本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。

現在、世界各国で自動運転車の開発が盛んに行われています。
自動運転車は、人間が運転操作を行わなくとも自動で走行できる自動車と定義されており、カメラやレーダー、GPSなどのセンサー類や、高精細の地図情報を配信するクラウドサービス、また、他車両と通信を行うネットワークサービスなどを組み合わせることで、自律的な走行を実現しています。また、より完全な自律走行を実現するために、道路標識や歩行者などの認識や、運転操作の意思決定をディープラーニング・モデルで行う自動運転車も開発が進んでいます。
このように、自動運転車には「繋がる」「自律走行」という、従来の自動車にはなかった新たな性質が加わっています。しかし、これと同時に、センサー類やクラウドサービス連携に対する攻撃や、ディープラーニング・モデルに対する攻撃といった、従来の自動車にはなかった新たな攻撃経路も生まれています。
そこで、本連載は「自動運転車・セキュリティ入門」と題し、主にディープラーニング・モデルを採用した自動運転車に対する攻撃手法と防御手法を幅広く・分かり易く取り上げていきます。本連載を読むことで、自動運転車・セキュリティの全体像が俯瞰できるようになるでしょう。
なお、本連載は、2021年4月10日に公開された論文「Deep Learning-Based Autonomous Driving Systems: A Survey of Attacks and Defenses」をベースにしています。ただし、本連載では単に論文を和訳するのではなく、内容を分かりやすく噛み砕き、また、弊社の知見/見解を盛り込んだ内容としています。また、論文中で引用されている文献はほとんどが英語ですが、本連載では可能な限り日本語の文献を引用するようにしています。
本連載が、皆さまの自動運転車・セキュリティの理解の一助になれば幸いです。
連載一覧
「自動運転車・セキュリティ入門」は全5回のブログで構成されています。
今後、以下のタイトルで順次掲載していく予定です。
- 第1回:自動運転車・セキュリティの概要(公開済み)
- 第2回:センサー・カメラに対する物理的攻撃(公開済み)
- 第3回:クラウド連携に対するサイバー攻撃(公開済み)
- 第4回:意思決定モデルに対する敵対的攻撃 - 回避攻撃 -
- 第5回:意思決定モデルに対する敵対的攻撃 - 汚染攻撃 -
第1〜3回は公開済みです。
ご興味がございましたら読んでいただけると幸いです。
はじめに
本ブログは第4回「意思決定モデルに対する敵対的攻撃 - 回避攻撃 -」です。
本ブログでは、自動運転車に搭載されている意思決定モデルの概要、そして、意思決定モデルに対する攻撃手法の一つである回避攻撃とその防御手法を解説していきます。
それでは、本編に入っていきましょう。
意思決定モデルとは?
自動運転車における意思決定モデルとは、車両の周辺環境の認識や運転操作の決定を行うディープラーニング・モデルを指しています。
以下の図は、第1回のブログでも取り上げた、自動運転車のプロセスとアーキテクチャを表しています。
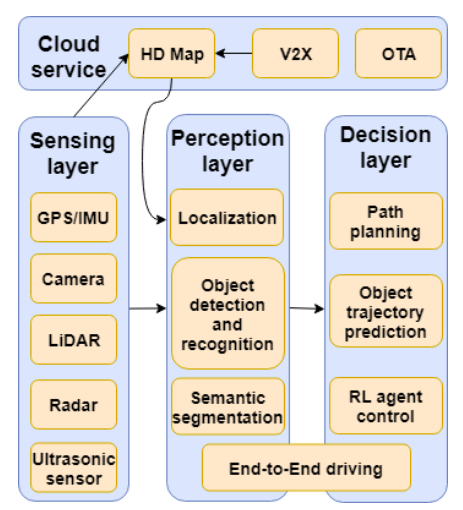 自動運転車のアーキテクチャ(再掲)
自動運転車のアーキテクチャ(再掲)(出典:Deep Learning-Based Autonomous Driving Systems)
意思決定モデルは「Perception layer」と「Decision layer」から構成されます。Sensing layerから取得したデータやCloud serviceから取得したHD MapはPerception layerに入力され、道路標識や他の車両、歩行者など、自動運転操作に必要な情報が抽出されます。そして、抽出された情報はDecision layerに入力され、車両を停止する・左に曲がる・速度を上げるなどの運転操作が決定されます。
以下、Perception layerとDecision layerの機能を少し掘り下げて見ていきましょう。なお、本セクションの内容は「第1回:自動運転車・セキュリティの概要」の再掲となりますので、スキップしたい方は次セクション「攻撃手法」から読んでいただければと思います。
Perception layer
