


| 開発工程 | 攻撃分類 | 攻撃手法 | 防御手法 |
|---|---|---|---|
|
学習データの収集/作成 (Data Preparation) |
データ汚染 |
|
|
|
モデルの学習/作成 (Model Fitting) |
モデル汚染 |
|
|
|
モデルの設置 (Deployment) |
敵対的サンプル | ||
| データ窃取 |
|
||
|
|||
| モデル窃取 |
|
敵対的学習 (Adversarial Training)
敵対的サンプルの防御手法。AIの学習時に、通常の学習データに敵対的サンプルを加え、敵対的サンプルの特徴を学習することで、敵対的サンプルによる誤分類を抑制します。


敵対的学習は、敵対的サンプルに対する防御の1手法です。2014年に論文「Explaining and Harnessing Adversarial Examples」で提案されました。
本手法は、正常データと敵対的サンプルの特徴をAIに学習させる防御手法です。AIの学習時において、正常データと敵対的サンプルに対する誤差(Loss)をそれぞれ計算し、これを足し合わせた値を基にAIの重み「w」を更新することで、敵対的サンプルの特徴を学習します。
以下は、敵対的学習の流れです。
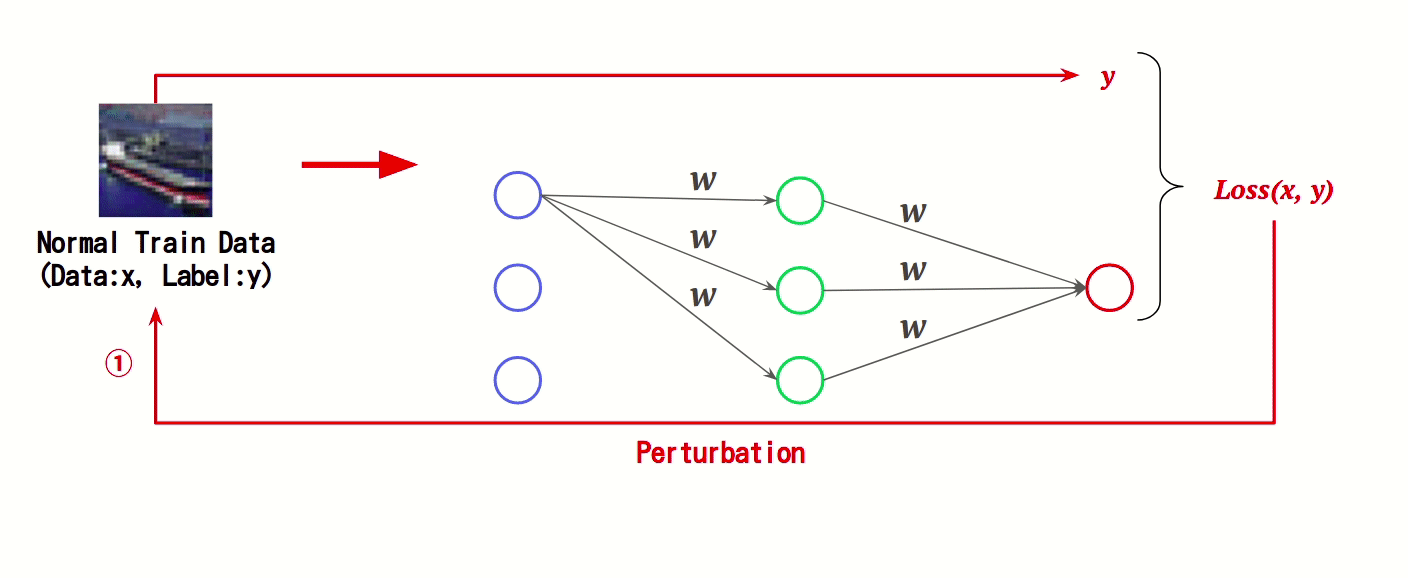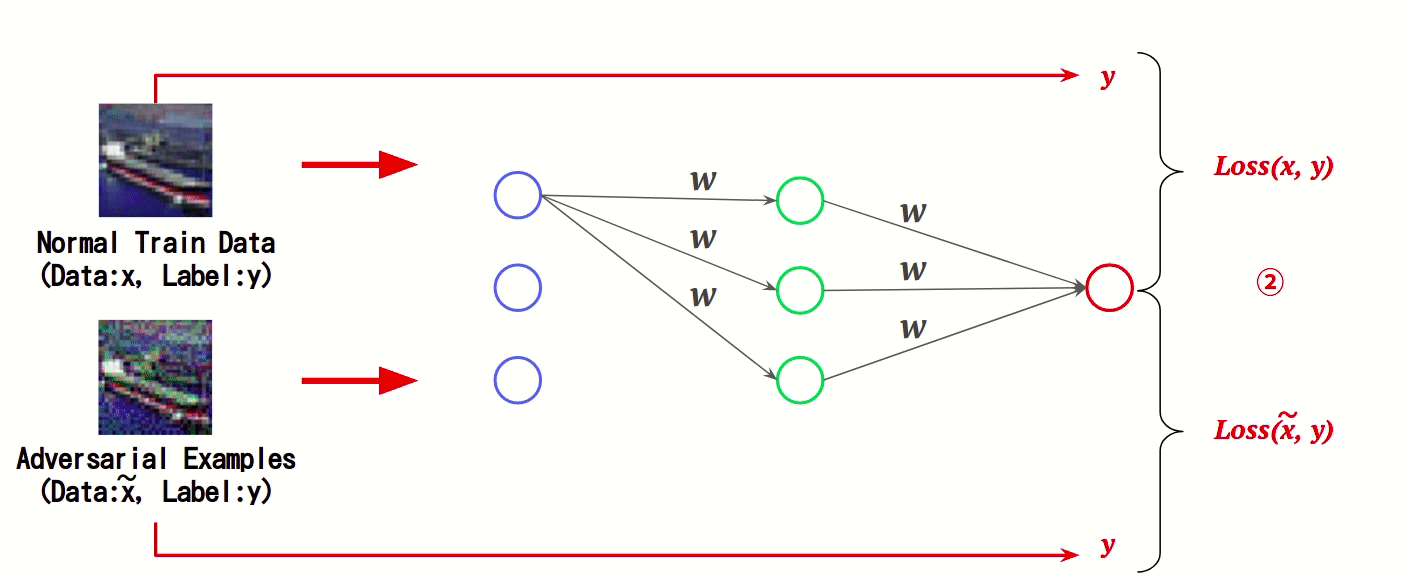