


| 開発工程 | 攻撃分類 | 攻撃手法 | 防御手法 |
|---|---|---|---|
|
学習データの収集/作成 (Data Preparation) |
データ汚染 |
|
|
|
モデルの学習/作成 (Model Fitting) |
モデル汚染 |
|
|
|
モデルの設置 (Deployment) |
敵対的サンプル | ||
| データ窃取 |
|
||
|
|||
| モデル窃取 |
|
FGSM(Fast Gradient Sign Method)
AIの誤分類を引き起こす敵対的サンプル(Adversarial Examples)を作成する手法。敵対的サンプルとは、AIの誤分類を誘発するように細工された入力データを指しており、オリジナルのデータに「摂動」と呼ばれる微小なノイズを加え、意図的に特徴量を変化させることで作成します。なお、敵対的サンプルを利用してAIの誤分類を誘発する攻撃を「回避攻撃(Evasion Attack)」と呼びます。


FGSMは、モデルの設置/運用・保守工程を狙った「敵対的サンプル」の1手法です。
2014年に論文「Explaining and Harnessing Adversarial Examples」で発表されました。FGSMは、攻撃対象となるAIの「勾配」を利用することで敵対的サンプルを作成します。よって、FGSMで敵対的サンプルを作成するためには、攻撃対象AIが攻撃者の手元にあることが前提となります(ホワイトボックス攻撃)。
