


| 開発工程 | 攻撃分類 | 攻撃手法 | 防御手法 |
|---|---|---|---|
|
学習データの収集/作成 (Data Preparation) |
データ汚染 |
|
|
|
モデルの学習/作成 (Model Fitting) |
モデル汚染 |
|
|
|
モデルの設置 (Deployment) |
敵対的サンプル | ||
| データ窃取 |
|
||
|
|||
| モデル窃取 |
|
トリガーの検知 (STRIP: STRong Intentional Perturbation)
データ汚染攻撃の防御手法。複数の画像を重ねるなどして意図的に摂動を加えたデータをAIに入力し、この入力データが分類されるクラスのバラつきを観測することで入力データがトリガーか否か検知します。


トリガーの検知(STRIP)は、データ汚染攻撃に対する防御の1手法です。2019年に論文「STRIP: A Defence Against Trojan Attacks on Deep Neural Networks」で提案されました。本手法は、複数の画像を重ねるなどしてAIの入力データに摂動を加え、この入力データが分類されるクラスを観測することでトリガーを検知します。
正常な入力画像の場合は、摂動の影響により様々なクラスに分類されますが、入力画像がトリガーの場合は、AIがバックドアに強く反応し、摂動をもろともせず(攻撃者が意図した)ある一定のクラスに分類されます。このように、トリガーの有無によって分類クラスが偏る事象を観測することで、入力画像がトリガーか否かを判定します。
以下の図は、MNISTから無作為に選定した1,000枚の数字画像から正常な入力画像とトリガーを作成し、これらに摂動を加えた場合の分類クラスの分布を表しています。
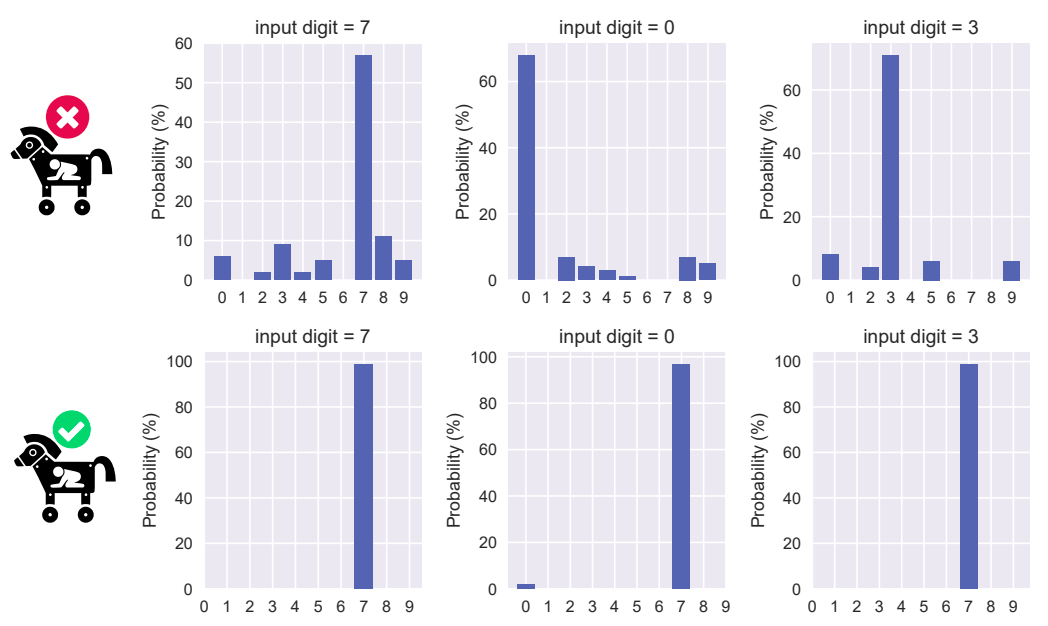
上段は正常な入力画像(左から7、0、3)の結果、下段はトリガー(左から7、0、3)の結果です。正常な入力画像は摂動の影響により様々なクラスに分類されていることが分かります。対照的に、トリガーは摂動の影響を受けずに、殆どが(攻撃者が意図した)クラス「7」に分類されていることが分かります。
このように、摂動が加えられた入力画像が分類されるクラスの偏りを観測することで、入力画像がトリガーか否かを判定することができます。
より詳細な内容を知りたい方は、解説ブログをご参照ください。