本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。
最近、DeepFake(ディープフェイク)という言葉がしばしばメディアでも取り上げられていますが、その仕組みや対策をご存じでない方も多いのではないでしょうか。そこで本ブログでは、DeepFakeの仕組みと対策を「動画編」と「音声編」の2回に分けて解説することにします。
今回は「動画編」と題し、DeepFakeを使用したフェイク動画の仕組みと、これを見破る方法について解説いたします。
1. DeepFake?
DeepFakeとは、動画に写っている人物(オリジナル)の顔に他人の顔(ターゲット)をマッピングする技術の総称であり、オリジナルとターゲットの顔の特徴をDeep Learningで学習することで実現します。この技術を使用することで、ターゲットが一切写っていない動画の中に、あたかもターゲットが存在するかのようなフェイク動画を作成することが可能となります。
以下は、今回の検証で作成したフェイク動画です(画像をクリックするとYouTubeに移動します)。
 本検証で作成したフェイク動画
本検証で作成したフェイク動画Realとキャプションされた左の動画は、筆者が周りを見渡しながら喋っているオリジナルの動画です。一方、Fakeとキャプションされた右の動画は、同僚Aの顔を筆者の顔にマッピングしたフェイク動画です。
ここで、同僚Aの顔は以下のとおりです。上記のFakeと見比べてみると、目や鼻、口などの特徴がほぼ一致していることが分かるかと思います。
 同僚Aの顔
同僚Aの顔このように、DeepFakeを使用することで、真実と見紛うようなフェイク動画を作成することが可能となります。
DeepFakeはエンターテインメントなどでの利用が見込まれる一方、ターゲットの評判を貶めるための動画や政治的なプロパガンダ、ポルノや詐欺などへの悪用が問題となっています。
そこで、本ブログではDeepFakeの概要を解説した上で、フェイク動画を見破る方法を解説します。本ブログが、DeepFakeを理解するための一助になれば幸いです。
2. DeepFakeの仕組み
DeepFakeの理論や詳解は既に多くのブログや論文に書かれていますので、本ブログでは今回の検証で作成したフェイク動画の作成手順を簡単に解説するに留めます。
2.1. 事前準備