Perception layerの意思決定モデルは、Sensing layerから取得したデータやCloud serviceから取得したHD Mapを基に、運転操作の意思決定に必要な情報を抽出します。
一般的には、Perception layerは以下に示す3つのタスクを行います。
Localization
車両の現在位置を特定します。
センサーフュージョン技術により、GPS・IMU・LiDAR・カメラなどのセンサー類とHD Mapが融合され、自動運転車の位置推定や(車両周囲の)地図の再構築が行われます。Localizationの結果は、自動運転車の走行経路の計画に使用されます。
Object detection and recognition
路上や路肩の物体を検出します。
このタスクでは、車線・道路標識・他の車両・歩行者など、形状の異なる物体をリアルタイムに、かつ、正しく検出する必要があるため、自動運転車にとって非常に重要なタスクの一つです。物体検出の代表的なディープラーニング・アルゴリズムとして、Faster R-CNNやYOLOなどが挙げられます。これらのアルゴリズムは、カメラから取得した画像データを入力に取り、車や人などをほぼ同時にリアルタイムに検出することができます。
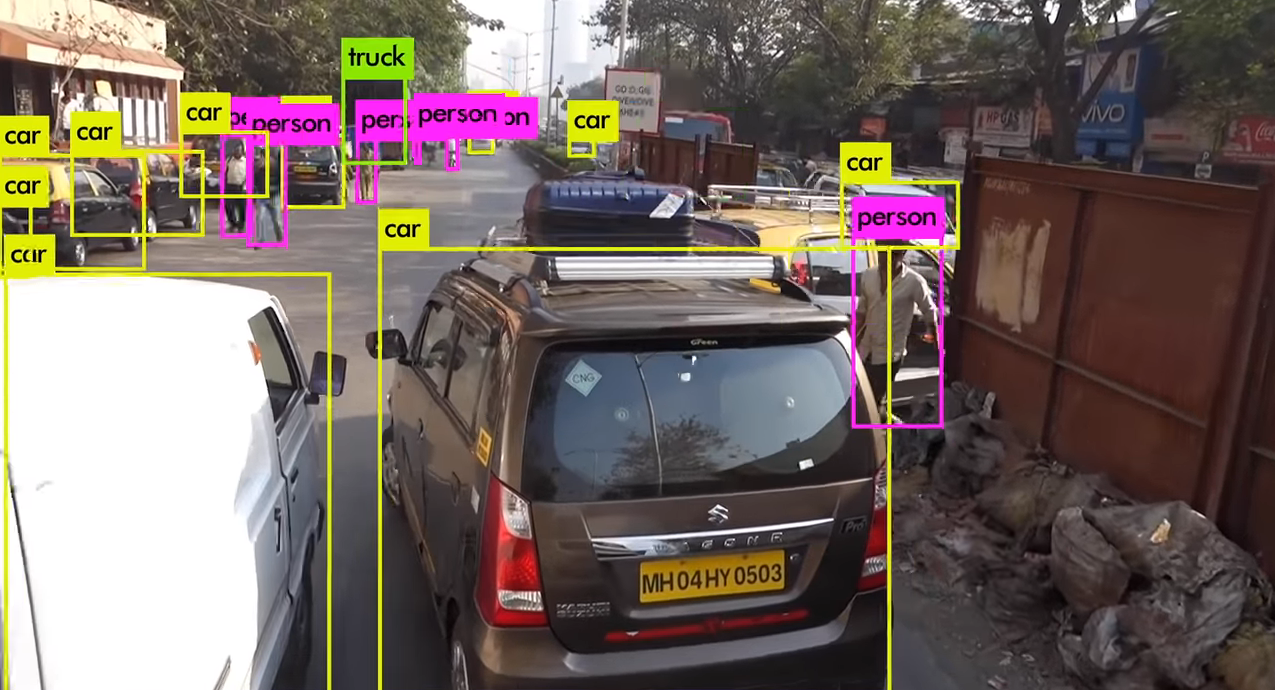 YOLOv3による物体検出
YOLOv3による物体検出(出典:YOLOv3, Youtube)
また、LiDARのデータを入力に取り、物体を検出するディープラーニング・モデルも盛んに研究が行われており、VoxelNetが代表的なモデルです。その他にも、LiDARで取得した点群から物体を検出するディープラーニング・モデルも提案されています。
 VoxelNetによる物体検出
VoxelNetによる物体検出(出典:VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection, arXiv.org)
Semantic segmentation
カメラから取得した画像を車両・歩行者・地面などのクラスに分割します。
クラス分割により、車両の位置推定・物体検出・車線の把握、そして、地図の再構築などを行うことが可能となります。Semantic segmentationの代表的なアルゴリズムとして、Fully Convolutional Network(FCN)やPSPNetなどが挙げられます。
以下の図は、FCNとPSPNetでクラス分割した様子を表しています。
一枚の画像を、家・林・空、ベッド・枕・机というように、ほぼ正確に分割できていることが分かります。
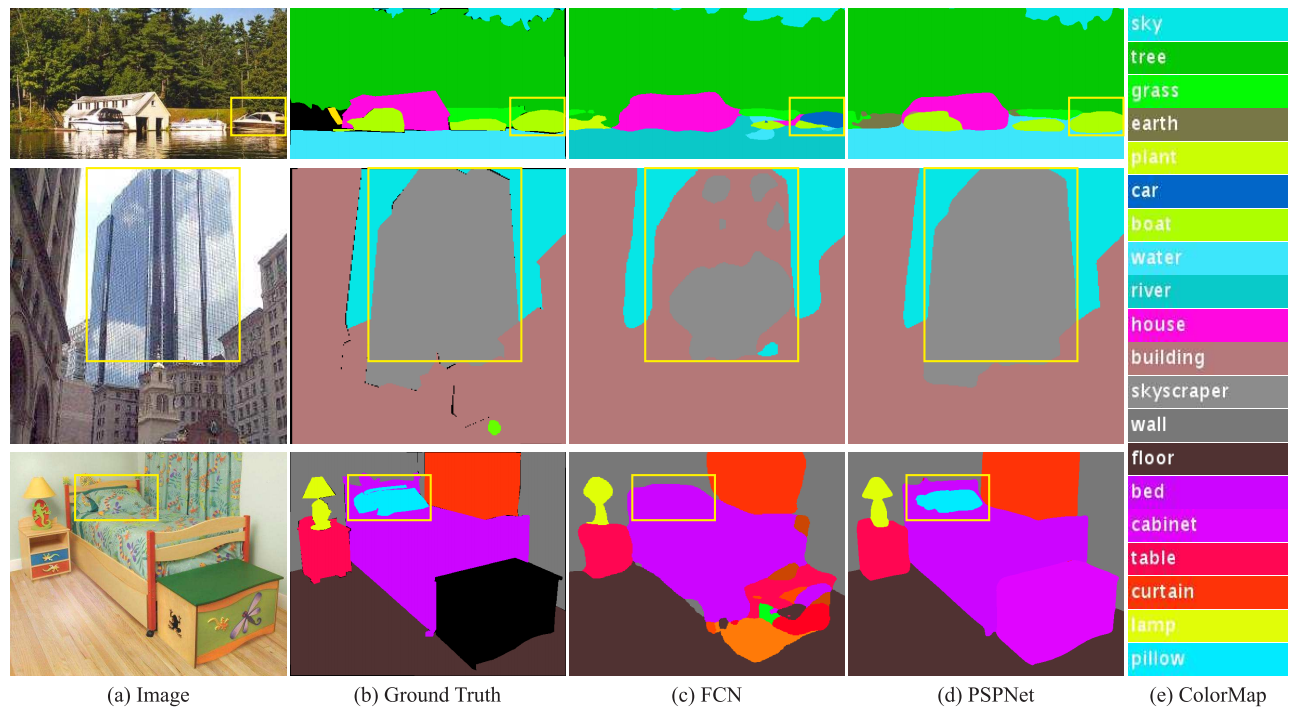 クラス分割の一例
クラス分割の一例(出典:Pyramid Scene Parsing Network, arXiv.org)
このように、Perception layerでは様々なディープラーニング・モデルを使用し、車両位置の特定や物体検出、そして、物体のクラス分割などを行うことで、運転操作の意思決定に必要な情報を抽出します。
Decision layer
Decision layerの意思決定モデルはPerception layerで抽出した情報を基に、運転操作の意思決定を行います。
Decision layerでは、主に以下に示す3つのタスクを行います。
Path planning and object trajectory prediction
効率的な走行や衝突回避のために、走行経路計画と物体の軌道予測を行います。
走行経路計画は、自動運転車の出発地から目的地までの効率的な走行経路を決定するタスクです。このタスクを実現するために、様々な取り組みが行われています。 例えば、人間のドライバーによる走行を深層強化学習モデル(ディープラーニングと強化学習を組み合わせたモデル)に学習させることで、走行経路計画を人間に近づける研究が行われています。学習が上手く進んだ場合、より人間に近い走行経路を計画できるようになります。
物体の軌道予測は、路上の障害物の検知・回避を行うタスクです。このタスクでは、Perception layerで抽出した情報を基に、ディープラーニング・モデルで障害物の軌道を予測する必要があります。このタスクを実現するために、様々な取り組みが行われています。
