本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。

Black Hat USA 2025 トレーニング参加レポートパート2 AI/LLM編
はじめに
Web診断と教育を担当している山本です。 2025/08/03~08/07にラスベガスで開催された「Black Hat USA 2025」に弊社エンジニアが多数参加しました。 Black Hatそのものの概要は他のメンバーにおまかせするとして、この記事では、私が受講したAI/MLセキュリティのトレーニングを紹介します。
A Black Box: Lab-based AI security and safety training delivered through the lens of historic technological disasters
このトレーニングは Security for AI にフォーカスしたハンズオントレーニングでした。トレーナー側で複数のGoogle Colaboratory のノートブックを共有してもらい、皆で様々なコードを動かしながら学ぶことができます。
LLMの基礎
このレポートを記述する前にLLMの基礎的な知識について書いておきます。
LLMの仕組み(簡易バージョン)
ChatGPTやGeminiのようなAIがリアルな会話を可能にしているのは、膨大なデータから学習した「大規模言語モデル(LLM)」が文脈を計算しています。
1. 圧倒的な量のテキストで学習
まず、大量のテキストデータを用いて機械学習を使い、コンピューターに言語のパターンを教える訓練が行われます。例えば、 1 兆~5 兆 トークン(≒数千億語~数兆語)規模という膨大なテキストデータを学習します。学習は、人間のお勉強のようなものではなく、「次の言葉を当てるゲーム」を延々と繰り返させるイメージです。学習のたびに正解不正解になったりしますがこの過程で重み(パラメータ)が調整され、言語の統計的パターンが定まります。
2. 単語をベクトルに置き換える(Embedding)
訓練の過程で、各トークン単位(文字や単語)を多次元ベクトルとして置き換えます(Embedding)。これにより、言葉の関連性、例えば「猫」とは「犬」と似た方向に分類されるようにモデルが学習します。皆さんが普段使っているモデルには数百億件ものパラメータがあり、入力された文章(例えば「猫が」)に対して、どのような次の言葉が出力されるべきかを決めるための重みになります。LLMが知識を持っているように見えるのは、圧倒的な量の統計的パターンが重みに埋め込まれているにすぎません。
※ 例えば、2025/08/05 にリリースされた OpenAIのgpt-ossは、20Bは約200億、120Bは約1,200億パラメータを持ちます。
3. Attentionによる文脈の理解
実際のチャットでは、文章中の全単語(トークン)間の関係を重み付けして計算します(Attention)。そして、次に来そうな単語の確率ベクトルを計算します。 例えば野球の文脈を入力しているときに、「大谷」の次に来そうな単語って「翔平」や「選手」ですよね。これを繰り返して文章を生成しています。あくまで確率なので必ずしも毎回同じ単語が選択されるわけではありません。少しランダム性があります。この時の出力の「ランダム性」は「Temperature」という設定で制御されます。値が低いほど確率の高い単語が必ず選ばれるため、出力が安定します。一方、値が高いと確率の低い単語も選ばれるようになるので、最終的に生成された文章を人間が読んだときにクリエイティブな表現だと感じるようになります。
さて、LLMの基礎もわかったところでトレーニングレポートを始めましょう。
Study1: AIの基礎をゼロから理解する