フェイク動画を作成するためには、オリジナル(=筆者)とターゲット(=同僚A)の顔をDeep Learningで学習させる必要があります。このため、学習用の顔画像を大量に収集します。
2.1.1. 同僚Aの画像収集
同僚Aの顔はGoogle検索やFacebookなどから収集しました。
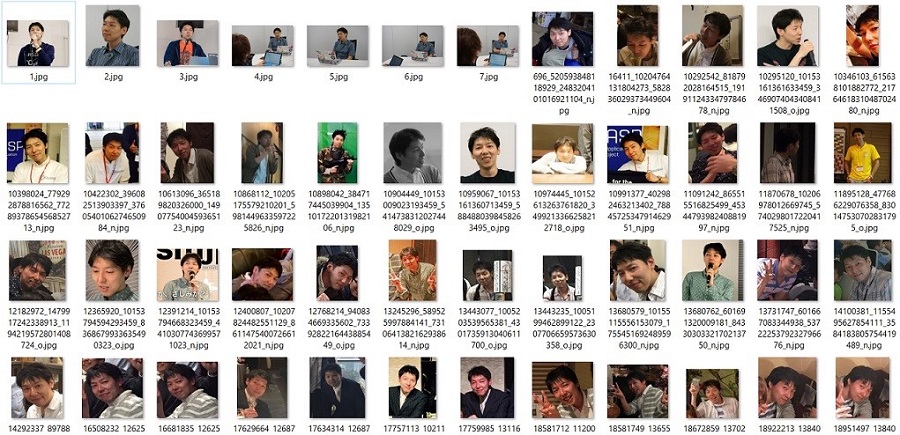 SNSなどから収集した同僚Aの画像
SNSなどから収集した同僚Aの画像同僚Aは様々なイベントやカンファレンスで登壇していますので、約90枚もの画像を収集することができました。しかし、90枚程度では学習データとして少なく、上手く学習できない可能性が高いため、更に画像を収集する必要があります。
大量の顔画像を収集する上で役立つのが動画です。なぜならば、動画にはターゲットの様々な表情や様々な角度の顔が含まれているからです。そこで、今回は検証用に弊社会議室で撮影した同僚Aの動画(約1分間)から、30fps(30フレーム/1秒)で画像を抽出しました(抽出にはFFmpegを使用)。
 動画から抽出した同僚Aの画像
動画から抽出した同僚Aの画像1分間の動画から約1,800枚の画像を得ることができました。
なお、今回は利用していませんが、ターゲットが写った動画がYouTubeなどで公開されている場合は、そこからも顔画像を抽出することが可能です。すなわち、メディアへの露出が多い人ほどフェイク動画を作られやすい、と言えます。
2.1.2. 筆者の画像収集
同様に筆者の画像も収集します。
手元にある自分が映り込んだ写真と、自撮りした動画から画像を抽出し、約1,000枚の画像を得ることができました。
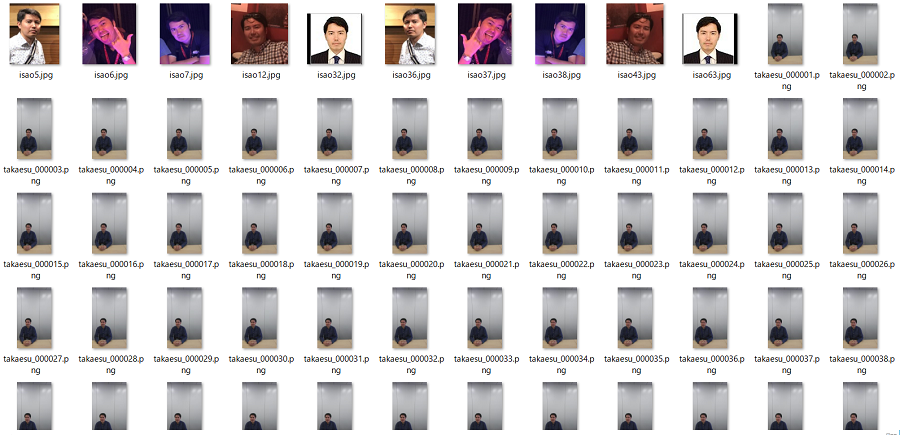 収集した筆者の画像
収集した筆者の画像2.1.3. 顔の抽出
学習の対象は顔になりますので、収集した画像から顔のみをクリッピングします。今回の検証ではOpenCVを使用して顔のクリッピングを行いました。
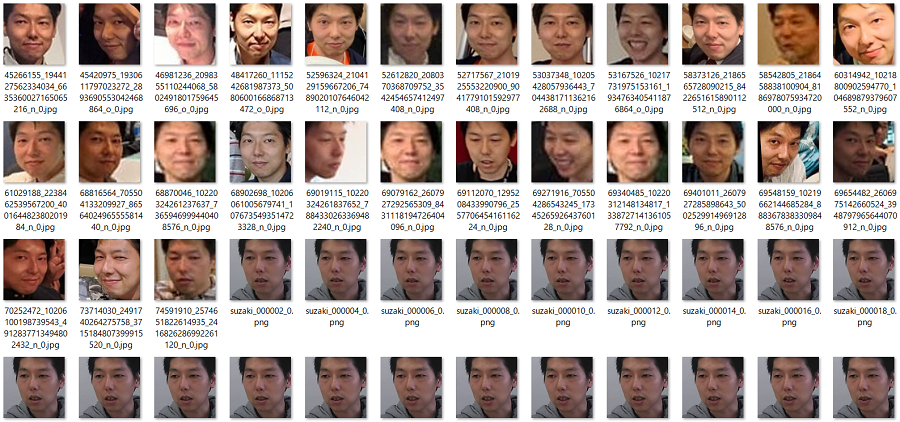 クリッピングした同僚Aの顔画像
クリッピングした同僚Aの顔画像同様に筆者の顔もクリッピングします。
 クリッピングした筆者の顔画像
クリッピングした筆者の顔画像これで学習データが整いましたので、いよいよ顔の学習を行います。
2.2. フェイク動画の作成
2.2.1. 顔の特徴を学習する
オリジナルとターゲットの顔をDeep Learningで学習します。
