本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。
この1~2年の間に機械学習を使用したサービスやプロダクトが数多くリリースされています。それと同時に、機械学習モデルに対する攻撃手法も多く発表されています[1] [2] [3]。
本ブログでは、EPFLのFlorian氏らが発表した論文「Stealing Machine Learning Models via Prediction APIs」から「Model Extraction Attacks」と呼ばれる機械学習モデルに対する攻撃手法の一例を紹介します。
Model Extraction Attacks
「Model Extraction Attacks」とは、機械学習サービス(ML Service)に対する入力値と、それに対応する出力値を基に、ML Serviceで使用しているMLモデル(Logistic Regression、Multilayer Perceptron、Decision Tree等)を「複製」する攻撃です。
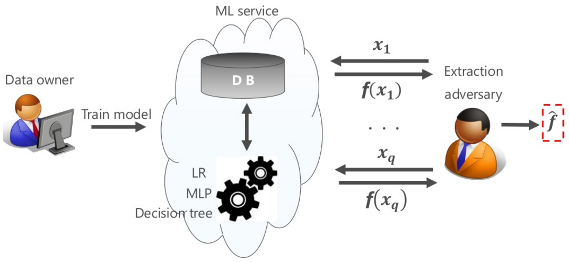
上図は、Data ownerが提供するML Serviceに対し、攻撃者(Extraction adversary)がブラックボックスアクセスを行い、MLモデル「f」を複製(赤い波線部分)している様子を表しています。攻撃者はML Serviceに対して複数のデータ「x1 … xq」を入力し、各入力に対するML Serviceからの出力「f(x1) … f(xq)」を得ます。そして、複数の入力値と出力値を手掛かりに、モデル内部のロジック(方程式)を解いていくことで、MLモデルの複製を行います(詳細は後述)。
MLモデルが複製された場合、Data ownerにとって以下の問題が生じます。
- 課金回避による収益悪化
(MLモデルに対する)利用者からの入力(クエリ)単位に課金し、MLモデルの訓練コストの回収、および、収益を得るビジネスモデルを展開している場合、MLモデルが複製されることで正規のMLモデルに対するクエリ数が減少し、収益が悪化する。 - 訓練データからの情報漏えい
MLモデルの訓練に使用した訓練データが漏えいする。訓練データに機密情報が含まれている場合は、機密情報が漏えいする。 - 振る舞い検知の回避
MLモデルがスパム検知・マルウエア検知・N/W異常検知等に使用されている場合、攻撃者にMLモデルが複製され、検知ロジックが明らかにされることで、これらの検知機構が回避される。
Florian氏らは、Model Extraction Attacksを実現する手法として、MLモデルの種類や振る舞いに応じて以下に示す複数の攻撃手法を提案しています。
- Extraction with Confidence Values
MLモデルが「Class」と「Confidence Values」を応答する場合:- Equation-Solving Attacks
- Decision Tree Path-Finding Attacks
- Online Model Extraction Attacks
- Extraction Given Class Labels Only
MLモデルが「Class」のみ応答する場合:- The Lowd-Meek Attack
- The retraining approach
本ブログでは、上記の「Extraction with Confidence Values」から「Equation-Solving Attacks」の紹介と、実際に検証した結果を示します。その他の手法は、次回以降のブログで順次紹介していく予定です。
Equation-Solving Attacks
