本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。

はじめに
Web診断を行っている外山 良、佐藤 大陸です。 8/4~8/7にラスベガスで開催されたBlack Hat USAに参加してきました。今回弊社からは総勢7名で参加し、様々な経験・学びがありました。 本記事ではその一部をブログ形式でお届けしてまいります。
現地ラスベガスの気候はとても暑く湿度が極端に低い地域となっております。 滞在期間中の気温は40℃を超え、最低湿度は3%というかなりの高温低湿な環境でした。 ただし、今回滞在したホテルである「Luxor」からBlackHat会場の「Mandalay Bay」までは連絡通路で接続されており、徒歩15分程度の室内移動で済みました。

中途入社2年目の外山、新卒入社3年目の佐藤という社歴浅めの若手でも手を挙げれば今回のような海外カンファレンスへの参加を会社が後押ししてくれます。
少しでも弊社に興味のある方、まずはカジュアル面談からでもいかがでしょうか!
MBSD採用ページへ
Black Hatについて
Black Hatは「世界最大級のサイバーセキュリティカンファレンス」の一つで、RSAカンファレンスなどと並ぶ世界中からサイバーセキュリティに関わる人材が集まる大きなイベントです。
毎年夏に開催される「Black Hat USA」が最大規模のカンファレンスですが、他にも「Black Hat Asia」や「Black Hat Europe」など地域ごとに開催されるものもあります。
受講したトレーニングの概要
Rise of the Agents: Building Autonomous LLM-based AI Agents for Security
昨今、「AI for Security」や「Security for AI」など様々な概念が誕生していますが、今回受講したトレーニングは「AI for Security」に分類されるものになっており、LLMを活用してセキュリティのための自律AIエージェントを構築するトレーニングになっています。
1日目は生成AIの基礎やAIエージェントについてのトレーニング、2日目は前日に学んだ知識を活かしてセキュリティ業務に活かせる自律AIエージェントを構築するといった構成になっています。
Day1
- Generative AI Fundamentals
- Agentic AI
- AI for Security Operations
- RAG & Agentic RAG
- Memory Management
Day2
- Planning & Vibe Investigations
- Autonomous Security Analyst
- Optimization
- Evaluation
トレーニングの簡単な紹介
トレーニングでは以下のモジュールごとに解説->演習を繰り返し実施して理解を深めていきました。
Generative AI Fundamentals
生成AI、大規模言語モデル(LLM)、プロンプトエンジニアリング、AIモデルの仕組みを理解するための基礎概念の解説です。
ディープラーニングに関する概要、LLMがどのように自然言語を処理するのかをこのモジュールの前半で学びました。
後半では生成AIによるハルシネーションを減らす手段としてRAG(Retrieval Augmented Generation : 検索拡張生成)が有効な手段の一つであることも解説されていました。
また、Hugging Faceについても紹介されていました。
Hugging Faceとは、機械学習モデルやデータセット、AIアプリを共有できるオープンソースの AIプラットフォームです。
Hugging FaceのWebサイトにある主な機能は以下の通りです。
- モデルを公開・検索できる「Models」
- データセットを公開・検索できる「Datasets」
- クラウド環境でデモを実行できる「Spaces」
- サイト内の機能に関する学習コンテンツ「Docs」
生成AIの仕組みを体系的に整理でき、ハルシネーション対策の1つとしてRAGの重要性を再認識しました。