フェイク動画を作成するDeep Learningモデルは複数存在しますが、今回の検証では以下のモデルを使用しました。
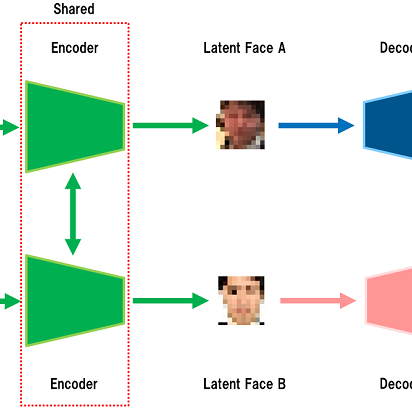
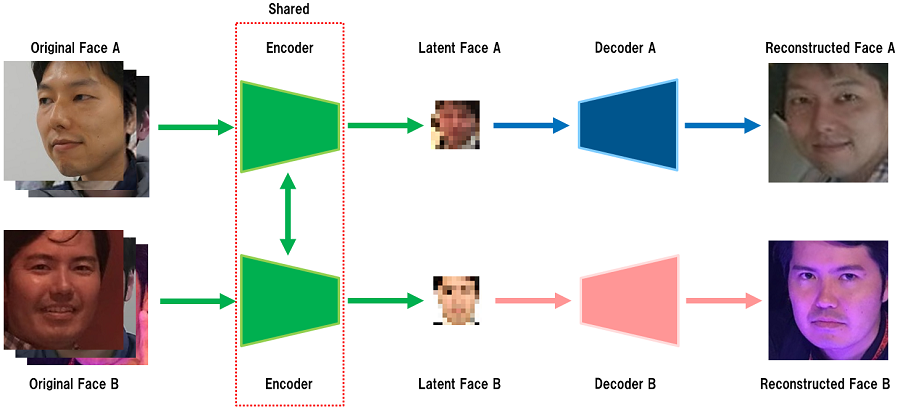 学習に使用したモデルの概要図
学習に使用したモデルの概要図ここで重要になるのが「Encoder」と「Decoder」です。Encoderは入力データ(Original Face)から特徴を抽出して低次元の情報(Latent Face)に変換し、Decoderは低次元の情報からデータを復元(Reconstructed Face)する能力を持ちます。様々な学習データ(顔画像)を入力にして上記の処理を繰り返すと、Encoderは入力された顔画像から特徴を抽出する能力が高まり、Decoderは特徴から顔を再構成する能力が高まります。
今回の検証では、同僚Aと筆者の顔を共有された同じEncoderに入力し、Encoderから出力された顔の特徴を別々のDecoder(A, B)に入力して顔を再構築させることで学習を行いました。ここで、「Encoderは共有」、「Decoderは別々」がフェイク動画を作成する上でのポイントになります。
次に、同僚Aの顔を筆者の顔にマッピングする仕組みを見ていきましょう。
2.2.2. 顔のマッピング
以下は、同僚Aの顔を筆者の顔にマッピングするモデルです。
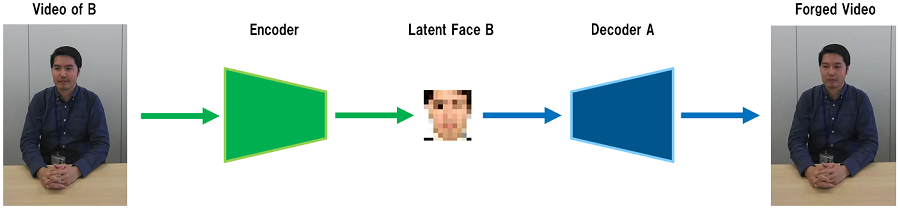 顔をマッピングするモデル
顔をマッピングするモデルEncoderに筆者の動画(Video of B)を入力すると(厳密には動画から30fpsで抽出した画像を1枚ずつ入力)、Encoderは筆者の顔の特徴(Latent Face B)を出力します。そして、この特徴を同僚Aの学習に使用したDecoder Aに入力します。すると、入力動画は筆者にも関わらず、顔部分が同僚Aに置き換わった動画(Forged Video)が出力されます!(厳密には、Decoderが再構成した画像を1枚ずつ繋ぎ合わせて動画を作成)。
Encoder/Decoderは特に目新しい仕組みではありませんが、上記のようにEncoder/Decoderを上手く組み合わせることで、筆者の顔に同僚Aの顔がマッピングされたフェイク動画を容易に作成することが可能となります。
2.2.3. 作成したフェイク動画
今回の検証で作成したフェイク動画を幾つか紹介します。