例えば、時系列データを学習できるディープラーニング・モデル「Social GAN」が提案されています。以下の図は、Social GANで歩行者の軌道を予測した実験結果を表しています。
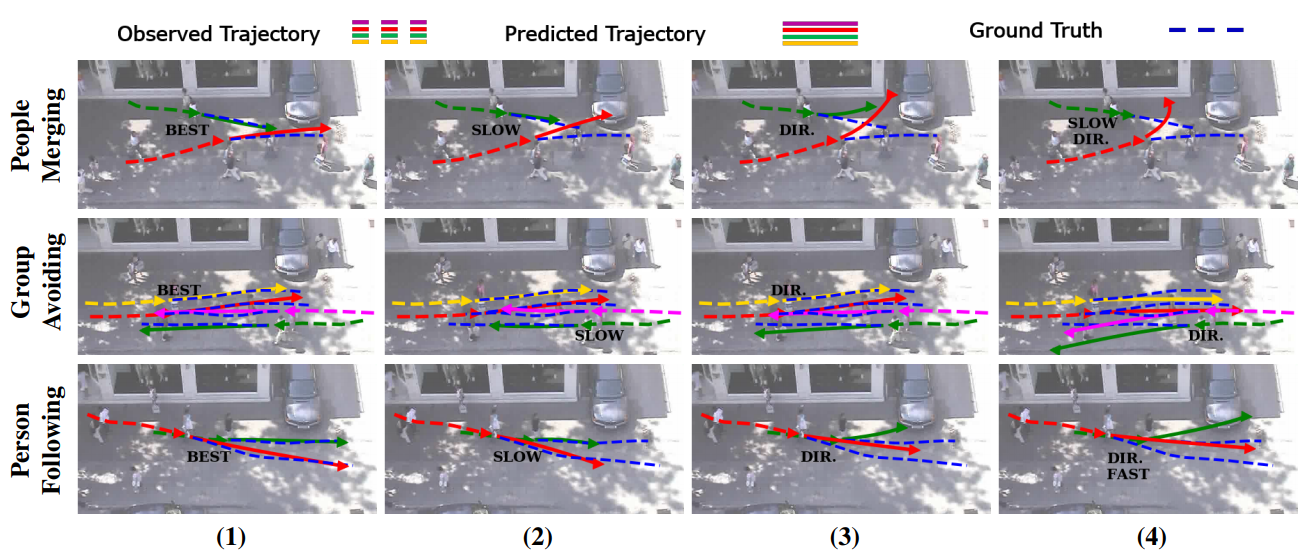 Social GANによる歩行者の軌道予測
Social GANによる歩行者の軌道予測(出典:Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks, arXiv.org)
破線が実際の軌道、実線がモデルが予測した軌道であり、別々の人が歩道上で交差する場合や、複数人の歩行者がすれ違う場合など、複数のシナリオで複数回検証を行っています。なお、図中の「SLOW」「FAST」は歩行者が衝突を避けるために歩みを加減速させたことを意味しており、「DIR」は同じく歩く方向を変えたことを意味しています。「BEST」は実際の軌道と予測が殆ど一致した検証例を意味しています。この検証結果から、ある程度正確に歩行者の軌道を予測できていることが分かります。
Vehicle control via deep reinforcement learning
自動運転車の最適な運転操作を行います。
従来のルールベースのアルゴリズムでは、無数の状況が存在する複雑な運転シナリオをすべてカバーすることはほぼ不可能です。この課題を解決するために、様々な状況下において最適な行動をとるようにエージェントを学習させる「深層強化学習」が注目されています。
例えば、人間のドライバーによる走行で収集された2Dおよび3Dデータを学習することで走行経路を計画する、逆強化学習モデルの研究が行われています。その他にも、元々はクラッシックゲームを自律的にプレイすることを目的に開発された「Deep Q-Network(DQN)」を、自動運転車の操舵制御に応用した深層強化学習モデルも提案されています。
(出典:Deep Q network learning to play Breakout, Youtube)
End-to-End driving
センサー類で取得した情報に基づいて、現在の走行速度や操舵角を予測します。
End-to-End drivingは、Perception layerとDecision layerを組み合わせたディープラーニング・モデルであり、NVIDIAのDAVE-2が代表的なモデルです。以下のデモ動画では、車両のフロントカメラから取得した画像をディープラーニング・モデルに入力することで、道路状況に適した操舵角を正確に予測しています。
(出典:Dave-2 A Neural Network Drives A Car, Youtube)
このように、Decision layerでは、Perception layerで抽出された情報を基に、様々なディープラーニング・モデルを使用して自動運転車の走行経路や運転操作を決定します。仮にセンサー類やクラウドサービスが攻撃を受け、Perception layerへの入力データが細工された場合、Perception layerは正確に情報が抽出できなくなります。これによりDecision layerの決定に誤りが生じ、交通事故が発生することになります。
攻撃手法
ここからは、意思決定モデルに対する攻撃手法を見ていきましょう。
以下の図は、第1回ブログでも取り上げた「自動運転車の攻撃経路」を表しています。青い四角が自動運転車の構成要素、赤い破線四角が各構成要素に対する攻撃を表しています。また、黄色く囲まれた箇所は、Perception layerとDecision layerを含むディープラーニング・モデルになります。
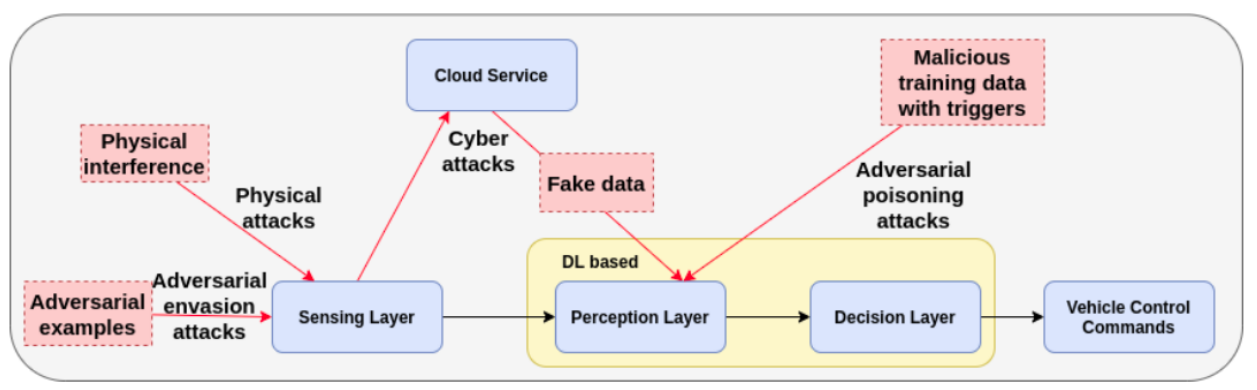 自動運転車の攻撃経路
自動運転車の攻撃経路(出典:Deep Learning-Based Autonomous Driving Systems, arXiv.org)
上図の攻撃の内、「Adversarial evasion attacks(回避攻撃)」と「Adversarial poisoning attacks(汚染攻撃)」はディープラーニング・モデルと密接に関わる攻撃です。汚染攻撃の解説は次回のブログに譲ることにし、本ブログでは回避攻撃に焦点を当てて解説していきます。
回避攻撃とは?
