本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。
ヘッドレスブラウザは、サーバ環境などでHTMLをレンダリングするためにバックグラウンドで動作させるブラウザです。
筆者も昨年診断ツールに組み込んだのを契機に使用し始めました。使ってみるとなかなか面白いので、今年は社内での学習用の「やられサイト」にも組み込んでみました。今回はこのやられサイトを題材にして、ヘッドレスブラウザとSSRF(Server-side request forgery)について書きます。
やられサイトの概要
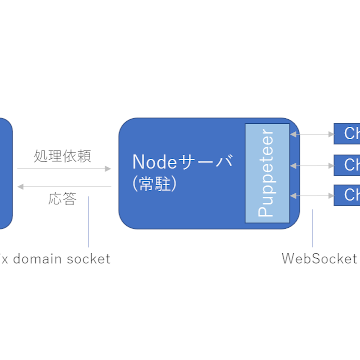
開発したやられサイトは簡単なブックマークサイトです。ユーザがURLを入力すると、そのスクリーンショット画像をヘッドレスブラウザで取得して、ユーザが付けたコメントなどの付加情報とともに保存します。
下図はヘッドレスブラウザに関連する部分の構成です。
図のとおりNode.jsのPuppeteerを使用しており、バックエンドのブラウザエンジンはChromiumです。性能向上のためNodeのサーバとブラウザのプロセスを常駐化しており、常駐しているブラウザからIncognitoなコンテキストを都度作成してレンダリングします。
ブックマークするURL(ブラウザに与える最初のURL)に対するWebアプリ側でのチェックは最低限にしています。「http(s)://」で始まるかはチェックしていますが、ホストはチェックしていないため(※)、特に捻りを加えるまでもなくlocalhostや内部のホストなどのURLを指定することができ、ヘッドレスブラウザから内部NWに対するSSRFができる状態になっています。しかし最初のURLが「http(s)://」であるため、ブラウザなどの脆弱性が無い限りは「file:///」などへのアクセスはできない仕組みです。
※実際には社内で学習用に使う際に事故が起こらないように一定の制限を掛けています。
この状況でどのような攻撃ができるか、そしてどう防ぐかというのが今回のテーマです。
ポートスキャン
この手の「内部NWにアクセスできてしまう」系のSSRFで筆者がよくやるのは、以下のようにポート番号を変えたURLにアクセスさせて、応答時間などからサーバ側で開いているポート番号を調べるテストです。
http://localhost:1
http://localhost:2
http://localhost:3
http://localhost:...
要は簡単なポートスキャンを内側から行なっていることになります。
筆者のやられサイトにおいて、内部からのリクエストの起点になるのはブラウザです。通常のHTTPクライアントが起点の場合とはスキャンのしやすさにおいて違いがあるため、以下で簡単に説明します。
まず、ブラウザ起点のスキャンではHTML/JSが使えることが利点となります。これらのおかげで、各種のイベントを使用したり、一度のレンダリングで多数のポートをスキャンしたり、応答時間をより高い精度で調べたりする余地が出てきます。また「WebRTC Leak」を使うことで、ブラウザが稼働するサーバのプライベートIPアドレスを取得できます。プライベートIPが分かれば他のサーバのIPを推測しやすくなり、スキャンの対象を広げられる可能性も出てきます(例 PortSwigger blog)。
一方でブラウザ起点のスキャンには不利な点もあります。それはブラウザが持つ様々なセキュリティ機構に制約されることです。例えば、ブラウザにはクロスプロトコル攻撃を避けるために接続が禁止された「Unsafe port」が存在し、よく使われるポートの多くがそれに含まれています。つまり、ブラウザでは一般によく使われるポートの多くをスキャンできません。
この「Unsafe port」の存在は、ブラウザを汎用的なポートスキャナとして使うことを難しくします。さらに、(OSなどに依存するようですが)筆者のやられサイトのブラウザ環境ではポートの開/閉による応答時間の差が小さく、時間差を利用した汎用的なスキャンができる場面が限られます。
筆者には本格的なポートスキャナを作る気がなかったのでこれ以上掘り下げて調べていませんが、上記のようにブラウザ起点のスキャンはそれほど簡単ではありません。ただし制約はあるもののポートスキャンができないわけではなく(特にHTTP系のポート)、少なくとも次項で述べる攻撃に必要なレベルのスキャンならば実行可能です。
ブラウザ自体へのSSRF
ポートスキャンはあくまでも攻撃の入り口にすぎません。今度はその次のSSRFの攻略について考えてみます。
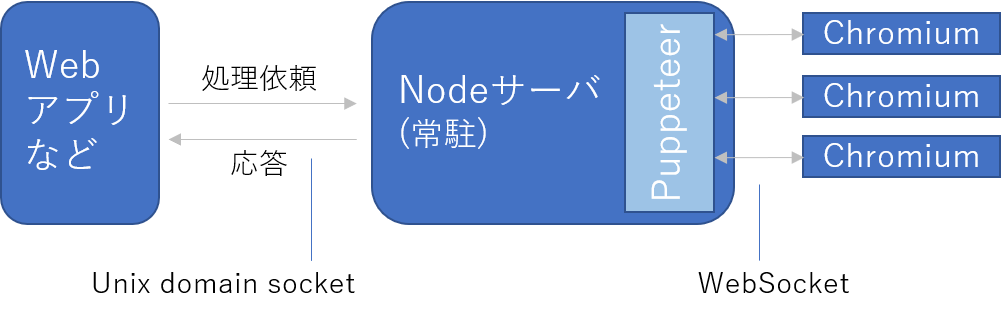