先ずは、敵対的サンプルをおさらいしましょう。
敵対的サンプルとは、オリジナルのデータに摂動と呼ばれる微小のノイズを加えて特徴量を意図的に変化させたデータを指します。そして、この敵対的サンプルを利用してAIの誤分類を誘発する攻撃を回避攻撃(Evasion Attack)と呼びます。AIベースの顔認証システムや自動運転車に搭載される物体検知エンジンなどを騙す回避攻撃の検証事例も存在します。
敵対的サンプルを作成する手法は数多く提案されていますが、本項で紹介するFGSMはその代表的な手法です。
以下は、FGSMを使用して敵対的サンプルを作成する様子を表しています。 左がオリジナルのデータ(パンダ)、真ん中がオリジナルに加えられる摂動、右画像が敵対的サンプルです。ご覧のとおり、皆様の目にはオリジナルと敵対的サンプルの違いは識別できないでしょう。どちらも「パンダ」に見えると思います。

ところが、この敵対的サンプルをAI(画像分類器)に入力すると、99.3%の精度でテナガザル(gibbon)として認識されます。これは、摂動によってオリジナルの特徴量がパンダからテナガザルに変化しているためであり、入力データの特徴量を基に分類を行うAIにはテナガザルに見えてしまいます。
FGSMでは、AIの入力データに対する損失の勾配を使用し、その損失を最大化するように摂動を入力データに加えていくことで敵対的サンプルを作成します。以下は、FGSMで敵対的サンプルを作成する流れです。
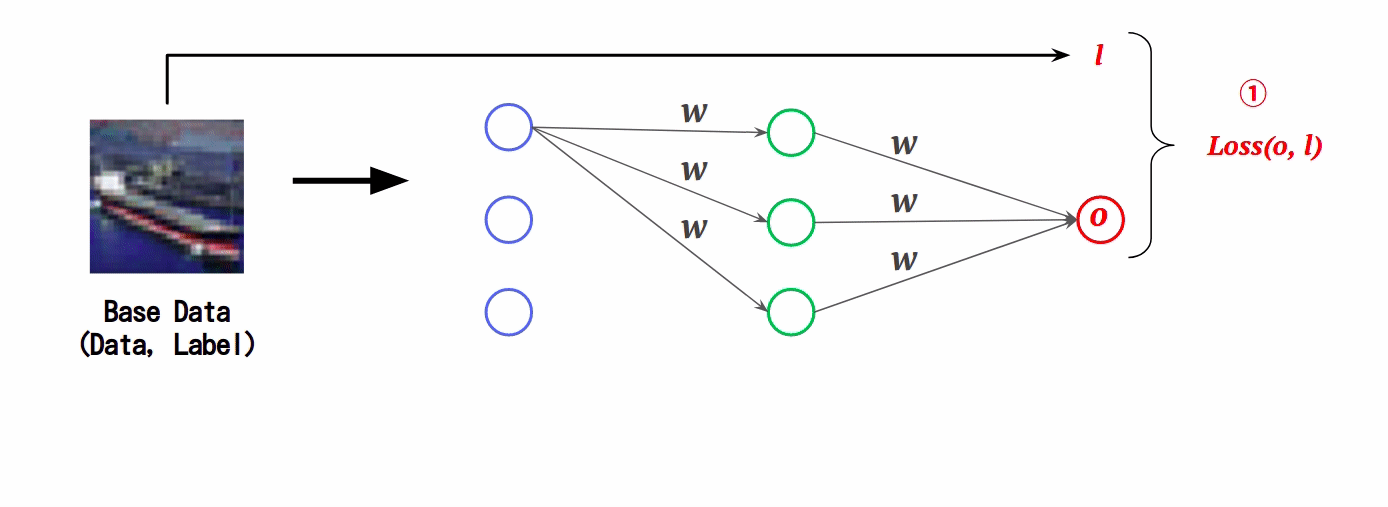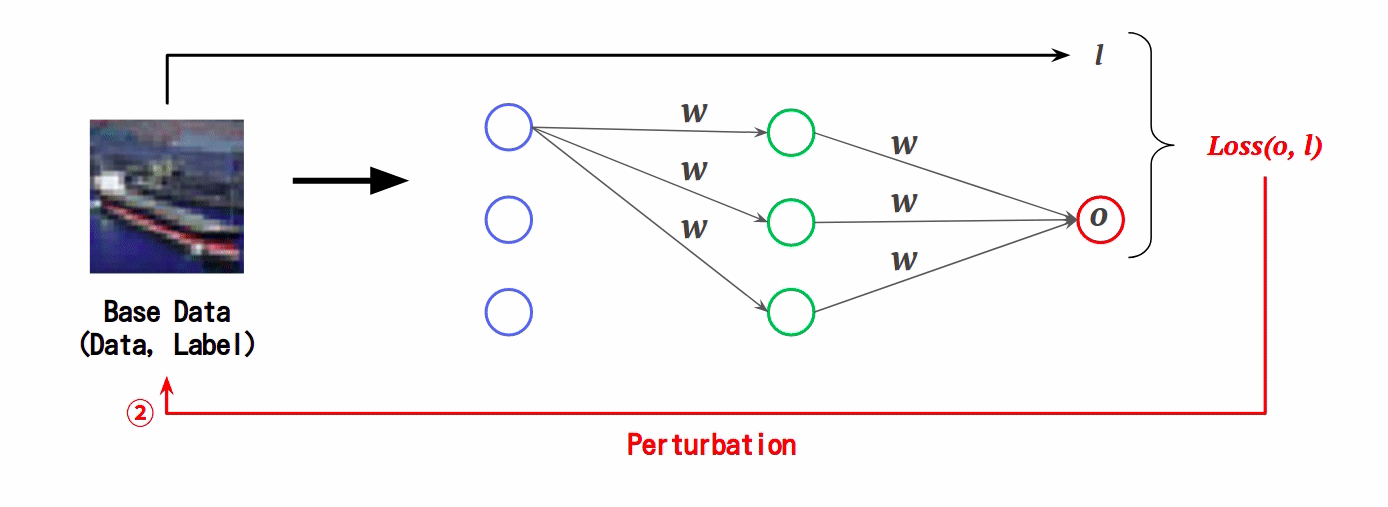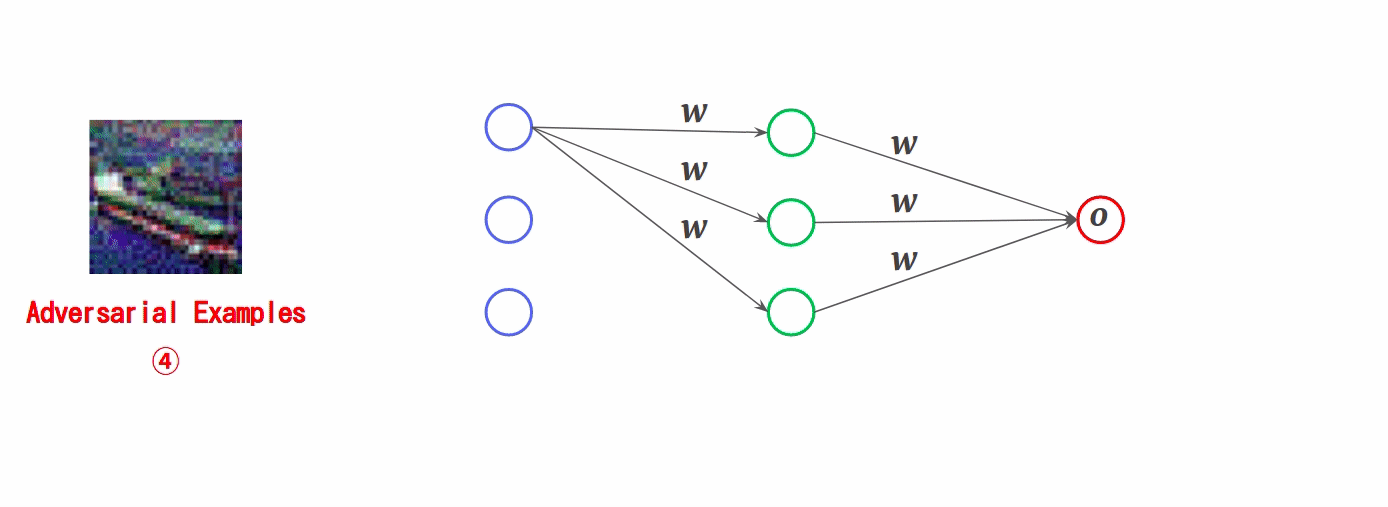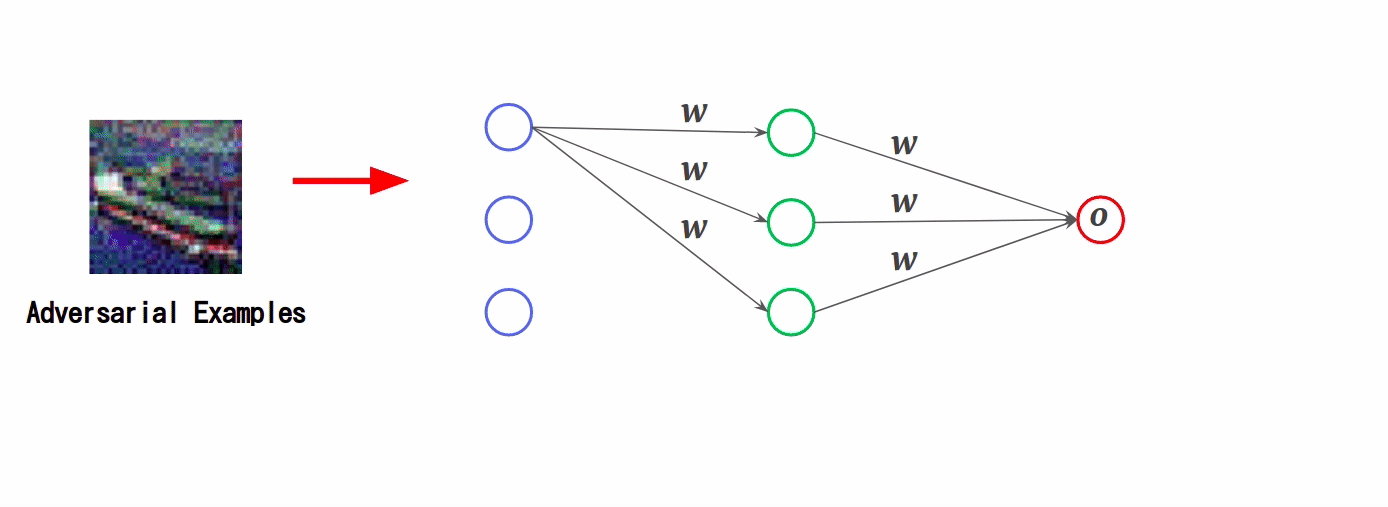
この様子を損失関数の視点で表すと以下のようになります。
なお、原点「o」が損失が最も小さくなる(分類の誤差が最も小さくなる)地点です。

通常、AIの学習では勾配が小さくなる方向に重み「w」を更新していきますが、FGSMでは勾配が大きくなる方向にデータ「x」を更新していきます。勾配が大きくなればなるほど損失関数の原点から遠ざかっていくため、AIは入力データ(敵対的サンプル)を誤分類してしまいます。
なお、摂動の量が多すぎるとデータに多くのノイズが乗ることになり、見た目に違和感が生じることで敵対的サンプルが検知される可能性が高まります。よって、攻撃者は誤分類を引き起こしつつ見た目に違和感が生じないように、少しずつ摂動を加えていきます。
より詳細な内容を知りたい方は、解説ブログをご参照ください。