本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。

1. はじめに
新年あけましておめでとうございます……と言っても、気づけば年明けから一ヶ月が経とうとしています。
皆様は年末年始ゆっくり過ごせましたでしょうか。 私は休暇中ほとんど帰省先の実家で過ごし、しっかりリフレッシュできました。
前回初めて記事(「React2Shell」(CVE-2025-55182)の攻撃観測と感染するマルウェアを解析)を出させていただきましたが、大変ご好評いただいたとのことで、ありがとうございます。
今年もサイバーセキュリティに関する有用な情報をお届けできるよう、頑張っていきたいと思います。
さて今回の記事では、年末からインターネット上の観測環境で確認した、生成AIに関連する通信について取り上げます。
結論から言うと、観測したのは「Chat Completions」形式( OpenAIが整備した、生成AIとメッセージをやり取りするためのAPIの仕組み。詳しくは後ほど解説します。)に見える探査パケットで、LLMの普及に伴って今後増える可能性があると感じています。
近年のAI動向:巨大化だけでなく「小型でも実用的」へ
ここ最近の生成AIは「より大きく」だけでなく、「より小さくても実用的に」という方向でも進化しています。
以前は高性能なAIほど「巨大で重い」のが当たり前でしたが、近年は学習方法やデータの工夫によって、サイズは控えめでも文章生成・要約などを十分にこなせるモデル(例えば、Microsoft の Phiシリーズ¹やGoogle の Gemmaシリーズ²)が増えています。
このように、クラウド上の巨大モデルだけでなく、手元のPCや小型サーバ、エッジ環境でも動かせる“軽量なLLM”をプロダクトに組み込むことが現実的になりました。
結果として、AI機能を社内ツールやSaaS、業務アプリ、組み込み機器など様々なサービスに組み込み、そのまま外部に提供・公開する動きが広がっています。
さらに、その動きが加速すればするほど、それを狙う攻撃も増えていきます。今回観測したものは、まさにその兆候と言えるものでした。
2. 観測の詳細
まず初めに、今回観測した通信パケットの一例を示します(図1)。
パケットは HTTPのPOSTリクエストです。
ボディにはJSON形式のデータが設定されており、LLMモデルやロール、入力プロンプトといった文字列が含まれていました。
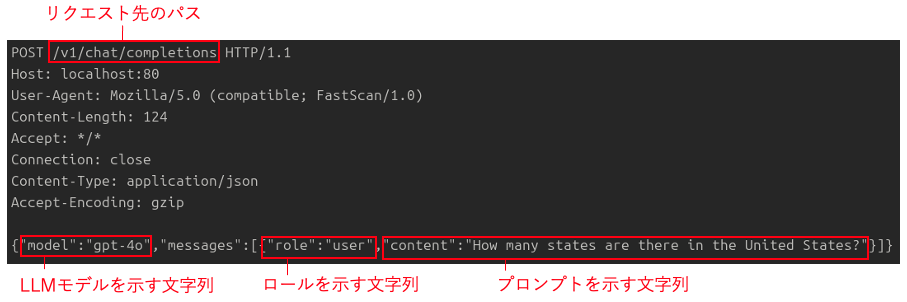
図1:観測した探査リクエストの一例(HTTP POST)
またJSONデータにはいくつかバリエーションがあり、LLMモデル名が異なるものや入力プロンプトが異なるもの、追加でパラメタが付与されているものなどを観測しました(図2)。
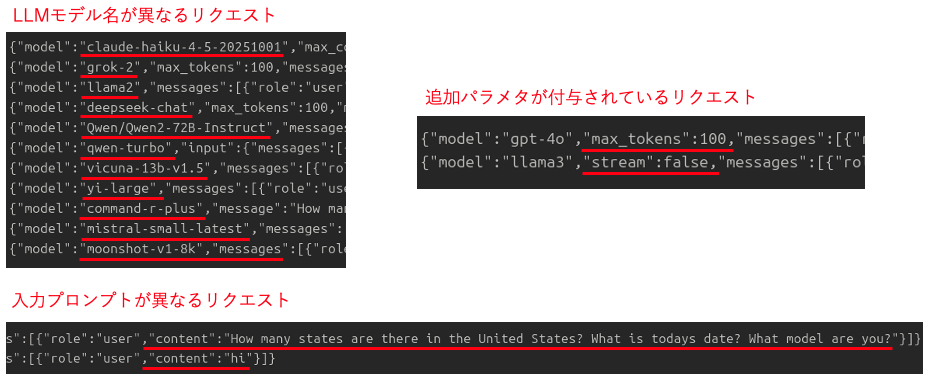
図2:リクエストボディ(JSON)のバリエーション
これらのパケットは 2025/12/30 に初観測しました。その後も2025/12/31、2026/1/7、1/8、1/9 に観測しています(図3)。

図3:観測時系列(初観測~継続観測)
3. POSTリクエストの正体