また、Hugging Faceの活用方法を知ることで、モデルやデータセット探索の効率化の可能性を感じました。
Agentic AI
AIエージェントの基礎について、エージェントアーキテクチャ、ツールの作成と統合、モデルコンテキストプロトコル(MCP)サーバ、フレームワークの実装などの解説です。
AIエージェントのパターンもいくつか紹介され、基本パターンと発展パターンの2通りが紹介されていましたので一部を以下に記載します。
- 基本パターン
- ReAct(Reason+Act)パターン
- LLM に「思考(Reason)」「行動(Act)」「観察(Observation)」のステップを行わせるパターン
- 単に「推論と行動を交互に実行する」だけでなく、行動の結果(Observation)を受け取り、それを次の推論に反映する点が特徴
- 発展パターン
- マルチエージェントパターン
- 1つのエージェントではなく複数のエージェントが協調・分担してタスクを遂行する設計パターン
- ネットワーク型、中央管理型などの複数のマルチエージェントパターンが存在
また、このモジュールの最後にはDapr(Distributed Application Runtime)エージェントフレームワークを用いたAIエージェントの実装方法を学びました。
エージェントの基本から発展パターンまで体系的に理解でき、設計時の選択肢が広がりました。特にReActやマルチエージェントのパターンは、タスクの複雑化への対応策として有効だと感じました。
AI for Security Operations
SOCに対してどのようにAIソリューションを導入するのかをAIの特徴の整理、実際のセキュリティ運用上の課題の整理などをしながらどのようなアーキテクチャが最適なのかを学びました。
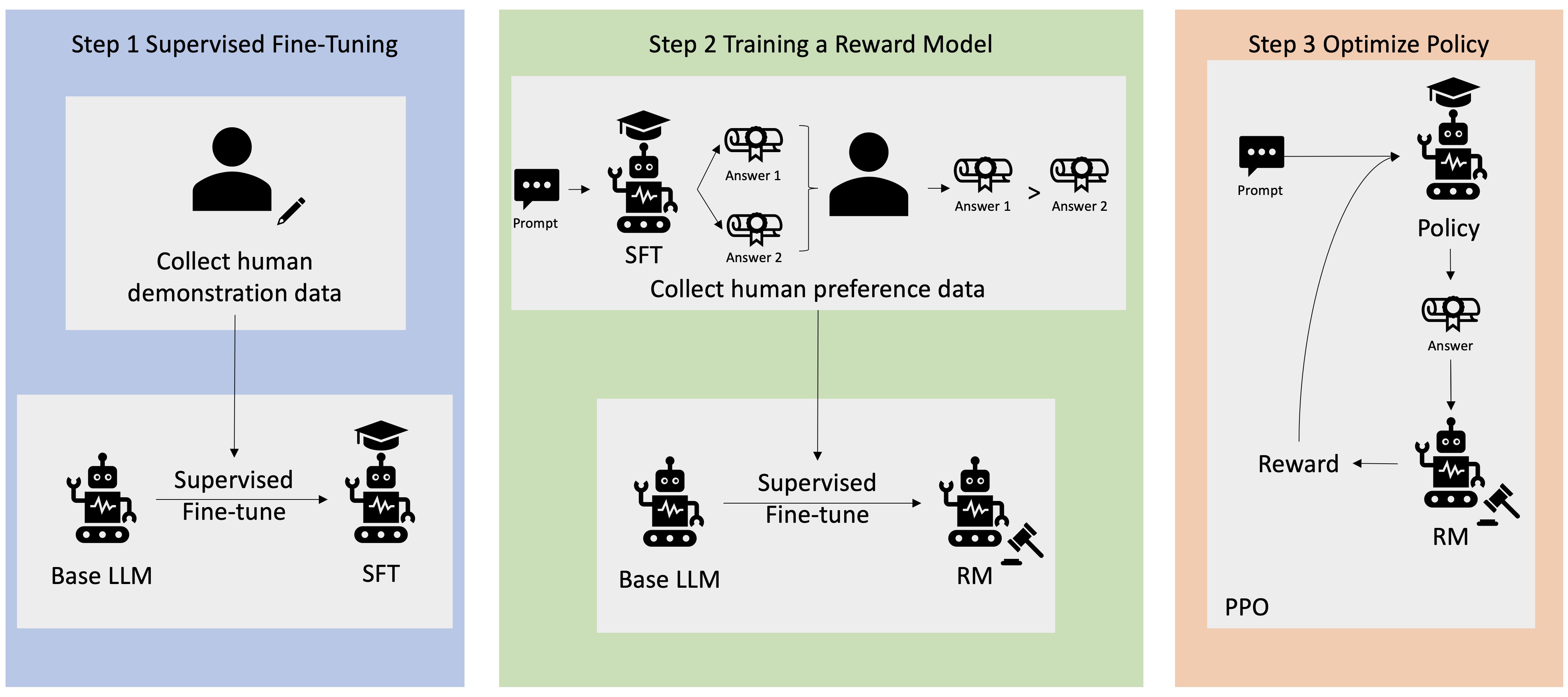
このモジュールでは、人間のフィードバックからの強化学習 (RLHF) の一例としてAWSが公開しているアーキテクチャを紹介していました。
AWSが公開しているアーキテクチャ
RAG & Agentic RAG
RAG(Retrieval-Augmented Generation)の概要と構築方法を学びました。従来のLLMは、学習済みのデータに基づいて回答を生成するため、最新の情報や、企業独自の情報など、特定のドメインに特化した情報に対応するのが難しいという課題がありましたが、RAGを活用することでより正確で信頼性の高い回答を提供できるようになります。
RAGを最適化する手法として以下の4つが紹介されていました。
- Filtering:取得候補の文書などをメタデータや条件で絞り込む手法になっており、検索範囲を縮めることによる処理の高速化、ノイズの削減が期待できます
- Re-Ranking:RAGによって返された結果を再度並べ替えることで精度を高める手法になっており、検索結果の品質を向上させることができます
- Multi-Hop:複数の情報源から段階的に情報を取得し、最終的な回答を生成する手法になっており、より複雑な質問に対しても正確な回答が可能になります
- Knowledge Graph:文書の中に出てくる人物・組織・製品などの「要素」とそれらのつながり(関係)をグラフ構造にしてから検索・生成に使うRAGの手法になっており、関係性に基づいた推論ができるため、「この攻撃者」は「どの国」を標的にしたかなどの推論が可能になります
RAGを活用できれば独自のナレッジを活かすことができ、脆弱性診断業務であれば過去の診断結果などをさらに活かして診断観点の洗い出しや品質向上に寄与できると感じました。
Memory Management
会話やワークフロー全体にわたってコンテキストの保持や管理をするための手法が解説されていました。
AIエージェントは過去のやり取りや学習した情報を記憶することで、より文脈に沿った動作が可能になります。
記憶には以下の2種類があります。
- 短期記憶 (Short-Term Memory):現在の会話や処理の中でのみ使われる記憶で会話が終わると忘れる