以下は、冒頭でも紹介した同僚Aの顔を筆者の顔にマッピングした動画です。
 フェイク動画(筆者 -> 同僚A) ※クリックするとYouTubeに移動
フェイク動画(筆者 -> 同僚A) ※クリックするとYouTubeに移動同僚Bと同僚Cにも協力してもらい、同じ要領でフェイク動画を作成しました。
 同僚B(左)と同僚C(右)の顔
同僚B(左)と同僚C(右)の顔 同僚Cの顔を同僚Bにマッピング(クリックするとYouTubeに移動)
同僚Cの顔を同僚Bにマッピング(クリックするとYouTubeに移動) 同僚Bの顔を同僚Cにマッピング(クリックするとYouTubeに移動)
同僚Bの顔を同僚Cにマッピング(クリックするとYouTubeに移動)このように、オリジナルとターゲットの顔を入れ替えた自然なフェイク動画を作成することができました。
3. フェイク動画の検知
ここではフェイク動画を検知する方法を幾つか紹介します。
なお、今現在も新たな検知手法が研究されていますので、ここで紹介する手法は一例であることにご注意ください。
3.1. 瞬きの有無
「瞬きの有無」で検知する手法です。
多くのフェイク動画は瞬きをしないと言われています。フェイク動画を作成するためにはターゲットの顔の学習が必要なため、フェイク動画で瞬きを再現するためには「ターゲットが瞬きをしている画像」を学習データに含める必要があります。しかし、通常、瞬きをしている画像を収集することは困難です。なぜならば、瞬きは一瞬の出来事なので写真に撮り難いこと、そして、目を閉じている画像は公開されにくいことなどが理由として挙げられます。これらの理由により、学習データの中に瞬きをしている画像が存在しない、または極度に少ない場合、まったく瞬きをしない不自然なフェイク動画が出来上がります。
以下は、アメリカのAlbany 大学の研究者らがフェイク動画の「瞬きの有無」を検証した結果を示しています。
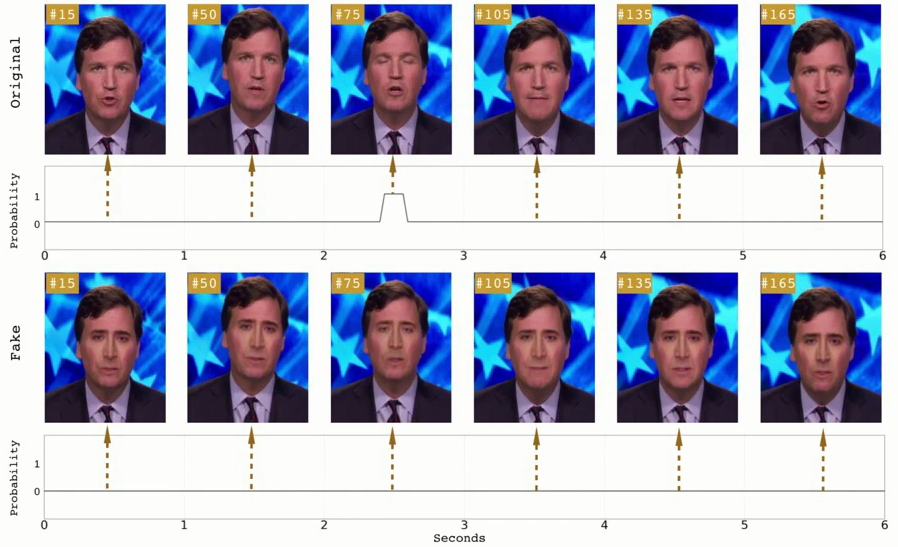 瞬き有無の比較(出典:In Ictu Oculi)
瞬き有無の比較(出典:In Ictu Oculi)上段のオリジナル動画は75フレーム目で瞬きをしています。一方、下段のフェイク動画は瞬きをしていません。彼らはこの瞬きの有無を検知するDeep Learningモデルを開発し、フェイク動画の検知を試みています。
しかし、本検証で作成したフェイク動画では、以下のように瞬きをしています。何故でしょうか?
