


| 開発工程 | 攻撃分類 | 攻撃手法 | 防御手法 |
|---|---|---|---|
|
学習データの収集/作成 (Data Preparation) |
データ汚染 |
|
|
|
モデルの学習/作成 (Model Fitting) |
モデル汚染 |
|
|
|
モデルの設置 (Deployment) |
敵対的サンプル | ||
| データ窃取 |
|
||
|
|||
| モデル窃取 |
|
データ汚染
学習データの収集/作成工程を狙った攻撃です。
攻撃を受けた場合、入力データの誤分類が引き起こされます。
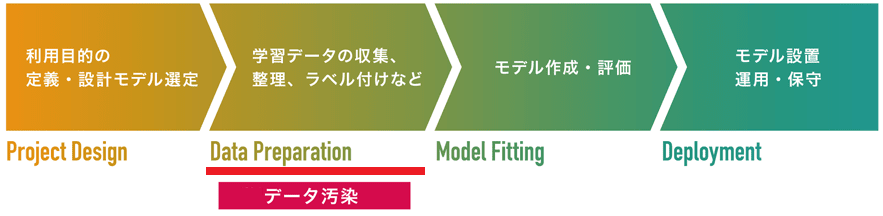
データ汚染攻撃とは、汚染データと呼ばれる摂動を加えたデータを学習データに注入し、これを標的AIに学習させることで、トリガーと呼ばれる攻撃者しか知り得ない特定の入力データを攻撃者が意図したクラスに誤分類させることができます。文献によってはバックドア攻撃とも呼ばれます。
| 代表的な攻撃手法 | 代表的な防御手法 |
|---|---|
|
|
モデル汚染
モデルの学習/作成工程を狙った攻撃です。
攻撃を受けた場合、入力データの誤分類やAIが稼働するシステムの破壊などが引き起こされます。
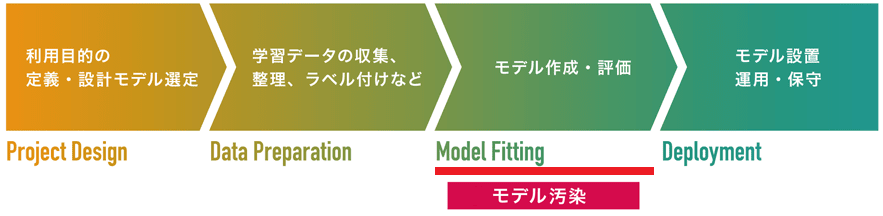
モデル汚染攻撃とは、攻撃者が細工したノードが注入された事前学習モデル(学習済みモデルとも呼ばれる)を作成し、これを被害者に配布して使用させることで、トリガーと呼ばれる攻撃者しか知り得ない特定の入力データを攻撃者が意図したクラスに誤分類させることができます。文献によってはバックドア攻撃とも呼ばれます。
また、悪意のあるコード(Pythonコードやシステムコマンド)を実行するレイヤー(層)を事前学習モデルに注入する攻撃手法も存在し、この場合はAIが稼働するシステム上で悪意のあるコードが実行されることで、システムの破壊や情報漏えい、システムへの侵入などが引き起こされます。
| 代表的な攻撃手法 | 代表的な防御手法 |
|---|---|
|
|
敵対的サンプル
モデルの設置工程を狙った攻撃です。
攻撃を受けた場合、入力データの誤分類が引き起こされます。
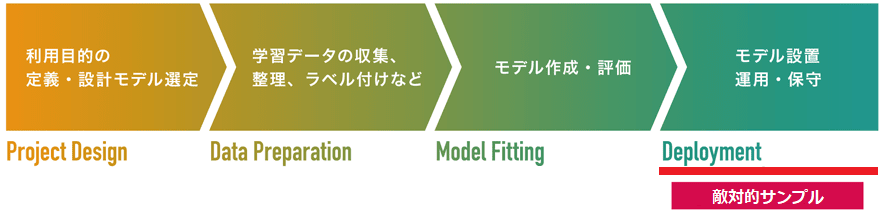
敵対的サンプルとは、入力データ(主に画像)に「摂動」と呼ばれる微小のノイズを加えることで、入力データの特徴量を変化させたデータを指します。攻撃者は敵対的サンプルをAIに入力することで、これを攻撃者が意図したクラスに誤分類させることができます。なお、敵対的サンプルに加えられる摂動は微小であるため、人間の目で異常を検知することは困難です。文献によっては回避攻撃とも呼ばれます。
また、敵対的サンプルの一種として、AIによる物体検知を不能にする、または全く関係のない物体として誤検知させるAdversarial Patches(敵対的パッチ)と呼ばれる手法も存在します。本手法では、人間に違和感を与えない程度の特殊なパッチ柄を物体に貼り付けることで、(監視カメラなどに活用される)リアルタイムの物体検知AIを騙すことができます。
| 代表的な攻撃手法 | 代表的な防御手法 |
|---|---|
データ窃取
モデルの設置工程を狙った攻撃です。
攻撃を受けた場合、情報漏えいが引き起こされます。また、敵対的サンプルなどの攻撃の足掛かりとして利用されます。
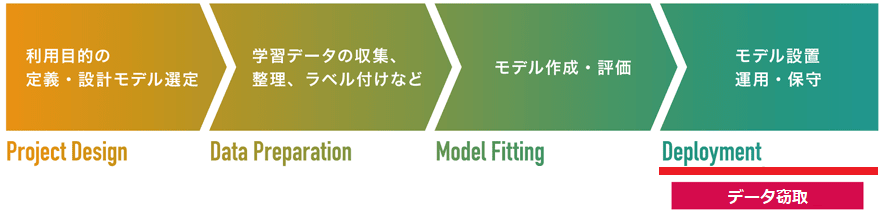
データ窃取とは、標的AIに複数のデータを入力し、AIの分類結果や信頼スコア(分類の確度を示す確率値)を観察することで、AIの学習データを推論することができます。AIの学習データに機微情報が含まれていた場合、情報漏えいが引き起こされます。文献によってはメンバーシップ推論攻撃とも呼ばれます。
また、標的AIの勾配情報や信頼スコアを観察することで、標的AIが学習したデータを再構成する攻撃手法も存在します。この場合も情報漏えいが引き起こされます。このようなデータを再構成して窃取する手法をモデル反転攻撃とも呼びます。
| 代表的な攻撃手法 | 代表的な防御手法 |
|---|---|
|
|
|
モデル窃取
モデルの設置工程を狙った攻撃です。
攻撃を受けた場合、モデルの窃取が引き起こされます。また、敵対的サンプルなどの攻撃の足掛かりとして利用されます。
モデル窃取とは、標的AIに複数のデータを入力し、AIの分類結果や信頼スコア(分類の確度を示す確率値)を観察することで、AIの内部情報(決定境界やパラメータなど)を推論することができます。商用サービスとして公開されているAIのモデルが窃取された場合、模倣サービスが展開されることでビジネスモデルが崩壊する可能性があります。
| 代表的な攻撃手法 | 代表的な防御手法 |
|---|---|
|