まず、AIに対するセキュリティと聞いていたので、まさかAIの基礎としてからやらせてもらえるとは思いませんでした。先ほど説明したような、なぜAIは動作するのか、どのような仕組みなのか。を理解するStudyです。通常、AIモデルを扱うにはPythonライブラリとして"TensorFlow" や "PyTorch" を使うのですが、ここではそれらをあえて使わず、Python3とNumpyだけでシンプルなニューラルネットワークを構築します。ニューロン、層、活性化関数、といった基本概念を根本から学習しました。AIもだいぶ賢い時代になりましたが本質的には関数や数列、ベクトルの塊で動作しているんだなということを再認識させられます。 ニューラルネットワークの学習過程を可視化させることができるサイト Neural Network Playground
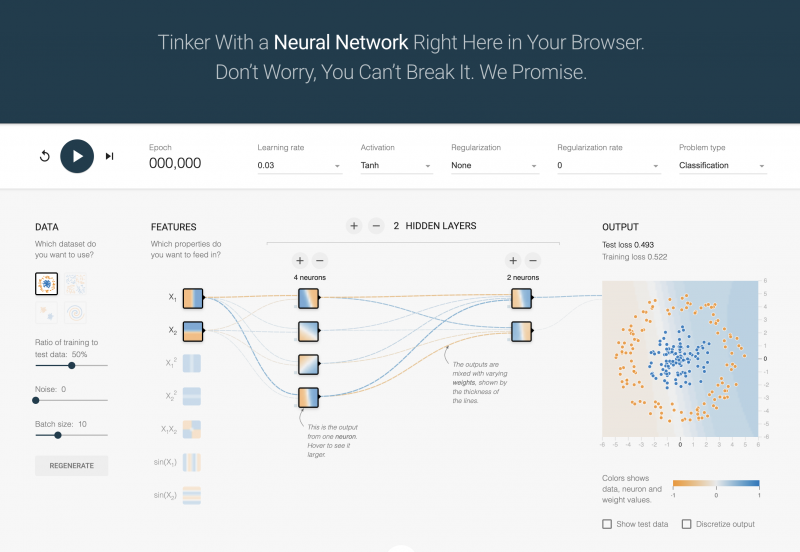
このサイトを利用してどのような学習過程を経ているかも確認します。これは、オレンジと青の点を分類するため、模擬的なトレーニングを体感できるものです。私はもともとこのサイトは随分前に見ていたので今回特段驚きはなかったのですが、エポックを経るごとに分類モデルの精度が増す様子が見られて面白いです。これにハマっている人がいてずっと動かしていましたね笑。
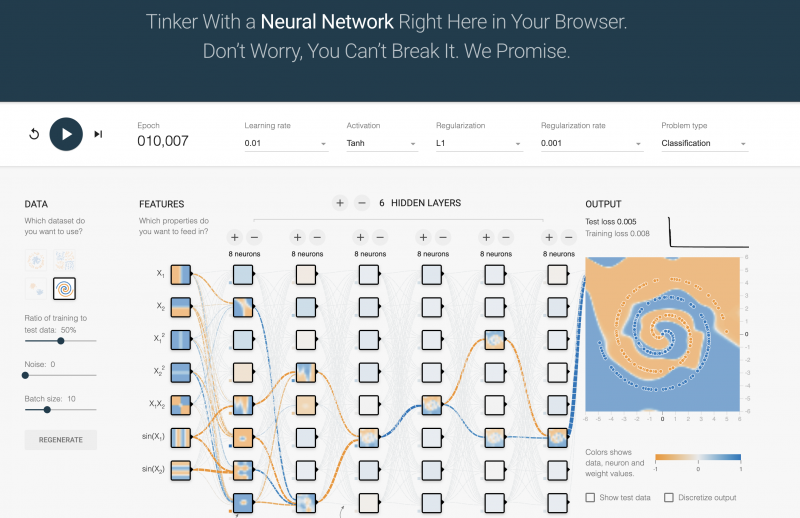
ニューロンと活性化関数の設定をして10,000エポックのトレーニングをした際の様子。どの座標がオレンジと青に分類されるかをトレーニングできていることがわかります。
Study2: 画像認識AIに対する敵対的攻撃
これはご存じの方も多いかもしれません。某メーカーの自動運転車における道路標識の画像認識AIのエラーによって引き起こされた事故をケースStudyに、AIの誤分類がもたらす現実世界の危険性に焦点を当てたハンズオンです。このハンズオンでは、画像に人間には認識できないわずかなノイズや細かいピクセルを加えることで、画像認識モデルが「止まれ」の標識を「時速80km」といった誤認識する様子を体験し、安全性に関わるAIシステムが、いかに簡単に騙されてしまうかを学習します。
Study3: ファインチューニングハンズオン
LLMを特定の知識に付いて追加学習する手法についてファインチューニングというものがあります。ベースとなるLLMに医療や金融などの専門知識をつける手法ですね。ファインチューニングすることでその知識領域におけるプロフェッショナルを作ることができます。ただし、これは良質なデータセットがあってこそ効果を発揮するものです。このStudyではXSS攻撃をまとめたデータセットを使用して、XSS攻撃を検知するAIモデルを作成します。ただしそのデータセットはごく一部に質の悪いデータが入っています。僅かな質の悪いデータで精度が著しく下がり、使い物にならなくなってしまう様子を皆で確認します。
LLMには温度(temperature)というパラメータがあるのですが、一般的にこの値を上げると創造性が増すと言われています。何かクリエイティブなことを出力してほしいときに値を1.0以上に上げると良い、と聞いたことがありませんか? これはLLMの仕組み上、次に来るトークン(単語)の選択における曖昧さが増します。値が0に近くなると、確率の高いトークン(単語)が選ばれるので固定の出力を得やすくなる。値がますとランダム性が増す、という仕組みです。クリエイティブな出力と言われている本質はランダム性を増すことによって予測しにくい出力を得るということなのです。
このStudyでは、質の悪いデータセットを使用するとtemperatureの値を少しいじるだけで精度が極端に悪くなってしまう様子が確認できました。モデルをカスタマイズするというのは簡単なことではない事がわかります。
Study4: AIモデルの学習データをポイズニング(汚染)する
AIモデルのトレーニングデータに悪意のあるデータを混入させる「データポイズニング(データ汚染)」を実践するStudyです。データポイズニングとは、攻撃者がモデルのトレーニングデータを操作することで脆弱性を導入するタイプの攻撃手法です。今回は、MNISTを元に特定の誤ったラベルが付いた画像を数点挿入してモデルをトレーニングし、画像認識時にモデルが特定のピクセルパターンを検知した際にラベル分類を誤る(ポイズニングされる)様子を観察します。これはちょっと難しかったのですが、Study3と同じで、AIモデルはデータセットが命です。もちろん精度に影響もするのですが特定のパターンで起動する誤検知といった、攻撃にも利用できるという側面を目の当たりにできて非常に新鮮でした。