 フェイク動画の中で同僚Aが瞬きをしている様子
フェイク動画の中で同僚Aが瞬きをしている様子本検証で使用した学習データには「同僚Aの動画から30fpsで抽出した画像」が含まれています。動画の中で同僚Aは何度も瞬きをしているため、学習データには瞬きの画像も多く含まれます。このように、学習データを充実させることで、フェイク動画で瞬きを実現することは可能となります。
上記の理由により、本手法によるフェイク動画の検知精度は、フェイク動画の作り手(DeepFaker)のスキルに依存すると言えます。
3.2. 顔のチラつき
「顔のチラつき」で検知する手法です。
フェイク動画では、顔とその周りの部位(髪、首など)が交わる箇所がチラつく場合があります。以下は、今回の検証で作成した同僚Bのフェイク動画にて、顔の周りがチラついている様子です。
 顔の周りがチラついている様子
顔の周りがチラついている様子右眉や口元、顎がチラついていることが分かります。今回の検証では、ターゲットの顔をマッピングする領域が髪で隠れている、顎周りの形状がオリジナルとマッチしない場合などに、チラつきが顕著に表れることが分かりました。また、今回は試していませんが、眼鏡をかけたフェイク動画を作成する場合などは、眼鏡のフレームのズレが顕著になると考えられます。
しかし、多少のチラつきはノイズベースのぼかしを入れることでマスクすることができます。また、動画の画質が悪い場合も同様にチラつきはマスクされます。実際に、同僚Bのフェイク動画を画質144pまたは240pで再生すると、チラつきは殆ど気にならなくなります。よって、本手法によるフェイク動画の検知は動画の画質に依存すると言えます。
3.3. 口腔の再現度
「口腔の不自然さ」で検知する手法です。
今回の検証で作成したフェイク動画は、Encoder/Decoderを組み合わせたモデルで作成されています。ここで、口腔は他の顔の部位と比較すると小型で複雑であり、フェイク動画を作成するモデルの精度次第では口腔が変形し、ぼやけた動画が生成される場合があります。以下は、今回の検証で作成した同僚Cのフェイク動画にて、口腔がぼやけている様子です。
 口腔がぼやけている様子
口腔がぼやけている様子本来は歯の1本1本がクリアに見えるべきところ、ぼやけることで白い1つのフラットな物体に見えることが分かります。
しかし、フェイク動画作成モデルの再現精度を向上させる研究は盛んに行われているため、本手法は近い将来陳腐化する可能性があります。また、モバイル用途のように容量を抑えた低解像度の動画の場合は、口腔の不自然さは目立たなくなる可能性も考えられます。実際に、同僚Cのフェイク動画を画質144pまたは240pで再生すると、口腔の不自然さは殆ど気にならなくなります。よって、本手法によるフェイク動画の検知も確実性は無いと、筆者は考えます。
3.4. 動画の再生時間
「動画の再生時間の長さ」で検知する手法です。
フェイク動画を作成するためには潤沢なリソースと時間が必要になるため、長時間のフェイク動画は作成し難しいと言われています。この制約により、フェイク動画の再生時間は短くなる傾向があります。今回の検証では、それなりに高性能なゲーミングPC(CPU:Intel Core i7-6500U 2.50GHz、GPU:GeForce GTX 965M、メモリ:16.0GB)を使用して同僚Bのフェイク動画(再生時間:1分30秒、フレーム幅:1080、フレーム高:1106、fps:30)を作成するにあたり、約12時間もの時間を費やしました。
見た目が怪しく、文脈に沿わない短時間の動画が提示された場合は怪しんだ方が良いかもしれません。しかし、潤沢なリソースを持ったDeepFakerも存在します。また、フェイク動画を作成するサービスも存在するため、本手法によるフェイク動画の検知もDeepFakerのスキルやリソースに依存し、確実性は無いと筆者は考えます。