回避攻撃とは、ディープラーニング・モデルへの入力データを偽装することで、モデルの分類結果を意図的に誤らせる攻撃手法です。
近年の研究により、ディープラーニング・モデルは、人間が知覚できない微小なノイズを加えた入力データを誤分類することが分かっています。ここで、入力データに加えられるノイズを「摂動」、摂動が加えられた入力データを「敵対的サンプル(Adversarial Examples)」と呼びます。摂動は入力データの特徴量を変化させる役割を持ちます。
敵対的サンプルは人間の目には正常に見えるものの、ディープラーニング・モデルは摂動の影響により誤ったクラスに誤分類してしまいます。自動運転車では、カメラなどのセンサー類から取得した画像を基にPerception layerで物体検知を行うため、敵対的サンプルは大きな脅威となります。
以下の図は、左側のパンダ(panda)の画像に摂動を加え、特徴量をテナガザル(gibbon)に変化させた敵対的サンプルを表しています。
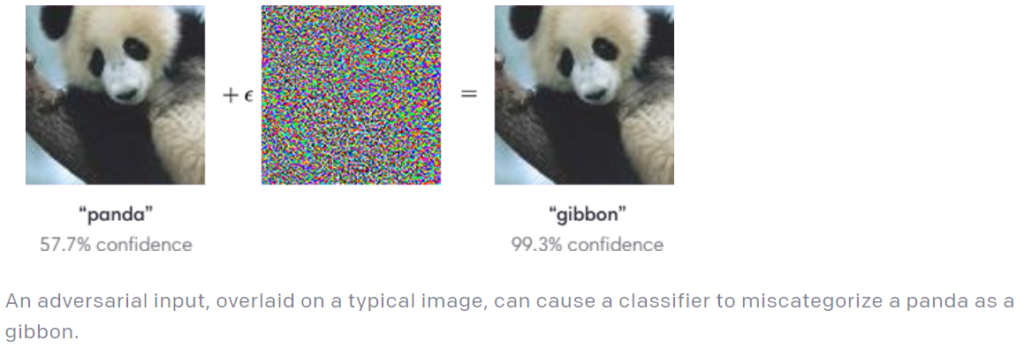 パンダをテナガザルに偽装した敵対的サンプル
パンダをテナガザルに偽装した敵対的サンプル(出典:Attacking Machine Learning with Adversarial Examples, OpenAI)
これらの画像をディープラーニング・モデルに入力すると、左の画像は正しく「panda」に分類されるのに対し、見た目はパンダに見える右の画像は「gibbon」と誤って分類されます。
以下の図では、Adversarial Patchと呼ばれる特殊なパッチ柄を使用することで、ディープラーニング・ベースの人物検知を回避する例を表しています。左側の男性は正しく「person」と判定されているのに対し、パッチ柄を持った右側の男性は検知されていないことが分かります。
 人物検知を回避するAdversarial Examples
人物検知を回避するAdversarial Examples(出典:Fooling automated surveillance cameras: adversarial patches to attack person detection, arXiv)
このように、ディープラーニング・モデルに入力されるデータを細工することで、容易にモデルを騙すことが可能となります。
この敵対的サンプルを使用して自動運転車を攻撃する検証事例も数多く存在します。 次のセクションでは、代表的な検証事例を幾つか見ていきましょう。
検証事例
自動運転車に対する攻撃の検証事例は、シミュレーション環境・実環境問わず様々な事例が存在します。本ブログでは全てを紹介することはできませんが、代表的な検証事例を幾つかピックアップして見ていきます。
DeepBillboard
H.Zhou氏らは、道路脇に設置された看板に摂動を加えることで、自動運転車の操舵角を狂わせる「DeepBillboard」と呼ばれる攻撃手法を提案しています。
本検証では、自動運転のためのデータセット「Dave」「Udacity」「Kitti」でそれぞれ学習した自動運転モデル(Dave_V1~V3)と、Udacity challengeで開発された自動運転モデル(Epoch)を攻撃対象としています。以下の図は、検証結果の一例を表しています。
 DeepBillboardにより操舵角が狂わされた様子
DeepBillboardにより操舵角が狂わされた様子(出典:DeepBillboard: Systematic Physical-World Testing of Autonomous Driving Systems, arXiv.org)
検証では、DeepBillboardを様々な位置や角度で配置し、自動運転車の操舵角に及ぼす影響を確認しています。上図の青い線は本来決定すべき正しい操舵角、赤い線がモデルが予測した操舵角を表しています。上図の通り、DeepBillboardによって操舵角に誤りが生じていることが分かります。
本検証では、操舵角の予測が最大で23度ずれるケースも確認されています。
Physical Adversarial Attack
T.Wu氏らは、物体検知を回避するように設計された敵対的サンプルを車両にプリントし、物体検知モデルから車両を秘匿する攻撃手法を提案しています。
以下の図は、本手法で作成した敵対的サンプルを車両にプリントした様子を表しています。
 車両にプリントされた敵対的サンプル
車両にプリントされた敵対的サンプル(出典:Physical Adversarial Attack on Vehicle Detector in the Carla Simulator, arXiv.org)
検証は自動運転車シミュレータ「Carla」で行われており、敵対的サンプルをプリントした車両を様々なアングルから撮影し、物体検知モデルから車両を秘匿できるのか確認しています。以下の図は、車両を斜め前・後ろ・横のアングルから撮影した検証結果を表しており、それぞれ、左はノーマルな車両、右は敵対的サンプルをプリントした車両です。また、図中の赤枠は物体検知モデルの物体認識範囲(バウンティ・ボックス)、赤字で記された数値は信頼スコアを表しています。
 敵対的サンプルの影響で物体検知の精度が低下している様子
敵対的サンプルの影響で物体検知の精度が低下している様子(出典:Physical Adversarial Attack on Vehicle Detector in the Carla Simulator, arXiv.org)
