


| 開発工程 | 攻撃分類 | 攻撃手法 | 防御手法 |
|---|---|---|---|
|
学習データの収集/作成 (Data Preparation) |
データ汚染 |
|
|
|
モデルの学習/作成 (Model Fitting) |
モデル汚染 |
|
|
|
モデルの設置 (Deployment) |
敵対的サンプル | ||
| データ窃取 |
|
||
|
|||
| モデル窃取 |
|
Model Inversion Attacks
AIの学習データを窃取する手法。攻撃の目標は「メンバーシップ推論攻撃」と同じくデータ窃取ですが、アプローチが大きく異なります。メンバーシップ推論攻撃では、攻撃者は正常な入力データに対する標的AIの応答を観察することで、入力データが標的AIの学習データに含まれているか否かを推論します。一方、Model Inversion Attacksは、ランダムに初期化した乱数データを標的AIに入力し、これに対する標的AIの勾配を観察します。そして、勾配を基に、窃取したいデータが属するクラスに対する入力データの誤差が小さくなる方向に入力データを変更します。この操作を繰り返すことで、入力データを窃取したいデータが属するクラスに近づけることができます(学習データの再構成)。仮に、機密情報を含むデータを学習したAIが本攻撃を受けた場合、情報漏えいに繋がるおそれがあります。


Model Inversion Attacks(モデル反転攻撃)は、モデルの設置/運用・保守工程を狙った「データ窃取」の1手法です。
2015年に論文「Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures」で発表されました。
Model Inversion Attacksは、AIの学習データを再構成することで窃取する手法です。
攻撃者は、ランダムに初期化した乱数データを標的AIに入力し、標的AIの勾配情報を観察します。そして、勾配を基に、窃取したいデータが属するクラスに対する入力データの「誤差が小さくなる方向」に入力データを変更します。この操作を繰り返し行うことで、乱数データは徐々に窃取したいデータが属するクラスに近づいていきます(学習データの再構成)。
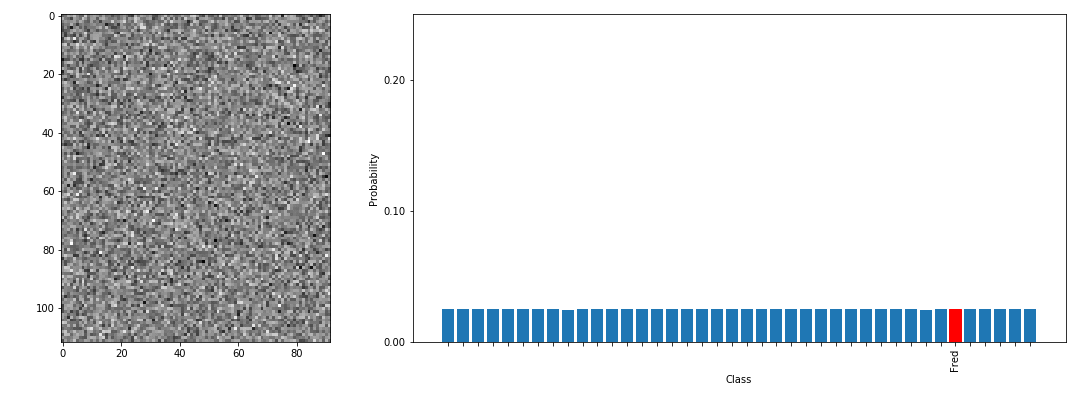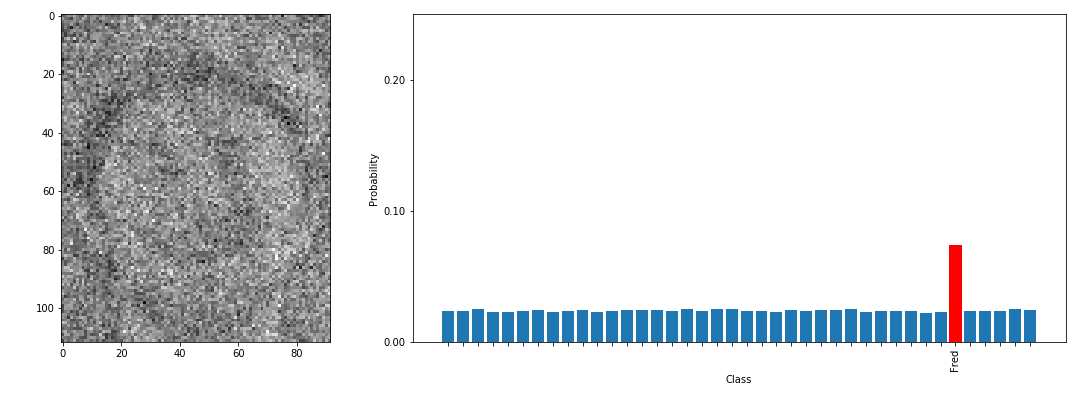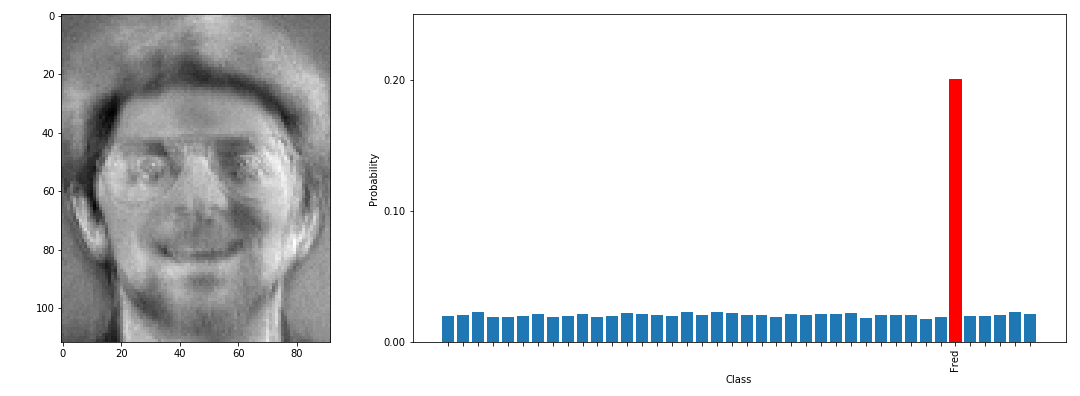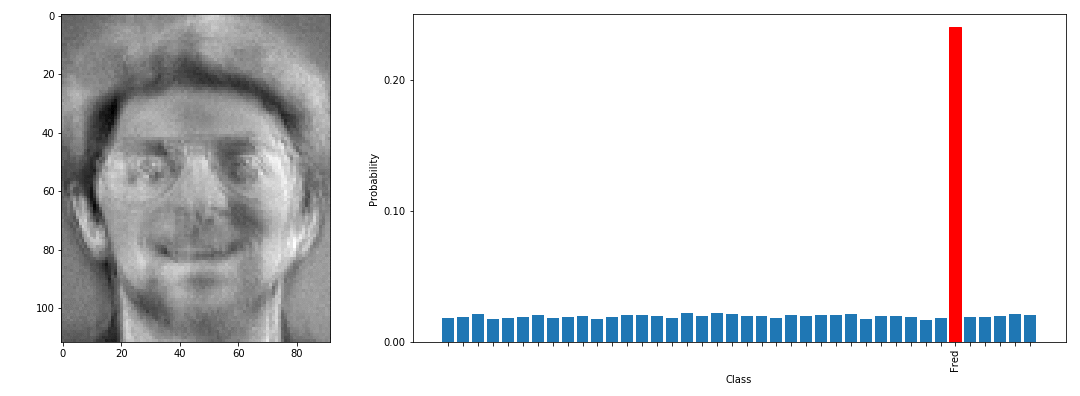
以下の図は、Model Inversion Attacksで顔認識モデルを攻撃し、Fredさんのクラスのデータを再構成する様子を表しています。左に示す画像が攻撃者が用いる乱数データであり、徐々にFredさんクラスのデータに変化していく様子が分かります(実際のFredさんの写真はページ後半に掲載しています)。
Model Inversion Attacksの「勾配情報」を利用するアプローチは、敵対的サンプルを生成するFGSMと似ています。以下の図に示すように、FGSMでは標的AIへの入力データ(x)に対する損失(Loss)の勾配情報を利用し、その損失を最大化するように摂動を入力データに加えていくことで敵対的サンプルを作成します。