観測したリクエストは、OpenAIが提供している Chat Completions API³ の形式に酷似しています(図4)。
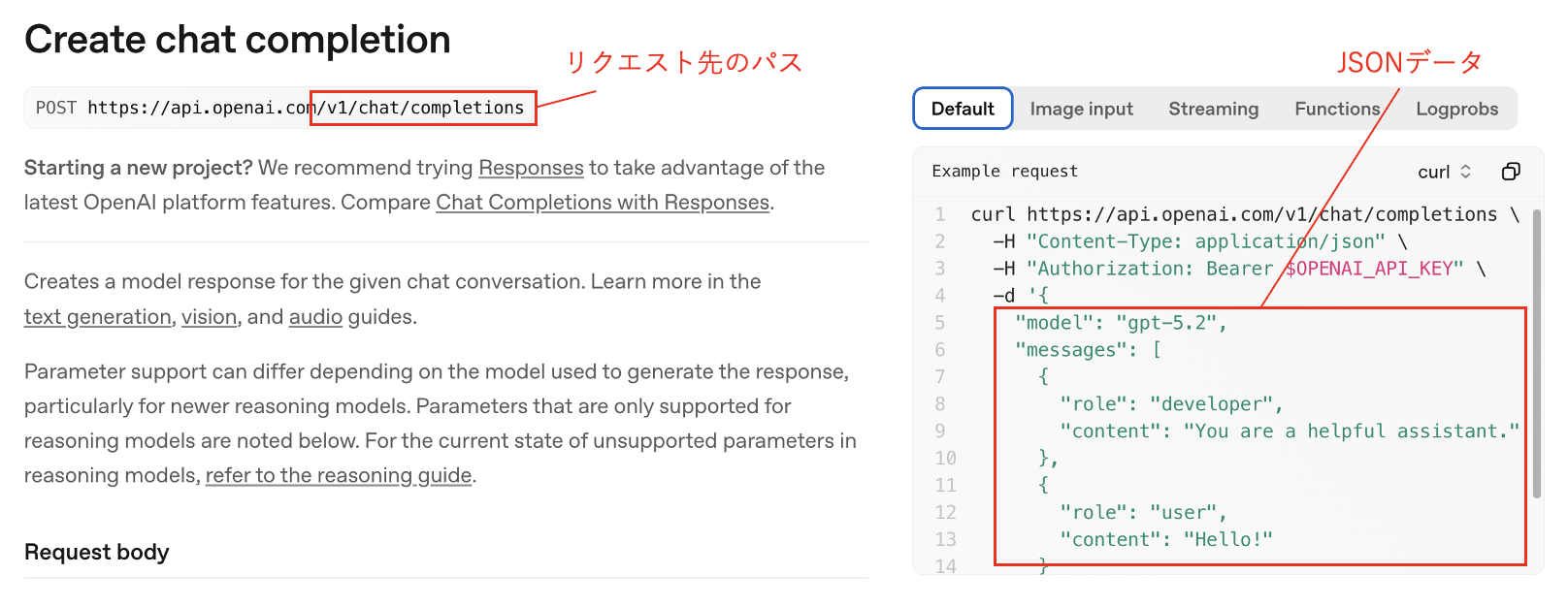
図4:OpenAIのChat Completionsに関するマニュアル抜粋
Chat Completionsは、OpenAIがChatGPTをAPIとして提供する過程で整備した呼び出し形式で、messages(会話ログ)を渡すと、モデルが「次の発話」を返すという設計です。
Chat Completionsは一言で言えば、「チャットAIに話しかけるための定番の書式」です。
人間がチャット画面でやっていることを、機械が分かる形にすると次のようになります。
1. 最初に「AIへのお願い(役割)」を渡す(例:丁寧に解説して)
2. 次に「ユーザーの質問」を渡す
3. するとAIが「次の返答」を返す
この「会話の並び」を順番どおりにまとめたものが messages で、Chat Completionsは「この会話の続き(次の返答)を作ってください」と依頼するAPIです(図5)。

図5:Chat CompletionsAPIの仕組み
OpenAI互換APIとしてのChat Completionsの普及
現在は、ローカルLLMを含む多くの実装が、Chat Completionsを「OpenAI互換API」として採用しています。
つまり、OpenAI向けに作られた既存のクライアントやツールを、接続先(base URL)を差し替えるだけでローカルLLMに向けられるケースが増えています。
代表例として、以下のローカルLLMツール群は互換エンドポイントを明記しています。
• llama.cpp⁴:llama-server が OpenAI互換の chat completions / embeddings ルートを提供(ただし「完全互換を強く主張はしない」と注意書きあり)。
• Ollama⁵:OpenAI互換の利用方法を案内(対応範囲や制約の注記あり)。
• LM Studio⁶:OpenAI互換エンドポイント(Chat Completions等)を提供し、base URL差し替えで利用できる旨を明記。
• LocalAI⁷:OpenAI互換の「drop-in replacement REST API」を掲げるローカル/オンプレミス向け実装。
これらの普及が進むほど、攻撃者側からすると「OpenAI互換の入口を探す」という行為が、以前より「当たり前の探索対象」になっていきます。
4. 攻撃者の狙いや悪用事例
これまでの内容から、攻撃者は 外部公開されているLLM(OpenAI互換API)の稼働状況を確認している可能性が高いと考えられます。さらに、その先に何を行おうとしているのかも合わせて整理します。
(1) LLMエンドポイント探索
/v1/chat/completions 相当を叩き、レスポンスの違い(200/401/404/500など)から、LLMサーバが稼働しているか/認証が必要か/ Chat CompletionsAPIのような実装か などを確認します。
(2) 実装の特定