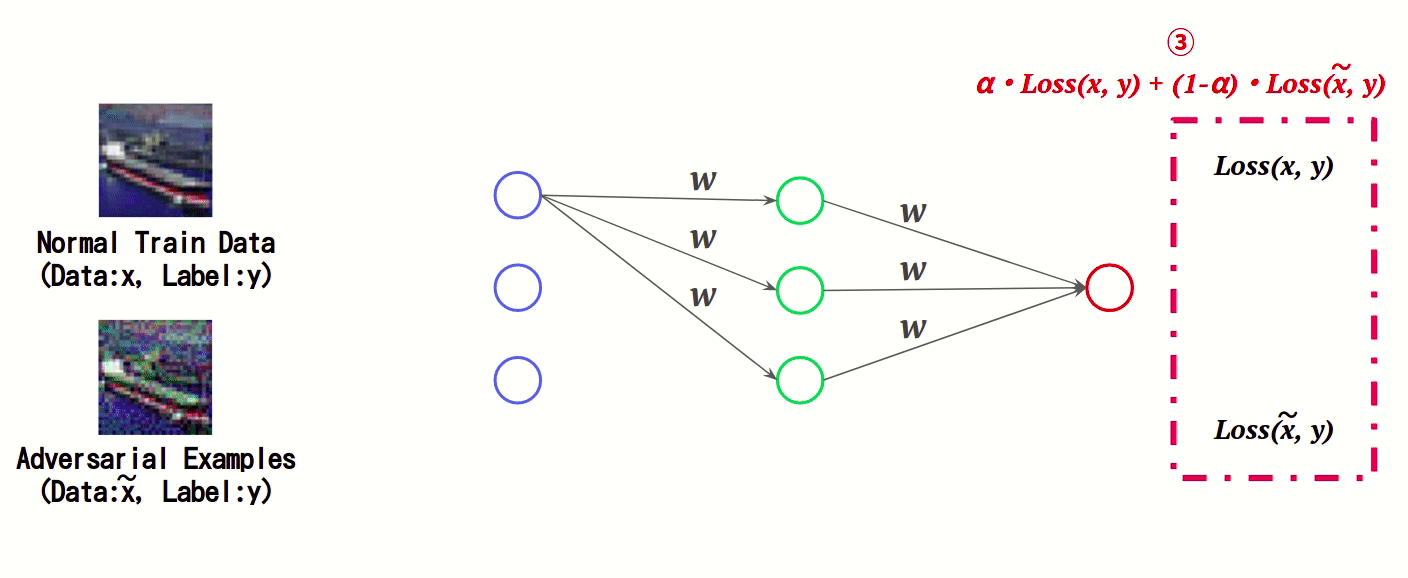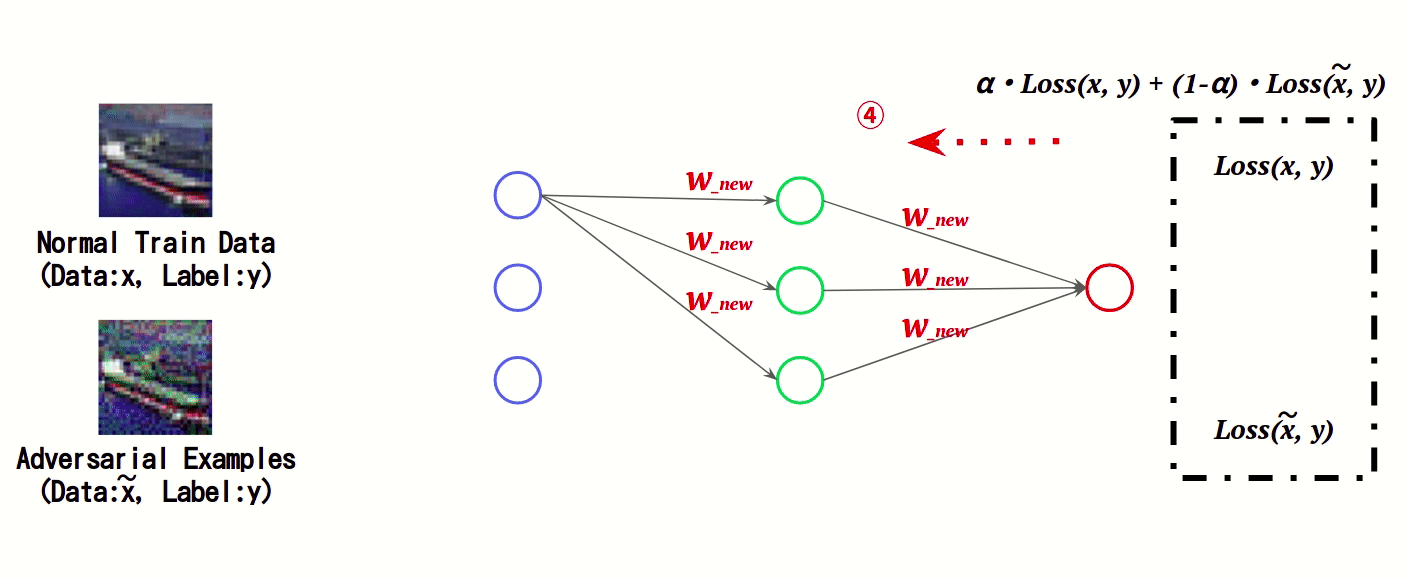
このように、AIの学習時に敵対的サンプルの特徴量を学習することで、敵対的サンプルによる誤分類を抑制します。
なお、敵対的学習は、通常のデータに加えて「敵対的サンプルを作成 -> 学習」する必要があるため、非常に多くの学習時間を要します。また、余計なデータを学習するためAIの精度が落ちることもあります。このため、精度を保ちつつ学習時間を短縮する様々な改善手法が提案されています。これらの手法は別項で紹介したいと思います。
より詳細な内容を知りたい方は、解説ブログをご参照ください。