左の図では、ノーマル車両は車両全体が正しく検知されている一方で、敵対的サンプルは車両の一部分(フロントガラス)のみが検知されていることが分かります。また、真ん中の図では、敵対的サンプルの車両は物体検知モデルから完全に秘匿されていることが分かります。右の図では、敵対的サンプルの車両は検知されているものの、信頼スコアがノーマル車両の「0.999」と比較して大幅(0.679)に低下していることが分かります。
このように、車両自体に敵対的サンプルを貼り付けることで、物体検知モデルの検知精度を低下させることができます。
Dirty Road Patches
T.Sato氏らは、自動車を車線中央に維持するための「自動レーンセンタリング(Automated Lane Centering:ALC)アシスト機能」を攻撃する「Dirty Road Patches:DRP」と呼ばれる手法を提案しています。
本検証では、実際の道路上でよく見かける「白い汚れ」を模した特殊なパターン(DRP)を設計し、オープンソースの自動運転システムであるOpenPilotの車線検出モデルを騙すことに成功しています。以下の図は、DRPを道路上に設置するイメージを表しています。
 DRPを路上に設置するイメージ
DRPを路上に設置するイメージ(出典:Dirty Road Can Attack: Security of Deep Learning based Automated Lane Centering under Physical-World Attack (DRP attack))
攻撃のシナリオとして、道路整備員になりすました攻撃者がDRPをプリントしたシートを路上に設置することが想定されます。なお、上図の右側に示した写真が実際の道路上でよく見かける汚れであり、DRPはこの汚れを模して作成されます。このため、人間の目でDRPを認識することは困難です(攻撃のステルス性が高い)。
本研究では、検証環境を限りなく実世界に近づけるために、ミニチュアスケールの道路と実世界を模した様々なライティング条件を組み合わせて検証が行われています。
 実験環境
実験環境本検証では、OpenPilotのダッシュカム・デバイスを三脚に取り付け、正常な路面とDRPを貼り付けた路面における車線検出の結果を比較しています。
以下の動画は、検証実験の一例です。
(出典:[DRP Attack] Side-by-Side Attacked and Benign Lane Detection Comparison in the Miniature Scale, ASGuard UC-Irvine)
左がDRPを貼り付けた道路、右が正常な道路を表しています。動画を見ると分かるとおり、正常な道路では正しく直進する車線を検出していますが、DRPを貼り付けた道路では左に曲がる車線を誤って検出していることが分かります。
また、本研究では実車の情報を用いたSoftware-in-the-Loopシミュレーションにおける攻撃検証も行われています。この検証の結果、自動緊急ブレーキなどの安全装置が備わっている車両においても、事故が引き起こされることが分かりました。
以下の動画は、DRPの影響で車両が左に曲がり、対向車線を走るトラックに衝突するシミュレーションを表しています。
(出典:[DRP Attack] Attacked Driving in Local Road Scenario, ASGuard UC-Irvine)
さらに本検証では、OpenPilotをインストールした実車を使用した検証も行われています。なお、本検証は道路交通法の順守と、ドライバーならびに周辺への安全を配慮し、道路にDRPを設置するのではなく、OpenPilotの車線検出モデルの出力レベルにDRPを直接注入する形で検証が行われています。
以下の動画は、DRPの影響で車両が左に曲がり、路上に置かれた段ボール箱に衝突する検証結果を表しています。
(出典:[DRP Attack] Benign and attacked drivings under attack trace injection, ASGuard UC-Irvine)
本検証では、10回の試行すべてで段ボール箱に衝突することを確認しています(衝突率100%)。
このように、DRPはシミュレーション環境のみならず、実世界でも自動運転車を攻撃することができます。なお、本検証では、OpenPilotの車線検出モデルを攻撃対象にしていますが、敵対的サンプルには転移性があるため、OpenPilot以外のモデルに対しても有効である可能性があります。
PhysGAN
Z.Kong氏らは、PhysGANと呼ばれる生成モデルを利用し、オリジナルの看板に摂動を加えて作成した「敵対的な看板」を使用し、自動運転車の操舵角を狂わせる攻撃手法を提案しています。
本検証では、Dave-2やUdacity Cg23などの自動運転モデルに対し、PhysGANで作成した敵対的な看板を提示することで攻撃の評価を行っています。以下の図は、検証結果の一例を表しています。
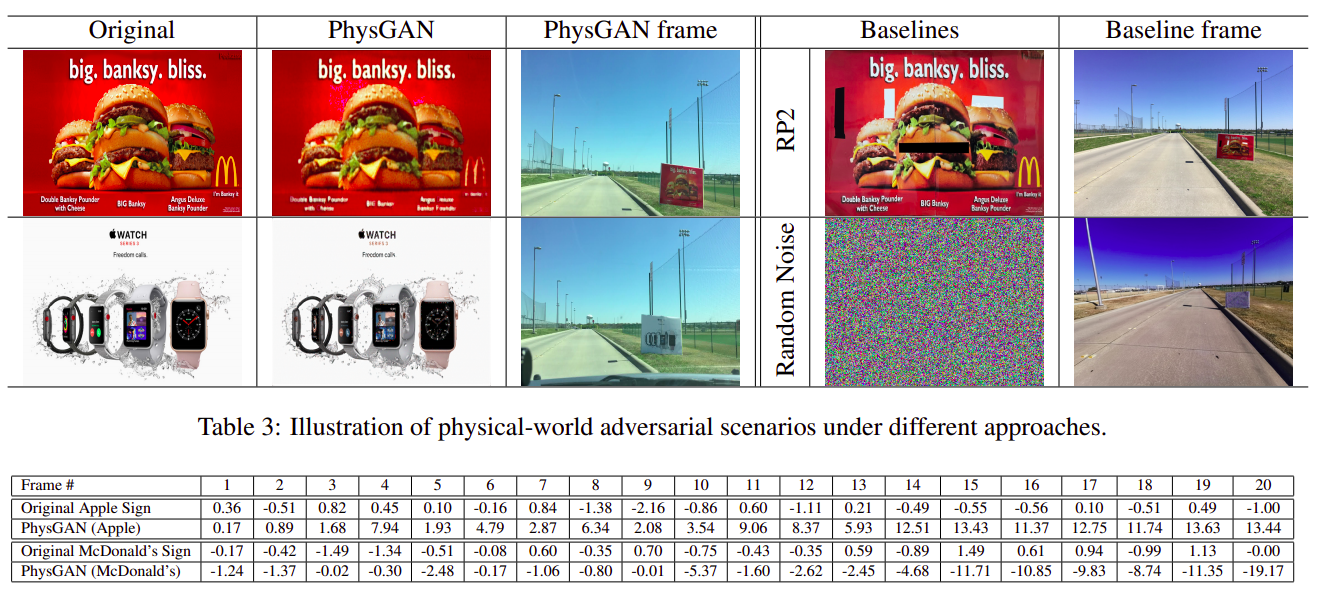 敵対的な看板によって操舵角が狂わされた様子