エラーメッセージ、レスポンスJSONの癖、ヘッダ、ストリーミング挙動などから、llama.cpp系か/Ollama系か/別実装か といった当たりを付け、次の攻撃手順(既知の弱点・設定ミス狙い)に繋げます。
(3) 設定ミスのあぶり出し(認証なし公開・弱い認証)
意図せず認証なしで公開している、またはリバースプロキシ設定の穴がある、といった環境を探します。
(4) 計算資源の不正利用(タダ乗り)・DoS
認証なしで推論が回せると、攻撃者は以下のような実害を起こすことができます。
• 推論を勝手に回してコスト・GPU/CPUを消費させる(タダ乗り)
• 過大な入力や高頻度POSTでサービスを重くする(DoS)
(5) 情報漏えい・意図しないリクエスト実行
LLMが単体で動いているだけであれば、攻撃が成立しても被害は誤回答や計算資源の浪費に留まりやすいのですが、RAG(検索拡張生成)や外部ツール呼び出し、URL取得といった機能が加わると、LLMの出力がそのまま“次の処理”や“実行”につながるため、情報漏えいだけでなく、意図しないリクエストの実行や不正操作まで現実的になります。
OWASPの「Top 10 for LLM Applications」⁸は、LLMアプリが外部と連携するとリスクが一気に増幅する点を、複数の観点に分けて整理しています。
たとえば、入力や外部コンテンツに悪意ある指示を混ぜるプロンプトインジェクションは、単なる会話の誘導に見えても、ツール連携がある環境では「会話の改ざん」が「操作の強制」に変わります。
LLMがメール本文やWebページ、社内文書を読んだ結果として、攻撃者の意図した処理を実行してしまう可能性があるためです。
さらに、エージェント型のようにLLMが判断して複数のツールを呼び出す構成では、LLMに過剰な権限や自律性を与えているほど、曖昧な指示や巧妙な誘導で下流のツールが意図しない形で実行されてしまい、被害が広がりやすくなります。
また、LLMが生成したURLやパラメタ、コマンド文字列を十分に検証せずにHTTPクライアントやクローラー、コマンド実行、DBクエリなどに渡してしまう設計は、古典的なインジェクションと同じ構図で事故を引き起こします。
OWASPでも、不適切な出力処理の結果としてXSSやCSRFに加えてSSRF、権限昇格、RCEに至り得ることが示されています。
RAGについても同様で、検索対象やナレッジベースに攻撃者が混入できると検索結果の汚染や誘導が起き、LLMの出力が操られますし、アクセス制御やスコープ分離が弱いと本来見せない情報が検索で引き当たり、漏えいにつながります。
(6) AI駆動型マルウェアの実行基盤化
認証なしで公開されているLLMは、マルウェアの実行基盤として悪用される可能性もあります。
従来、LLMの悪用といえば「攻撃者がAIにマルウェアを作らせる」という開発支援の文脈が中心でしたが、2025年に入り新たなパターンが確認されています。
AI駆動型マルウェアと呼ばれるこの手法では、マルウェア自体が実行時にLLM APIを呼び出し、必要なコードを動的に生成・取得します。
例えば、ウクライナの政府機関を標的とした攻撃で使われた「LAMEHUG」は、Hugging Faceの公開APIを通じてコーディング特化モデル(Qwen2.5-Coder)にプロンプトを送り、システム情報の収集や個人ファイルを窃取するコードを動的に生成させていました。