Equation-Solving Attacksとは、MLモデルへの入力データ「x, y」と、MLモデルからの出力「f(x, y)」を基に、攻撃者によって未知のロジック(方程式)である「f(x, y) = “?????”」を複製する攻撃です。
例えば、とあるMLモデル「Binary Logistic Regression(※)」では、入力したデータ「x, y」を2クラス分類するために、以下の方程式を使用しているとします。
(※) ロジックの簡単な説明は「付録A:Binary Logistic Regression」に記載。
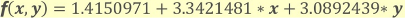
当然ながら、上記の方程式はMLモデルの訓練を行ったData ownerのみ知り得る情報であり、攻撃者を含む利用者にとってはブラックボックスになります。もちろん、方程式の係数(1.4150971、3.3421481等)は知る由もありません。
しかし、利用者はMLモデルの挙動(データが2クラスに分類される)を観察することで、MLモデルが内部で利用している機械学習アルゴリズムは「Binary Logistic Regression」であると推測することができます。そして、この事実から、係数は未知であるものの、以下の方程式の形までは容易に推測することができます。

そして、攻撃者は自身が知り得る複数の入力値「x, y」と、MLモデルから得られる出力値「f(x, y)」を基に、未知の係数「w0, w1, w2」を特定していく作業を行います。すなわち、方程式を解いていきます。この作業を複数回行い、未知の係数「w0, w1, w2」を一つずつ特定していくことで、MLモデルがデータ分類に使用している方程式を複製します。
Binary Logistic Regressionに対する攻撃
本ブログでは、MLモデル「Binary Logistic Regression」を検証対象とします。
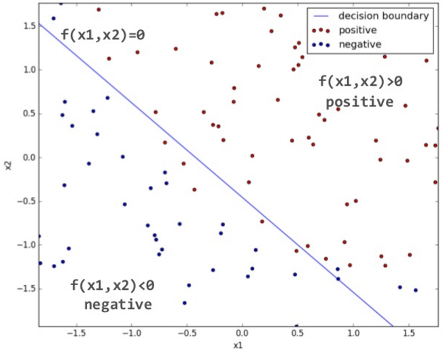
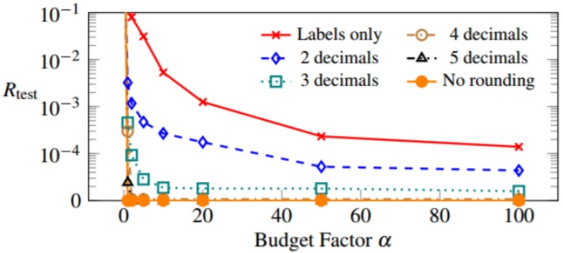
Binary Logistic Regressionに対するEquation-Solving Attacksを検証するために、今回は検証用のMLモデルを構築しました。検証用のMLモデルは、PRMLに収録されているテスト用のデータセット「ex2data1」を使用して学習を行いました。このデータセットには以下のような2種類のデータ(赤丸、青丸)が含まれています。
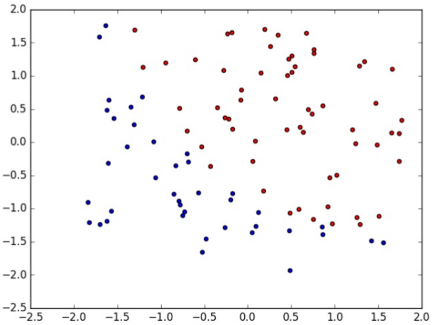
各データは二値(x1, x2)で構成されており、データは2クラスとなります(赤丸 = positive、青丸 = negative)。この訓練データを基にMLモデルを学習させると、2クラス分類を行うための方程式として以下が得られます(小数点4位以下は省略)。
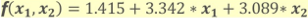
この方程式を使用することで、下図の通りDecision boundaryの右上の領域はクラス「positive」、左下の領域はクラス「negative」というように、データを2クラスに分類できるようになります。
この検証用MLモデルの利用イメージは以下の通りです。
利用者(User)は分類させたい任意のデータ「x1, x2」をMLモデルに入力します。すると、MLモデルは事前の学習で得られた上記の方程式を基に、入力されたデータが所属するクラス(positive / negative)と、そのクラスに所属する確率「P」を応答します。
下図は、利用者がデータ「x1, x2」を入力すると、その結果としてクラス「negative」・確率「94.5%」(1-P)が応答された様子を示しています。確率が非常に高いため、データ「x1, x2」はほぼ間違いなくクラス「negative」であると判断することができます。
