


| 開発工程 | 攻撃分類 | 攻撃手法 | 防御手法 |
|---|---|---|---|
|
学習データの収集/作成 (Data Preparation) |
データ汚染 |
|
|
|
モデルの学習/作成 (Model Fitting) |
モデル汚染 |
|
|
|
モデルの設置 (Deployment) |
敵対的サンプル | ||
| データ窃取 |
|
||
|
|||
| モデル窃取 |
|
Copycat CNN
モデルを窃取する手法。攻撃者は標的AIに複数の正常なデータ(画像など)を入力し、これらに対する標的AIの分類結果(ラベル)と入力データを紐づけて模倣データセットを作成します。そして、攻撃者は手元の独自AIを模倣データセットで学習し、標的AIと同等の性能を達成できるようにします。通常、AIの開発には多くのリソースやコストが投入されているため、攻撃者にAIが模倣された場合、ビジネスモデルが崩壊するおそれがあります。また、攻撃者は模倣AIを回避攻撃やメンバーシップ推論攻撃の足掛かりとして利用することもできます。


Copycat CNNは、モデルの設置/運用・保守工程を狙った「モデル窃取」の1手法です。
2018年に論文「Copycat CNN: Stealing Knowledge by Persuading Confession with Random Non-Labeled Data」で発表されました。
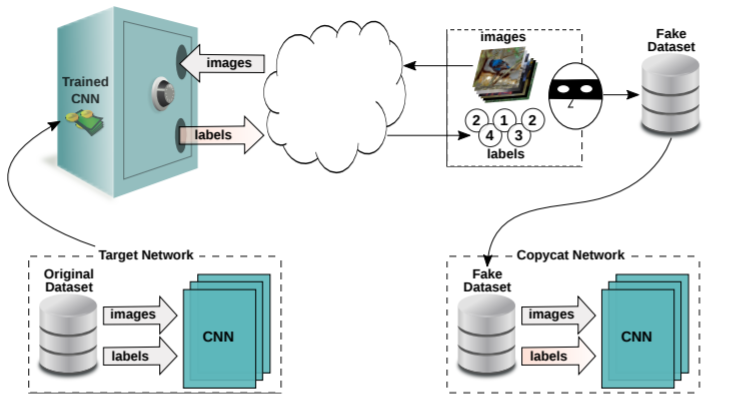
以下の図は、Copycat CNNを使用して標的AIを窃取する様子を表しています。
攻撃者は標的AI(Trained CNN)に複数のデータ(images)を入力し、これらに対するAIの分類結果(labels)と入力データを紐づけて「模倣データセット(Fake Dataset)」を作成します。そして、攻撃者は手元の独自AIを模倣データセットで学習し、標的AIと同等の性能を持つ「模倣AI(Copycat Network)」を作成します。
模倣AIはビジネスモデルの模倣以外にも、様々な方法で悪用することができます。
例えば、標的AIの学習データを推論する「メンバーシップ推論攻撃」においては、攻撃者の手元に標的AIを模した「シャドウモデル」を用意する必要がありますが、Copycat CNNで作成した模倣AIをシャドウモデルとして利用することができます。
また、標的AIの誤分類を誘発する「FGSM」においては、Copycat CNNで作成した模倣AIを使用して敵対的サンプルを作成することで、(攻撃の成功率が高い)ホワイトボックスの回避攻撃を行うことができます。
ところで、オリジナルのデータセットとは異なる「模倣データセット」を使用するだけで、標的AIと同等の性能を持つ模倣AIを作成することはできるのでしょうか?Copycat CNNを提案した研究者らは以下の図に示す大規模な評価実験を行い、模倣AIが標的AIと同等の性能を達成できることを明らかにしています。
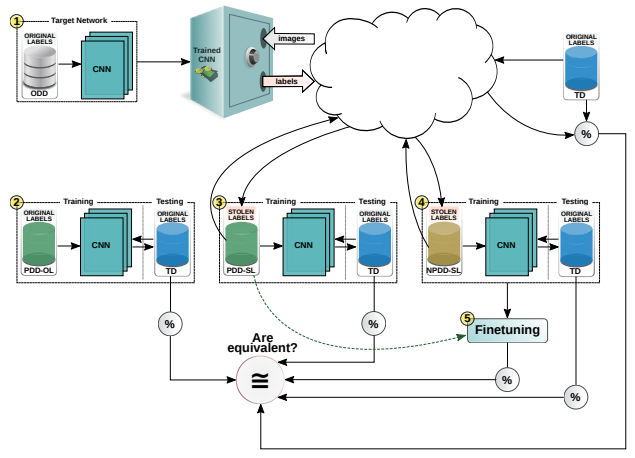
評価実験では、以下に示す5つのAIを使用しています。
| AIの種類 | 概要 |
|---|---|
| 標的AI(Target Network) |