敵対的な看板によって操舵角が狂わされた様子(出典:PhysGAN: Generating Physical-World-Resilient Adversarial Examples for Autonomous Driving, arXiv.org)
図の上段は、マクドナルド社やアップル社の看板を模した敵対的な看板、下段の表は各看板によって狂わされた操舵角度を表しています。本検証の結果、操舵角が最大で19.17度狂わされるケースも確認されました。
なお、図を見て分かるとおり、オリジナルの看板(Original)と敵対的な看板(PhysGAN)は酷似しています。このため、敵対的な看板が路肩に設置されていても、これを人間の目で見破ることは困難です。
Model Hacking ADAS
S.Povolny氏らは、道路標識認識モデルを騙す攻撃手法を提案しています。本手法では、道路標識に特殊なステッカーを貼ることで、実車に搭載された物体検知モデルを騙すことに成功しています。
本検証では、独自の道路標識認識モデルを作成し、これを騙すことができるステッカーのパターンを特定しています。以下の図は、時速35マイル速度制限標識にステッカーを貼ることで、独自モデルに時速45マイル速度制限標識として誤認識させた様子を表しています。
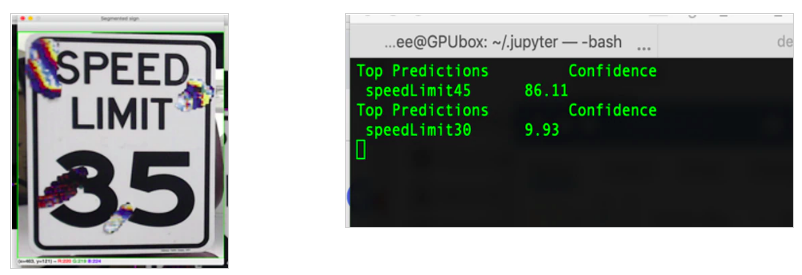 独自に作成した道路標識認識モデルを騙した様子
独自に作成した道路標識認識モデルを騙した様子(出典:Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles, McAfee blogs)
次に本検証では、「(敵対的サンプルの転移性により)独自モデルを騙すことができる敵対的サンプルは、他のモデルも騙すことができる」という仮説を立て、独自モデルを騙すことができる敵対的な道路標識を物体検知モデル「MobilEye」に提示する検証を行っています。
以下の図は、Tesla車に搭載したMobilEyeに敵対的な道路標識を提示した様子を表しています。
 実車を使用した検証
実車を使用した検証検証の結果、人間の目には時速35マイル速度制限標識に見える道路標識を、MobilEyeに時速85マイル速度制限標識として誤認識させることに成功しています。
このように、標的とするディープラーニング・モデルが手元にないブラックボックスの条件においても、敵対的サンプルの転移性を利用することで実機に対して攻撃を行うことが可能となります。
以上、自動運転車に対する攻撃検証事例でした。
多くの攻撃手法が存在することに驚かれた方も多いのではないでしょうか。攻撃検証はシミュレーション環境に留まらず、実環境にも拡張されており、現実的な脅威となる日もそう遠くはないでしょう。よって、敵対的サンプルを使用した回避攻撃の防御策を練ることは、喫緊の課題と言えるかもしれません。
防御手法
ここからは、回避攻撃の防御手法を見ていきましょう。
本ブログの引用論文「Deep Learning-Based Autonomous Driving Systems: A Survey of Attacks and Defenses」では、以下の図に示す防御フレームワークを提案しています。
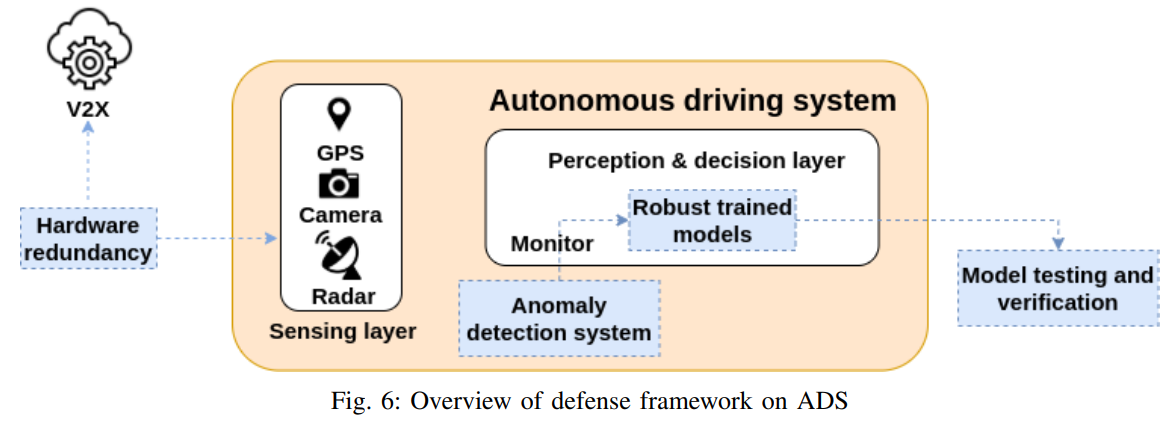 自動運転車における防御フレームワーク
自動運転車における防御フレームワーク(出典:Deep Learning-Based Autonomous Driving Systems: A Survey of Attacks and Defenses)
この防御フレームワークは「ハードウェアの冗長化(Hardware redundancy)」「堅牢なモデルの作成(Robust trained models)」「モデルのテストと検証(Model testing and verification)」「異常検知システム(Anomaly detection system)」の4つの戦略から構成されています。
本ブログのメインテーマであるディープラーニング・ベースの意思決定モデル(Perception & decision layer)の防御戦略は「堅牢なモデルの作成」「異常検知システム」「モデルのテストと検証」にあたります。意思決定モデルに入力される敵対的サンプルを検出することや、敵対的サンプルが入力された場合でも誤分類しない頑健なモデルを作成することは、回避攻撃から自動運転車を守る上で非常に重要となります。
以下、代表的な防御手法を、モデル自体の頑健性を高めることに重点を置いた「Proactive defenses」と、敵対的サンプルの検出・無効化に重点を置いた「Reactive defense」のアプローチに分けて解説していきます。
Proactive defenses
敵対的学習(Adversarial Training)
敵対的学習は、正常データと敵対的サンプルの特徴を学習する防御手法であり、J.Goodfellow氏らの論文「Explaining and Harnessing Adversarial Examples」で提案されました。正常データに加えて、敵対的サンプルの特徴を学習することで、敵対的サンプルがモデルに入力された場合でも、(誤分類せずに)正しいクラスに分類することができます。
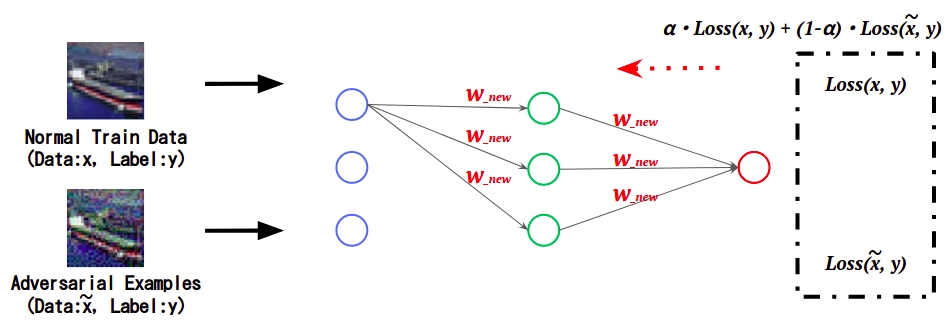 敵対的学習の概要
敵対的学習の概要(出典:ART超入門 第3回:Adversarial Training -回避攻撃の対策-)