同じように利用者がデータ「xq1, xq2」を入力すると、結果としてクラス「positive」・確率「99.6%」(P)が応答されます。こちらも確率が非常に高いため、ほぼ間違いなくデータ「xq1, xq2」はクラス「positive」であると判断することができます。
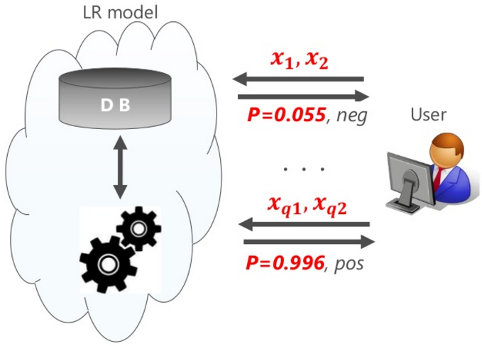
このように、利用者は分類させたい手元のデータをMLモデルに入力することで、データの「分類結果」とその「確率」を得ることができます。
次に、攻撃者(adversary)がMLモデルを「複製」する様子を下図に示します。
攻撃者は複数の入力データ(x1, x2 … xq1, xq2)と、それに対してMLモデルから応答されるクラスに所属する確率「P(0.055)、P(0.996)」を手掛かりにして方程式を解いていきます。そして、最終的に方程式の未知の係数「w0, w1, w2」を特定します。
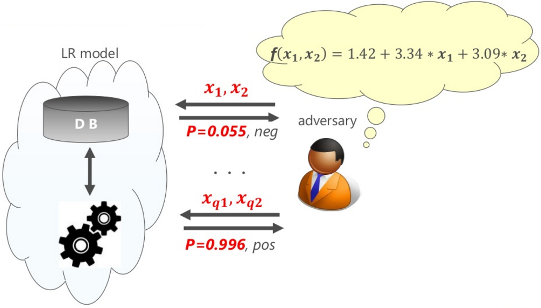
以下、攻撃の流れを具体的に説明します。
攻撃者がMLモデルに対して複数のデータを入力した場合、以下のような情報がMLモデルから応答されたとします。
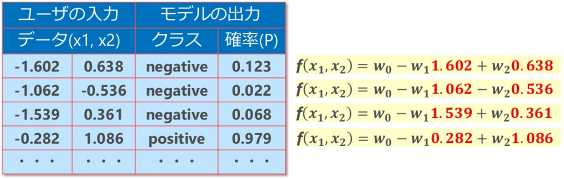
この時点では、方程式の右辺「x1, x2」のみが特定されます(上図の赤字部分)。係数「w0, w1, w2」は依然として未知のままです。
ここで、未知の係数「w0, w1, w2」を求めるためには、方程式の左辺「f(x1, x2)」の値を特定する必要があります。MLモデルから応答される値は、通常は分類結果のクラス(positive / negative)と、そのクラスに属する確率(P)のみであるため、このままでは左辺を特定することはできません。
ここで、付録Aに記載しているとおり、MLモデルから応答される確率「P」の値は、方程式の出力「f(x1, x2)」をロジスティック関数で0-1空間の値に写像したものとなります。よって、その逆の計算を行えば、確率「P」を方程式の左辺「f(x1, x2)」に変換することができます。なお、この変換は、ロジスティック関数の逆関数であるロジット関数を使用することで簡単に行うことができます。
下図は、ロジット関数に確率「P」を代入し、方程式の左辺を特定した様子を示しています(赤字部分)。
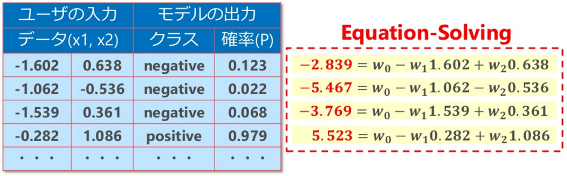
後は上記の連立方程式を解くことで、未知の係数「w0, w1, w2」を求めることができます。本例で求めた係数は以下の通りです。
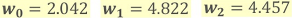
この特定した係数を方程式に当てはめることで、攻撃対象のMLモデルが分類に使用している方程式を以下のように求めることができます。これで、MLモデルの複製は完了です。

このように、MLモデルに数回程度アクセスした結果を基に、簡単な計算を行うことで、容易にMLモデル「Binary Logistic Regression」を複製できることが分かりました。
複製モデルの検証
正しくMLモデルが複製できたのかを確認するために、複製したMLモデルを使用し、オリジナルモデルと同じように2クラス分類が行えるのか検証します。検証は、テスト用の分類対象データ(100個)に対し、オリジナルモデルと複製モデルでそれぞれ2クラス分類結果を求め、結果の一致度合を求めます。
参考情報として、オリジナルモデルと複製モデルで分類に使用する方程式を以下に示します。
- オリジナルのモデル