この手のSSRF攻略における最初の関門は、接続する意味のある内部のホスト/ポートをいかに見つけるかにあります。その観点でやられサイトの構成図をもう一度見てみましょう。
図の右の方に注目してください。そこに示されているように、PuppeteerはブラウザにWebSocket(WS)で接続します。接続先はヘッドレスブラウザのデバッグポートであり、Puppeteerはこの接続を通じてブラウザにレンダリングの指示を送ったり、その結果を受け取ったりしています。
この接続のデフォルトのトランスポートはTCPです。下記はサーバ上でlsofコマンドを実行した結果です。
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node 18447 test01 12u IPv4 18003400 0t0 TCP localhost:18315->localhost:36793 (ESTABLISHED)
chrome 18465 test01 158u IPv4 18002615 0t0 TCP localhost:36793 (LISTEN)ヘッドレスブラウザがTCPの36793番ポートをListenしており、それにPuppeteer(Node)が接続していることが分かります。
もうお分かりでしょうが、このポートが「接続する意味があるポート」です。もし、下図の赤線のように、ヘッドレスブラウザ内のページがこのポートに接続出来たらどうでしょう?
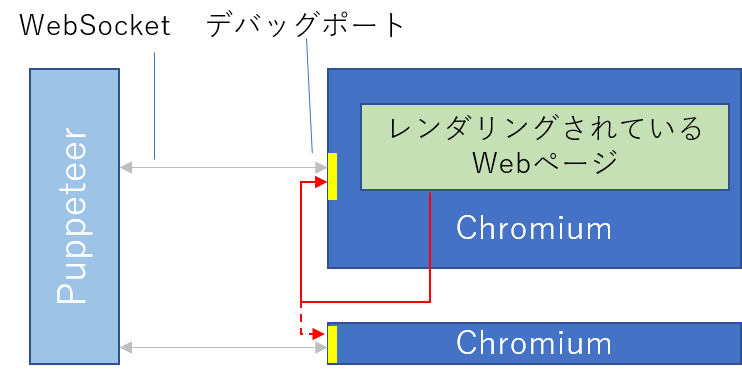
複数のブラウザプロセスが存在する場合は、赤点線のように別のプロセスのデバッグポートに接続する手も考えられます。
Chrome devtoolsのドキュメントにあるように、ブラウザのデバッグポートは様々なコマンドを受け付けます。仮に接続出来れば、各種のコマンドを送信することで、例えばブラウザが稼働するサーバ上のファイルの中身を窃取することができます。
では、ブラウザの内側からこのWSにアクセスできるのでしょうか?
実はブラウザ側でもこの類の攻撃をある程度想定しており、下のようにWSのURLを推測困難にする方法で対策しています。
ws://localhost:36793/devtools/page/AE74F73778085E78C154054FBC63A977(赤字部分がランダム)しかし、逆に言えば他に対策と言えるものは特にされておらず、WSのURLさえ分かれば同じサーバ内のクライアントから接続できてしまいます。
具体的な方法は控えますが、筆者のやられサイトのように、ブラウザを任意のhttpのURLにアクセスさせることができ、さらにそのスクリーンショットまで取得できるという、攻撃側に都合のいい条件の下では、攻撃者はデバッグポートに備わる機能を使用することでWSのURLを入手できてしまいます(ポートスキャンによりポート番号を調べる必要はあります)。
Webアプリがブラウザを常駐させている場合、WSのエンドポイントをサーバ上で生かし続けることができます。攻撃者が次にやることは、ブラウザ内にレンダリングさせた攻撃ページからWSのURLにクロスオリジンでアクセスして、いくつかのコマンドを送るだけです。
ちなみにクロスオリジンでWSにアクセスできるのは、そもそもWS自体がそれを許容する仕様となっているからです。これを制限するにはアプリ側でOriginヘッダのチェックなどを行うのが通常ですが、このWSのエンドポイントではブラウザ以外からのオリジンが無い接続や、ブラウザからのクロスオリジンでの接続を正常な使用方法として想定しているようで、その種のチェックは存在しません(※)。
※チェックという括りで言えば、デバッグポートにはDNSリバインディング対策を目的としたチェックが存在しますが、上記のような攻撃は防げません。
なお、上記は内部NWに対するSSRF攻撃の一つの例にすぎません。条件が揃わずにブラウザのデバッグポートを攻撃できないとしても、攻撃者は他のポートや他のサーバを対象に有意な攻撃を実行できるかもしれません。したがって、筆者のやられサイトのようなWebサービスを提供する際には、ブラウザから内部NWへのアクセスを制限する必要があります。
対策
この手のSSRFの対策は、大雑把にいうと以下の2点になるでしょう。
・ブラウザからのNWアクセスに関するポリシー(アクセスを許可/拒否するホスト)を定める。
・定めたポリシーを実装する。