一方、Model Inversion Attacksはその逆であり、以下の図に示すように、窃取したいデータが属するクラスに対する入力データ(最初は乱数データ)の損失を最小化するように、入力データを変更していきます(損失が最も小さい地点を原点「o」とする)。

この流れを手順化すると以下になります。
この単純な計算を何度も繰り返すことで、乱数データが徐々に窃取したいデータが属するクラスに近づいていきます(学習データの再構成)。以下の図は、Model Inversion Attacksによって再構成したデータ例を表しています。

左が再構成データ、右がオリジナルの学習データ(の一例)です。
この通り、再構成データと学習データは概ね似ていることが分かります。なお、再構成データは窃取したいデータが属するクラスの平均を取ることになるため、ぼやけた状態で再構成されます。このため、再構成データと実際の学習データが完全一致するとは限りませんが、概ね同じ人物であると認識することができます。
このように、攻撃者は標的AIの勾配情報を利用することで、理論上、標的AIが学習した全てのクラスに属するデータを再構成(窃取)することができます。なお、本解説では、攻撃者が標的AIの勾配情報にアクセスできる「ホワイトボックス攻撃」に焦点を当てていますが、入力データに対して標的AIが応答する信頼スコアを利用することで、勾配情報無しでも攻撃可能な「ブラックボックス攻撃」も存在します。
よって、AI開発者・利用者は、「勾配情報にノイズを加える」「信頼スコアを丸める」など、攻撃に悪用される情報の精度を落とすなどしてModel Inversion Attacksへの耐性を高める必要があります。また、単純な方法ですが、Model Inversion Attacksは標的AIに何度も繰り返してアクセスする必要があるため、単一のアクセス元からのアクセス数を制限することも、攻撃の緩和に有効であると考えられます。
より詳細な内容を知りたい方は、論文「Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures」をご参照ください。