しかし、敵対的学習したモデルを攻撃する手法も提案されています。例えば、F.Tramer氏らの論文「Ensemble Adversarial Training: Attacks and Defenses」では、敵対的学習したモデルを攻撃する新たな回避攻撃手法が提案されており、この攻撃の前では従来の敵対的学習は無力であることが示されています。
その後も、新たな敵対的学習の手法や、それを破る攻撃手法が次々と提案されており、AIセキュリティの中でもかなりホットなトピックであると言えます。
防御のためのネットワーク蒸留(Defensive Distillation)
防御のためのネットワーク蒸留は、層が深く複雑な学習済みモデルの入力と出力を、よりシンプルなアーキテクチャを持ったモデルに学習させる手法であり、N.Papernot氏らの論文「Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks」で提案されました。この手法で学習された新たなモデルは勾配の変化に対する感度が低くなるため、攻撃者は敵対的サンプルを作ることが困難になります。
しかし、その後発表されたN.Carlini氏とD.A.Wagner氏の論文「Towards Evaluating the Robustness of Neural Networks」では、ネットワーク蒸留したモデルを攻撃する新たな手法「Carlini & Wagner attack」が提案されています。
モデルのアンサンブル(Ensemble Method)
モデルのアンサンブルは、アーキテクチャの異なる複数のモデルを集約した「アンサンブル・モデル」を構築し、敵対的サンプルに対する頑健性を向上させます。T.Pang氏らの論文「Improving Adversarial Robustness via Promoting Ensemble Diversity」では、特性が大きく異なるモデルを集約するアプローチが提案されています。このようなアンサンブル・モデルを攻撃するためには、特性の異なる様々なモデルに有効な敵対的サンプルを作成する必要があるため、攻撃のハードルは高くなります。
Certified robustness
Certified robustnessは理論保証付きのモデルを作成する手法であり、入力データに加えられた摂動の量がある一定の範囲内であれば、これを正しいクラスに分類することを保証するというものです。Certified robustnessの手法は幾つか提案されていますが、M.Lecuyer氏らの論文「Certified Robustness to Adversarial Examples with Differential Privacy」では、「PixelDP」と呼ばれる手法が提案されています。
以下の図は、PixelDPのメカニズムを表しています。
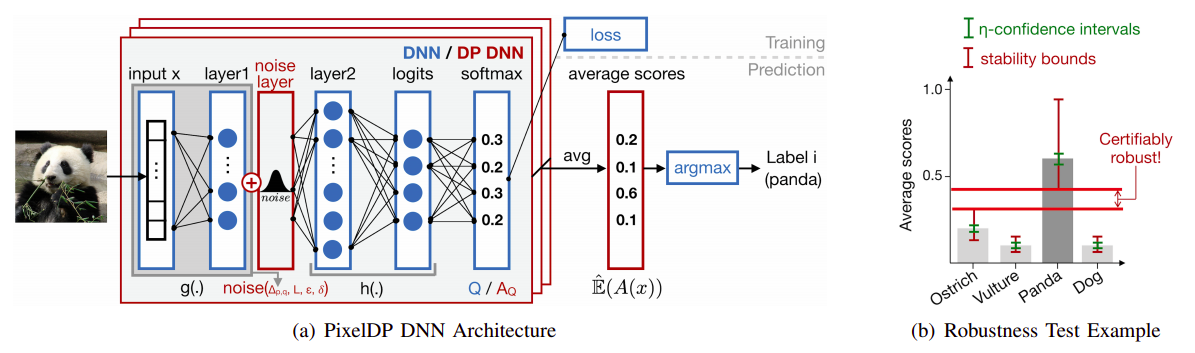 PixelDPのメカニズム
PixelDPのメカニズムPixelDPでは、モデル(DNN)の入力層または後続の中間層の何れかにノイズ層(noise layer)を追加します。ノイズ層は、入力データや(中間層が出力する)特徴表現にランダムな摂動を加える役割を果たし、入力データを正しいクラスに分類するために許容される摂動の量が測定されます。これにより、仮に敵対的サンプルがモデルに入力された場合でも、摂動の量が許容範囲内であれば、これを正しいクラスに分類することができます。
Reactive defense
Intrinsic-defender(Idefender)
Intrinsic-defender(Idefender)は敵対的サンプルを検出する防御手法であり、Z.Zheng氏らの論文「Robust Detection of Adversarial Attacks by Modeling the Intrinsic Properties of Deep Neural Networks」で提案されました。Idefenderは、モデルの中間層が出力する特徴表現の分布を探索し、敵対的サンプルを検出します。
以下の図は、あるモデルの特徴表現の分布例を表しています。
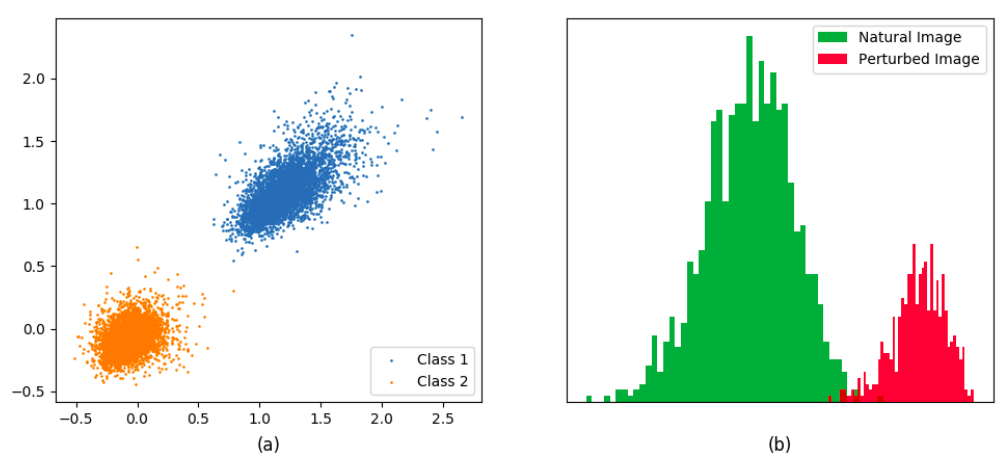 正常データと敵対的サンプルの特徴表現
正常データと敵対的サンプルの特徴表現(出典:Robust Detection of Adversarial Attacks by Modeling the Intrinsic Properties of Deep Neural Networks, NeurIPS 2018)
上の図の(b)は、モデルが正常な飛行機画像を正しく飛行機クラスに分類した場合の特徴表現の分布(緑)と、敵対的サンプルを飛行機クラスに誤分類した場合の特徴表現の分布(赤)を表しています。このように、同じ飛行機クラスに分類される入力データであっても、正常なデータと敵対的サンプルとでは、分布が大きく異なることが分かります。Idefenderは、このような分布の違いを利用して敵対的サンプルを検出します。
Feature Squeezing
Feature Squeezingは、入力画像の各画素のカラービット深度を絞ることで敵対的サンプルを検出する防御手法であり、W.Xu氏らの論文「Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks」で提案されました。