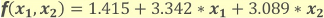
- 複製したモデル
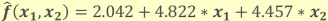
以下、二つのモデルを使用した分類結果を示します。分類対象のデータ数は多いため、一部の結果のみ抜粋して掲載しています。
この結果から分かる通り、オリジナルモデルと複製モデルは分類結果が完全に一致していることが分かります。今回は100個のテストデータを分類しましたが、分類結果は100%一致することを確認しました。
このように、Equation-Solving Attacksを使用することで、攻撃対象のMLモデル「Binary Logistic Regression」に近似したモデルを複製できることが分かりました。
対策
Equation-Solving Attacksを防ぐためにはどうすれば良いでしょうか?
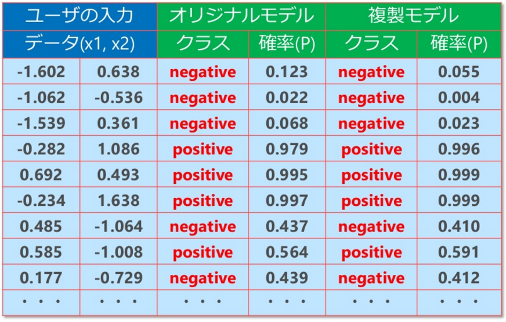
Florian氏らは「Rounding confidences」という対策を提案しています。これは、MLモデルが応答するConfidence Values(確率「P」)を丸めることで、Equation-Solving Attacksの精度を下げるというものです。
下図はConfidence Valuesを小数点第2位(2 decimals)から第5位(5 decimals)以下を切り捨てた場合と、全く丸めなかった場合(No rounding)の複製精度を示しています。なお、グラフの縦軸(Rtest)は、オリジナルモデルと複製モデルの分類精度の一致度合を表しており、下に行くほど分類誤差が少ない(精度が近似している)ことを示しています。また、横軸(Budget Factor)は複製の試行コストを示しています。
対策の効果(論文からの抜粋)
No roundingや4 decimals / 5 decimalsは、試行の早い段階でオリジナルモデルと精度が近似することが分かります。3 decimalsは精度がNo roundingよりも劣るものの、試行の早い段階でオリジナルモデルに近似していることが分かります。一方、2 decimalsは精度の近似速度は緩やかであり、また、その精度もBudget Factor「50」あたりから横ばいになっていることが分かります。これは、ある程度はオリジナルモデルと近似するものの、一定以上の精度は出ないことを意味しています。
この結果から、Confidence valuesを丸めることで攻撃の影響を緩和できることが分かりました。よって、MLモデルが応答する確率「P」は、必要以上の精度(0.59175345等)は出さず、必要最低限の精度(0.59等)にすることで、Equation-Solving Attacksへの耐性を高めることができると言えます。
まとめ
今回は、Binary Logistic Regressionに対してEquation-Solving Attacksを実行し、簡単な計算でMLモデルを複製できることを示しました。今回紹介した論文では、上記のMLモデル以外にもMulticlass Logistic RegressionやMultilayer Perceptron等のより複雑なMLモデルの複製や、Kernel Logistic Regressionから訓練データを取得する手法、Decision TreeのPathを特定する手法等が提案されています。
また、他の論文では、MLモデルに与える入力データを細工することで、MLモデルのデータ分類結果を誤らせるといった、別の攻撃手法も提案されています。
このように、機械学習モデルに対する攻撃手法は日々生み出されています。機械学習を使用したサービスやプロダクトの開発を検討されている方は、機械学習モデル特有の脆弱性を把握した上で、脆弱性を作り込まないように、正しく設計されることを推奨します。