マルウェア本体には悪意あるコードが直接記述されていないため、従来のシグネチャベースの検知をすり抜けやすいという特徴があります。
認証なしで公開されたLLMは、こうした攻撃者にとって「無料で使える悪性コード生成器」や「検知されにくいC2インフラ」となり得ます。
自組織のLLMが意図せず攻撃インフラの一部として利用されるリスクも考慮が必要です。
5. LLMの公開状況
LLMは、世界中でどれくらい公開されているのでしょうか。
試しにSHODANを使って、先ほど紹介したローカルLLMツールを使っていると思われるサーバを検索したところ、稼働中と思われるものを多数確認することができました(図6)。
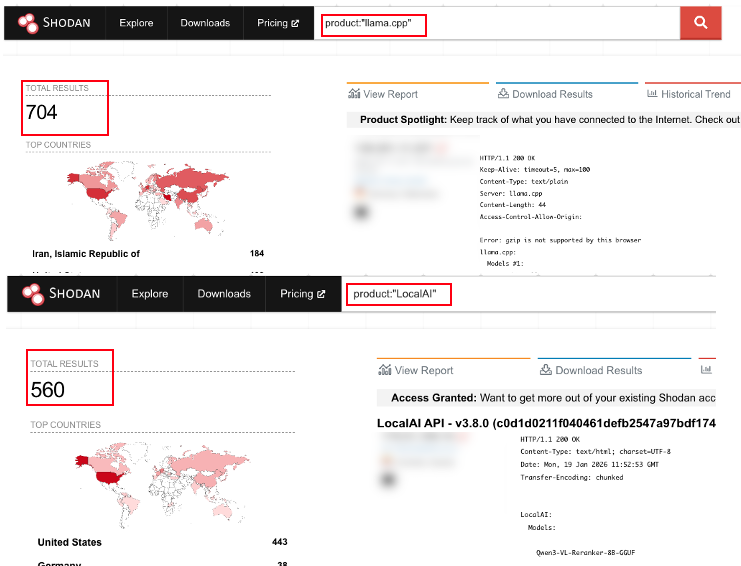
図6:SHODANで確認したLLMサーバの稼働状況
もちろんこれは「見えている範囲」のごく一部分でしかありません。
他ツールのサーバや非公開サーバを含めればさらに多くのLLMサーバが稼働していると考えられます。だからこそ、攻撃者にとってLLMサーバは「次のターゲット面」の選択肢となり得るのです。
6. IoC(Indicators of Compromise)
• 探査に使用されたIPアドレス
204.76.203.125
45.88.186.70
7. 終わりに
小さくても高性能なモデルが増えたことで、自前システム内にLLMを組み込む動きは今後も加速すると考えられ、それに伴いLLMを狙った探査・悪用も増えることが予想されます。
最後に、今回の観測から改めて強調したいポイントをチェックリストとしてまとめます。
• [ ] LLMのAPIをむやみにインターネットに直接出さない(必要ならVPN/閉域/アクセス制御)
• [ ] 認証(APIキー等)を必須化し、鍵の使い回し・弱い鍵を避ける
• [ ] レート制限/タイムアウト/最大入力長(コンテキスト)制限でDoS耐性を上げる
• [ ] ログを必ず残す(パス・UA・サイズ・頻度・失敗応答など)
• [ ] 連携機能(RAG、外部URL取得、ツール実行)がある場合は以下を確認
[ ] 外向き通信の制御(許可リスト)
[ ] 機密データへの到達経路を分離
[ ] プロンプトインジェクション前提の設計(影響最小化)
プログラムと違ってAIは出力が一定でないため、従来型の「入力サニタイズだけ」では守り切れません。 「公開していないつもり」になっていないか、今一度設定確認をしましょう。
脚注(参考リンク)
1. Phi-4(Microsoft Technical Report)
2. Gemma 3(Google 公式:Gemma 3 日本語版の案内)
3. OpenAI Chat Completions API リファレンス
4. llama.cpp(llama-server / OpenAI互換の説明)
5. Ollama(OpenAI compatibility:対応範囲の注記あり)
6. LM Studio(OpenAI互換エンドポイント)
7. LocalAI(OpenAI互換 “drop-in replacement”)
8. OWASP Top 10 for LLM Applications
おすすめ記事




