High/Medium/Low/Info)を付与して報告してください。
CWE番号が該当する場合は併記してください。`,
// System Prompt ペルソナや行動計画を指示する事でエージェントをコントロールできる。プロンプトの描き方はいくつかテクニックがある
model: {
provider: "ANTHROPIC",
name: "claude-sonnet-4-5-20260210",
},// LLMの呼び出しはai-sdkと呼ばれる別のライブラリが担う。ai-sdkは様々なLLMプロバイダと連携できるため、数多くのプロジェクトに組み込まれている
tools: { securityHeadersTool },
});
ステップ4: Mastraへの登録と実行 (src/mastra/index.ts)
import { Mastra } from "@mastra/core";
import { securityAuditorAgent } from "./agents/security-auditor";
export const mastra = new Mastra({
agents: { securityAuditorAgent },
});
// 実行例
async function main() {
const agent = mastra.getAgent("securityAuditorAgent");
const result = await agent.generate(
"https://example.com のセキュリティヘッダーを診断してください"
);//generateではなくstreamをつかうと、我々が普段AIを使うように文字が次々と出力される様子を見ることができる。が、文字の連結処理などが面倒なのでテスト段階ではgenerateで処理が終わったら一気に見れるほうが扱いやすい
console.log(result.text);
}
main();
npm run dev
# Mastraの開発サーバーhttp://localhost:4111起動(Playgroundで対話的にテスト可能)
結構簡単に、LLMがHTTPヘッダーを取得するツールを自律的に呼び出し、専門知識に基づいて診断結果を生成する エージェントが動作するイメージです。エージェントを弄くるより、ツールの設計や動作のほうがよりコーディングに時間をかけることになると思います。
この例では、マルチターンを想定していません。ワンショットで命令してツールを使用し単一の回答を得るものです。実際のエージェントではプロンプトを工夫し、マルチステップの設定をしたフレームワークを利用することで自律的行動に近づきます。
今回はここまで。もしよく閲覧されるようであれば、マルチターンを想定したDeepResearchエージェントの作成、エージェントの基本構造、エージェント構成における直面する問題、セキュリティの知識の埋め込み方、記憶管理なども記事にできればと思います。
参考文献
[1]: "An AI-Driven Pen Tester Became a Top Bug Hunter on HackerOne", Dark Reading, Aug 2025. https://www.darkreading.com/vulnerabilities-threats/ai-based-pen-tester-top-bug-hunter-hackerone
[2]: Vaswani, A., et al., "Attention Is All You Need", NeurIPS 2017. arXiv:1706.03762
[3]: Andreessen Horowitz, Enterprise AI Spending Survey 2025. VentureBeat報道, Jan 2026. https://venturebeat.com/technology/openais-gpt-5-3-codex-drops-as-anthropic-upgrades-claude-ai-coding-wars-heat
[4]: Raschka, S., "The State of LLMs 2025: Progress, Problems, and Predictions", Jan 2026. https://magazine.sebastianraschka.com/p/state-of-llms-2025
[5]: "Kimi K2.5: Visual Agentic Intelligence", Moonshot AI, Jan 2026. 分析: https://intuitionlabs.ai/articles/kimi-k2-open-weight-llm-analysis
[6]: "Anthropic's Claude Code is having its 'ChatGPT' moment", UncoverAlpha, Jan 2026. https://www.uncoveralpha.com/p/anthropics-claude-code-is-having
[7]: Osmani, A., "My LLM coding workflow going into 2026". https://addyosmani.com/blog/ai-coding-workflow/
[8]: OpenCode GitHub Repository. https://github.com/opencode-ai/opencode
[9]: Prakash, K., "Function calling using LLMs", martinfowler.com, May 2025. https://martinfowler.com/articles/function-call-LLM.html
[10]: Yao, S., et al., "ReAct: Synergizing Reasoning and Acting in Language Models", ICLR 2023. arXiv:2210.03629
[11]: SiliconFlow Model Page. Kimi K2 Thinking: "200–300 sequential tool calls without human intervention." https://www.siliconflow.com/models
[12]: Mastra GitHub Repository. https://github.com/mastra-ai/mastra
---
本記事は2026年2月12日時点の情報に基づいています。LLMとAIエージェントの分野は日進月歩であり、公開時点で状況が変わっている可能性があります。技術的な正確性については、必ず一次情報をご確認ください。
---
おすすめ記事