参考
[1] Stealing Machine Learning Models via Prediction APIs
[2] Simple Black-Box Adversarial Perturbations for Deep Networks
[3] Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images
付録A:Binary Logistic Regression
Binary Logistic Regressionは2クラス分類器であり、利用者の入力データ「x, y」を2クラスに分類するアルゴリズムです。また、同時にそのクラスに所属する確率を求めることができます。本アルゴリズムは、患者の生体データ(体温、血圧等)を基に、病気の有無とその確率を求める場合等に利用されています。
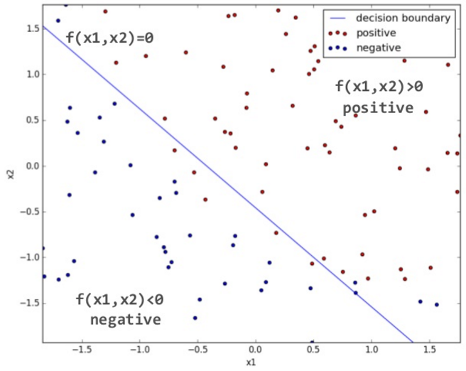
上図は、「x1, x2」で表されるデータ(赤丸=positive、青丸=negative)をBinary Logistic Regressionを使って分類した結果を表しています。青い直線は方程式の出力「f(x1, x2)」が「0」となる軌跡であり、二つのデータを分離する境界(Decision boundary)となります。このDecision boundaryを境に右上の領域は「positive」、左下の領域は「negative」と見なすことができます。よって、Decision boundary付近はどちらかのクラスに所属する確率が50%に近いデータとなり、Decision boundaryから離れるにつれて、positiveまたはnegativeに所属する確率は高くなっていきます。
なお、上図の例において、データ分類を行うための方程式「f(x1, x2)」は以下のように表すことができます。
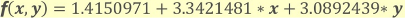
この方程式は、訓練データを用いてモデルを訓練することで求まります (当然ですが、訓練データが異なれば方程式も異なります)。
Binary Logistic Regressionを利用してデータ分類する場合、利用者が入力した未知のデータ「x, y」を上記の方程式に代入して出力「f(x, y)」を求めます。そして、方程式の出力が0より大きい場合はクラス「positive」、0より小さい場合はクラス「negative」と分類します。また、各クラスに属する確率「P」は、方程式の出力「f(x, y)」を、下図に示すロジスティック関数に代入することで求めることができます。
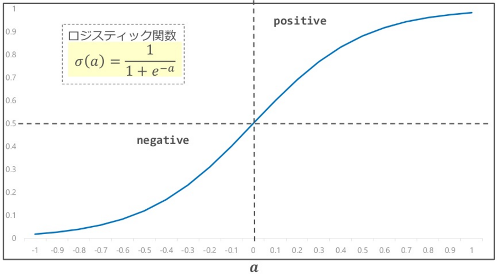
ロジスティック関数は、入力「f(x, y) = a」に対して、0から1の間の値を返します。すなわち、「f(x, y)」の値を0-1空間に写像します。この特性から、ロジスティック関数が返す値は、そのまま確率と見なすことができます。
上図の通り、「a」が0の場合(Decision boundary上の点)、ロジスティック関数の出力「P」は「0.5」になります(確率は50%)。一方、「a」が0より大きい場合(Decision boundaryの右上の点)は「0.5 < P」(確率は50%より大きい)、「a」が0より小さい場合(Decision boundaryの左下の点)は「0.5 > P」(確率は50%より小さい)となります。
すなわち、「a = 0」の点を境にDecision boundaryの右上/左下(positive/negative)どちらのクラスに属するのか、また、その時の確率「P」を求めることができます。
関連ブログ記事
おすすめ記事