以下の図は、Feature Squeezingによってカラービット深度が絞り込まれた画像を表しています。
 ビット深度が絞り込まれた画像例
ビット深度が絞り込まれた画像例(出典:Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks, arXiv.org)
この図は、上段からデータセット「MNIST」「CIFAR10」「ImageNet」のサンプルを表しており、左から右に8bit〜1bitにカラービット深度を絞り込んでいます。このように、カラービット深度を絞ることで、画像に含まれるノイズが除去され、併せて摂動も除去されることが期待されます。
以下の図は、Feature Squeezingを使用して敵対的サンプルを検出するメカニズムを表しています。
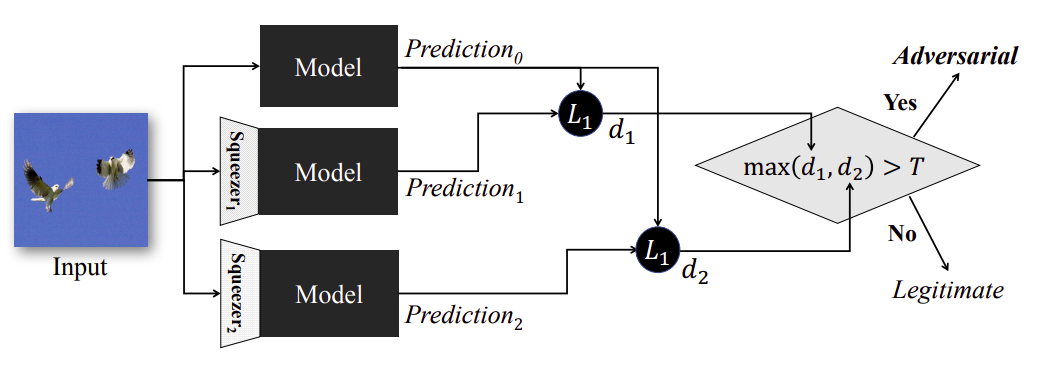 敵対的サンプルを検出するメカニズム
敵対的サンプルを検出するメカニズム(出典:Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks, arXiv.org)
Squeezingされた入力画像と、Squeezingされていない入力画像をそれぞれモデルに分類させ、その結果の差異が閾値を超えた場合、入力画像を敵対的サンプルと判断します。
敵対的変換
敵対的変換は敵対的サンプルに変換を施し、(誤分類を引き起こさない)正常な画像に再構築するアプローチであり、様々な手法が提案されています。例えば、P.Samangouei氏らの論文「Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models」では、Defence-GANと呼ばれるフレームワークが提案されています。
Defense-GANは(摂動が加えられていない)データセットの分布をモデル化するようにGANを学習し、その分布内から摂動のない新たな画像を生成します。Defence-GANでは、モデルに敵対的サンプルが与えられると、敵対的サンプルと距離が近い画像を多数生成し、その中から元画像と距離が近い画像を選択してモデルに入力します。なお、Defense-GANで生成された画像は敵対的サンプルと類似しているものの、データセットの分布から新たに生成されたものであるため、摂動は含んでいません。
以下の図は、敵対的サンプルを基にDefense-GANで生成した画像例を表しています。
 Defense-GANで生成した画像例
Defense-GANで生成した画像例(出典:Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models, arXiv.org)
図の左からオリジナルの画像(Original)、敵対的サンプル(Adv)、Defense-GANで生成した画像(距離毎に並べている)を表しています。見て分かるとおり、Defense-GANで生成された画像はオリジナルの画像と類似しており、また、(Advで見られるノイズのような)摂動も含んでいないことが分かります。
このように、事前に摂動のないデータセットの分布をモデル化し、敵対的サンプルと距離の近い画像を生成して分類に使用することで、敵対的サンプルを無効化することができます。
以上、回避攻撃の防御手法を幾つか見てきました。
なお、防御手法を破る攻撃手法は常に生み出されていますので、一つの防御手法のみを採用するのではなく、自動運転車に搭載されている意思決定モデルの特性に合わせて、複数の防御手法を組み合わせる多層防御の観点が重要であると言えます。
さいごに
本ブログでは、自動運転車に搭載される意思決定モデルに対する回避攻撃と防御手法を紹介しました。
意思決定モデルに対する回避攻撃は多岐にわたり、現実的な脅威となり得る攻撃手法も数多く存在することが分かりました。また、攻撃はシミュレーション環境のみならず、実世界でも有効であり、自動運転車の運転操作(加速、操舵、制動)に影響を与えることが分かっています。
特に、路肩の看板や道路標識、路面に細工を施すタイプの回避攻撃はステルス性が高く、誰にも気づかれることなく長期間に渡って攻撃が継続される可能性もあります。また、事故が発生した際も、その原因究明は困難になるものと思われます。
回避攻撃の防御手法は盛んに研究が行われていますが、防御手法を上回る攻撃手法も次々と生まれているため、しばらくはイタチごっこの関係が続くと思われます。よって、常に最新の攻撃手法と防御手法を追いながら、なるべく多層防御の観点で意思決定モデルを守る必要があるでしょう。
本ブログはこれで終了となります。
次回は「第5回:意思決定モデルに対する敵対的攻撃 - 汚染攻撃 -」となります。
AIセキュリティのトレーニング
弊社は株式会社ChillStackと共同で、AIの開発・提供・利用を安全に行うためのトレーニングを提供しています。
本トレーニングでは、ディープラーニング・モデルに対する様々な攻撃手法(汚染攻撃・回避攻撃など)とその対策を、ハンズオントレーニングとeラーニングを通じて理解することができます。
本トレーニングの詳細やお問い合わせにつきましては、弊社窓口、または、AIディフェンス研究所をご覧ください。
AIディフェンス研究所
最後までご覧いただき、誠にありがとうございました。
以上
おすすめ記事