ポリシーについては、筆者のやられのように内部NWへのアクセスを拒否したいケースでは、グローバルアドレス(IPv4ではプライベート/ローカルホストアドレスなどの特殊な予約アドレスを除いたアドレス)を許可対象にするのが一般的だと思います。もしブラウザからアクセスさせたくないグローバルアドレスがある場合は、それらを許可対象から外すなどの対処が必要です。
実装についてはいくつかの方法が考えられるので、順に概要を説明します。
ファイアウォール
まずはファイアウォール(FW)による対策です。FWにも種類がありますが、少なくともローカルホストへのアクセス制限については、それができるホスト型のものを使用する必要があります。
筆者が検証環境で試したのはiptablesのOUTPUTチェインです。下記は設定のイメージです。
-A OUTPUT -d (NWアドレス 例:0.0.0.0/8) -m owner --gid-owner nw_sandboxed -j (REJECT or ACCEPT)サーバ全体で一律にアクセスを制限すると別の問題が生じるため、検証ではPuppeteerとブラウザが稼働するグループ(nw_sandboxed)のみを制限の対象にしました。グループ名のとおり、NWアクセスを制限したサンドボックスに2つを封じ込めるという感じです。
注意が必要なのは、Puppeteerとブラウザとの間の正常なWS通信がリジェクトされないようにすることです。筆者は両者を同じグループに入れてまとめてiptablesのルールを適用した都合上、両者の通信をTCPではなくパイプ経由にすることで両者が通信できるようにしました。
プロキシ
ブラウザにプロキシ(HTTP/Socks)を設定して全てのアクセスをプロキシに転送します。そして、プロキシ側(プロキシ自体の設定、またはプロキシを置くNW/サーバの設定)でアクセスを制御する方式です。
ちなみに筆者のやられサイトの初期版はSocksプロキシで制御を行っていました。自身でプロキシでのアクセス制御を実装する場合、1本のコネクションの中に宛先が異なるメッセージが混在しうるHTTPプロキシよりも、それが無いSocksプロキシの方が扱いやすいかもしれません。
プロキシ方式の問題は、そもそもの話としてブラウザが全ての通信をプロキシ経由にするわけではないということです。少なくともWebRTCの通信についてはプロキシ経由になりません。またループバックアドレス宛の通信がデフォルトではプロキシ経由にならない点に注意が必要です。
インターセプト
Puppeteerはリクエストのインターセプト機能を提供しており、これを使うとリクエストの送信先などを制御できます。やられサイトの最終版ではこれを使っていますが、プロキシと同様に全ての通信がインターセプトできるわけではないという問題があります。例えば、Puppeteerの機能ではWebSocketやWebRTCの通信をインターセプトできません。
・・・・
上記のようにプロキシやインターセプト方式の単体では制御に漏れが発生しうるため、FWによりNWレベルで対処するか、プロキシやインターセプトの漏れをFWで補うのがよいでしょう。
検証環境
やられサイトの検証環境は下記です。
OS: CentOS 7 or Ubuntu 18.04, Node.js: v8.15.1, Puppeteer: v1.17.0 + Chromium 76.0.3803.0 (r662092)
最後に「サーバ側で動くブラウザ」に関連する、全般的なセキュリティ対策(SSRF以外)について少し考えてみます。想定しているのは、筆者のやられサイトのようなシステム構成・機能を持つサイトです。
a. ブラウザをまめにアップデートする
→ブラウザの脆弱性を突く攻撃への対策となる。
b. ブラウザが稼働するサーバを隔離・制限・監視する
→ブラウザの脆弱性やDoS的な攻撃の影響をサンドボックスにより局所化する。
c. ブラウザが使うDNSやhostsも他の内部サーバ用のものと分ける
→DNS/hostsに登録されているホスト名を総当たりで調べるような攻撃への対策となる。
d. JSを無効化する
→JSが必須でない場合。各種の攻撃への対策/リスク軽減策になる。
e. その他のセキュリティ設定をする
→WebRTCによるプライベートIPアドレスの漏洩対策など(※)。
※IPアドレスの漏洩を避けるため、生のIPアドレスのかわりにmDNSを使用するようブラウザ側での修正が進んでいます(参考 @voluntas)。
最近のChromiumでは「--enable-features=WebRtcHideLocalIpsWithMdns」フラグを付けることでmDNSが有効になります。
ブラウザの脆弱性については、一般にサーバ側のブラウザには自動アップデートが無いことと、重大な被害につながる可能性があることから注意が必要でしょう。
おすすめ記事