- 長期記憶 (Long-Term Memory):会話が終わっても残り、再度アクセスできる情報になっており、ユーザーの好みや過去の指示を保持できる
このモジュールではRAGを使用したLong-Term Memoryの演習やNeo4jを題材にした演習も行ったりしました。
Planning & Vibe Investigations
このセクションではトレーニングデモサーバーに用意されたLouie.aiを使いながら講義が進みます。
Louie.aiの紹介が主な内容であったため、詳細については以下で確認できますので是非ご興味のある方はご確認ください。
Louie.ai

Autonomous Security Analyst
データ分析のためのLLM
データの収集からLLM化までの大まかな流れの説明がありました。
全体的な流れとしては以下の紹介がありました。
- データの収集
- データクリーニングとエンリッチメント
- 会話型分析とアドホック分析
- 仮説生成/テスト
- パターン分析
- 異常検出
- 根本原因分析
- 高度な分析
- リアルタイム分析
- 予測分析
- シナリオ計画
- 拡張自動化
- 自動レポート生成
- 自動要約
- ハイパー・パーソナライゼーション
セキュリティ調査のためのエージェント
SOCにおいて生ログからAIエージェントへ教育するデータを用意するまでの手順を説明されていました。
アナリストが理解しやすいよう、インシデントに関してユーザが行った動作などをグラフ化した上でAIエージェントに学習させるプロセスを学びました。
Optimization
下記の同じ文字列でも、大文字小文字が異なるだけでLLMは異なるオブジェクトとして解釈します。
Empowering a Digital Society and Directing It Toward a Security Futuer
EMPOWERING A DIGITAL SOCIETY AND DIRECTING IT TOWARD A SECURITY FUTUER
ここで強調されているのはLLMの処理は人間とは異なるものということであり、LLMは主に下記の二種類になります。
- Masked Language Model:文章の一部が隠されており、これを予測するモデル
- Auto-regressive Language Model:「次の単語を予測する」ことを繰り返して文章を作成するモデルであり、質問を渡され回答を予測するのもこちらのモデル
ChatGPTやGeminiは「Auto-regressive Language Model」に該当します。
一方「Masked Language Model」にはBERTやRoBERTaがあるようです。こちらのモデルは初耳でした…勉強します。
上記の言語モデルの基礎の他に下記のセクションについて学びました。
- プロンプトエンジニアリング・RAG(検索拡張生成)
- LLMのファインチューニング
Evaluation
ここでは評価の重要性や評価フレームワーク、マルチエージェントと評価の考慮事項について詳しく説明がありました。 参考文献を下記に載せますので興味のある方はご確認ください。
- 評価のためのフレームワークなど: https://arxiv.org/pdf/2303.16416
- マルチエージェントと評価の考慮事項:https://arize.com/docs/phoenix/learn/evaluating-multi-agent-systems
終わりに
BlackHatのレベル感と自身の英語力にかなり不安がありましたが、資料が充実しており講義内で実行するコードや環境も主催者側で用意していただいていたこともあり、なんとかついていけました。
ただし、聞き取れない部分もありましたので、技術と共にリスニング能力等も鍛えていかなければと感じました。
本トレーニングがSOC向けの内容である部分が多く、普段従事しているWebアプリケーションの診断業務に直接活かせる機会は少ないかもしれませんが、LLMやAIエージェントの基礎を学べる良い機会になりました。
おすすめ記事