3.5. ノイズパターンの分析
これまでの検知手法は、DeepFakerのスキル不足やリソース不足により生じた「綻び」に依存する手法でした。これらとは異なるアプローチとして、Koopman氏らが提案した画像のPRNU(Photo Response Non-Uniform)パターンを分析する手法があります。
PRNUパターンとは、デジタルカメラの感光センサ内の欠陥によって生じる独自のノイズパターンであり、カメラ毎にそのパターンが異なることから「画像の指紋」と言われています。フェイク動画はオリジナル動画の顔部分を置き換えたものとなるため、「顔部分」と「それ以外」のPRNUパターンが異なる場合があります。この手法では、顔部分とそれ以外の部分のPRNUパターンの類似度を分析することで、フェイク動画の有無を判定します。以下は、Koopman氏らが検証した、フェイク動画とオリジナル動画のPRNUパターン分析の結果を示しています。
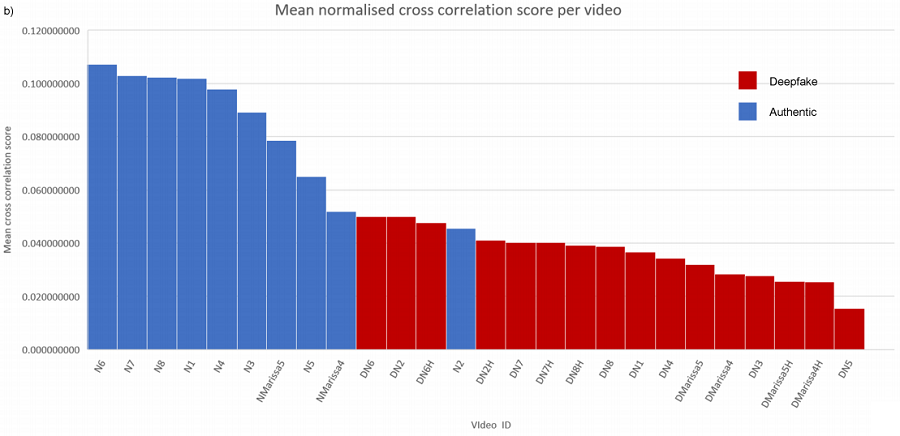 PRNU分析の結果(出典:Detection of Deepfake Video Manipulation)
PRNU分析の結果(出典:Detection of Deepfake Video Manipulation)グラフの縦軸はPRNUパターンの類似度、横軸は検証した動画(青=オリジナル動画、赤=フェイク動画)を示しています。上記の通り、オリジナル動画はPRNUパターンの類似度が高く、フェイク動画は低い傾向にあることが分かるため、これを基にフェイク動画の有無を判定します。しかし、検証した動画の本数が少ないことや、ノイズが多く含まれた(劣化した)フェイク動画を検知できるのかは未知数です。
本ブログで紹介する対策は以上となります。
各検知手法には一長一短がありますので、現状では単一の検知手法に依存するのではなく、複数の手法で総合的にフェイク動画の有無を判定した方が良いと考えます。また、今回紹介した手法以外にも、フェイク動画の口腔に着目してフェイク動画を見破るモデル「DeepStar」や、Deep Learningモデルの中間層における目の表現(Mesoscopic)に着目してフェイク動画を見破るモデル「MesoNet」なども存在します。ご興味のある方は試してみることをお勧めいたします。
4. さいごに
本ブログでは、DeepFakeを使用したフェイク動画の仕組みと見破る方法について解説しました。
今回の検証では、簡単なモデルと一般的なゲーミングPCを使うことで、簡単にフェイク動画を作成できることを確認しました。また、フェイク動画を検知する手法は既に多く提案されていますが、各手法には一長一短の特徴があることが分かりました。
なお、FacebookやAWS、Googleなどの企業もフェイク動画検知技術の開発に積極的に乗り出しています。FacebookやAWSは、フェイク動画検知技術のコンペティション「Deepfake Detection Challenge(DFDC)」を開催しています。また、Googleはフェイク動画検知モデルの開発を支援するフェイク動画データセットを公開しています。
このように、様々な組織が検知技術の開発に乗り出していますが、これまでのサイバーセキュリティにおける攻撃/防御技術の歴史を鑑みると、検知技術とフェイク動画作成技術は「いたちごっこ」の関係が暫くは続くと考えられます。
これまで筆者は、動画によるエビデンスは信頼性が高いと考えていましたが、DeepFakeの普及により、それは瓦解したと考えています。今後、日本においてもフェイク動画が犯罪などに悪用される可能性がありますので、フェイク動画作成技術と検知技術の研究動向を常にウォッチしていきたいと考えています。
なお、今回はDeepFakeを使用したフェイク動画について解説しましたが、次回は実際に詐欺にも使われたというフェイク音声について解説する予定です。
以上