Study5: LLMの安全対策の基本。プロンプトインジェクションとJailbreak
LLMセキュリティの基礎・定番といえばプロンプトインジェクションとJailbreakですね。LLMは元々危険な質問や違法な質問には答えないようにガードレールが設定されていますが、プロンプトを工夫することでその制限を突破できてしまいます。まず、みんなで Gandalf をトライしました。このサイトは、Gandalfという魔法使いのキャラクターからパスワードを聞き出すというゲームです。レベルが上がるにつれてガードレールも強化されパスワードを聞き出すのが難しくなります。私は時間内にはLevel5が限界でした。
そこから実際にローカルLLMである Phi3 を用いて具体的なプロンプトインジェクションの機序などをハンズオンしていきました。
Study6: AIエージェントの制御
2025年はAIエージェントの年と言われていますね。LLMがツールとの連携という武器を獲得することで様々なタスクがこなせるようになりました。このStudyではシンプルなAIエージェントを構築し、悪意のあるプロンプトで予期せぬ行動を誘発する攻撃を体験します。APIコールが可能なエージェントを実装し、そのうちの一つは機密情報を返却するようにしています。本来では適切な手続きを取ってAPIコールをするべきですが、プロンプトインジェクションによってその制限を突破します。今までのStudyの総まとめみたいな感じです。
Study7: Vibe Coding の危険性
Vibe Coding(バイブコーディング)とはLLMを使って自然言語だけでプログラムを作成可能な手法です。Claude CodeやClineが代表的なバイブコーディングで使用されるAIエージェントです。
皆さんClaude CodeやClineを使っていますか?私もたまに使います。簡単にコードを生成できて少し複雑な検証でも短時間で出来るようになって便利ですね。しかし、現在ではあまりコードやセキュリティを学習せずアイデアとコーディングエージェントだけでプロダクトをリリースしてしまいセキュリティインシデントに発展する事例が増加しています。Briefingsにも同様のトピックがありました。現在のコーディングエージェントは限界があり、使用する人間のコントロールが品質とセキュリティに直結します。必ずセキュリティテストをする必要性を学びます。
コードロジックにおける脆弱性(テクニカル系)はDASTやSASTの使用、IDORなどのビジネスロジックに関わる脆弱性はきちんと脅威モデリングを行いテストするべきということを学びます。診断を業務にしている以上すぐ納得感は得られますがどうやってこれを他人に説明しようかというのが難しいです。このStudyを通して、「何が問題か」、「なぜセキュリティテストをやらねばならないか」を言語化しやすくなったように感じます。
Study8: 偽情報との戦い
最後は偽情報です。いわゆるLLMによる偽記事や、Deepfakeなどの本人になりすましたコンテンツです。近年社会問題化していますね。このStudyではHugging Faceに出回っている複数の生成AIによるコンテンツ検出に特化したAIモデルを使って、検出精度を確かめます。ここは時間がなくサクッと流されてしまったのですが検出精度は完璧ではありませんでした。生成AIによる偽情報の拡散を防ぐことの難しさと、検出モデルの持つ限界を感じました。政府による規制の必要性などもトレーナーは説いていました。
全体の感想
このコースを提供していた会社はBlack Hatでの提供は初めてとのことでしたがAI/LLMに関する包括的なセキュリティが学べて大変高品質なトレーニングだと感じました。もはや、AI/LLMは使えて当たり前の世界です。セキュリティの世界に身を置くものとして、AI/LLMセキュリティとどう向き合っていくかを考えるための基盤の知識として役立つものでした。
山本 健太
おすすめ記事