攻撃対象となる標的AI(図中の①)。 標的AIのみアクセス可能なオリジナル・ドメイン・データセット(ODD: Original Domain Dataset)で学習されています。なお、ODDは企業にとって高価値であり、外部からのアクセスは許可されません。 |
| 標的AI(PDD-OL) |
攻撃対象となる標的AI(図中の②)。 価値の高いODDから入手した少量のデータをデータ拡張し、オリジナルのラベル(OL: Original Labels)で学習したAI。本評価実験のベースラインとなるAI。 |
| 模倣AI(PDD-SL) |
標的AIを模倣したAI(図中の③)。 標的AIと同じ問題領域のデータ(PDD: Problem Domain Data)と、これを標的AIに問い合わせて取得した盗用ラベル(SL: Stolen Labels)で学習した模倣AI。 |
| 模倣AI(NPDD-SL) |
標的AIを模倣したAI(図中の④)。 インターネット上で公開されている非問題領域データ(NPDD: Non-Problem Domain Data)と、これを標的AIに問い合わせて取得した盗用ラベル(SL)で学習したAI。 |
| 模倣AI(NPD+PD-SL) |
標的AIを模倣したAI(図中の⑤)。 NPD-SLで学習し、PDD-SLの学習に使用したデータセットで微調整(Finetuning)したAI。 |
本実験では、これらのAIを3つのタスク(FER: 顔の表情認識、GOC: 物体認識、SCC: 衛星画像による横断歩道認識)で性能評価しています。以下のグラフは比較結果を表しています。
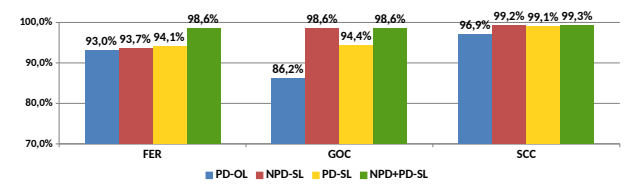
標的AIから取得した盗用ラベル(SL)を用いて学習された模倣AI(PD-SL、NPD-SL、NPD+PD-SL)は、標的AI(PD-OL)よりも高い性能を達成できていることが分かります。さらに、NPD-SLは、インターネット上から収集した標的AIの問題領域(PD)とは関係のない自然画像を大量に使用するだけで、標的AIを模倣できることが示されました。
なお、本実験で最も高い性能を発揮したのはNPD+PD-SLです。
この事実は、問題領域から取得したデータでNPDを微調整(Finetuning)することが性能向上に役立つことを示唆していますが、FERやGOCなどのタスクによっては、非問題領域のデータで学習したNPD-SLがNPD+PD-SLと同等の性能を発揮していることから、必ずしも取得コストの高い問題領域のデータを使用する必要はないことも示唆しています。
このように、Copycat CNNを使用することで、標的AIにデータを問い合わせて応答されたラベルを使用することで、標的AIと同等の性能を持つ模倣AIを作成することができます。これは、自社AIがAPIのみを公開している場合でも攻撃される可能性があることを意味するため、AIを模倣されないように対策を取ることは重要であると言えます。
より詳細な内容を知りたい方は、論文「Copycat CNN: Stealing Knowledge by Persuading Confession with Random Non-Labeled Data」をご参照ください。