


| 開発工程 | 攻撃分類 | 攻撃手法 | 防御手法 |
|---|---|---|---|
|
学習データの収集/作成 (Data Preparation) |
データ汚染 |
|
|
|
モデルの学習/作成 (Model Fitting) |
モデル汚染 |
|
|
|
モデルの設置 (Deployment) |
敵対的サンプル | ||
| データ窃取 |
|
||
|
|||
| モデル窃取 |
|
BadNets
AIにバックドアを設置する手法。攻撃のアプローチは2つあります。第一は、攻撃者は学習を代行するMLaaSを装い、利用者から学習前のモデルと学習データを受け取ります。そして、学習データに汚染データを注入して学習を行い(データ汚染)、バックドアが設置された学習済みモデルを利用者に返却します。第二に、攻撃者はあらかじめバックドアを設置した事前学習モデルを、正規のモデルを装ってModel Zooなどの事前学習モデル配布サイトで配布します。このようにバックドアが設置されたモデルを「BadNets」と呼びます。BadNetsは殆どの正常データを正しいクラスに分類しますが、攻撃者しか知り得ない特定の入力データ(トリガー)を攻撃者が意図したクラスに誤分類します。このため、BadNetsの推論精度は殆ど劣化することがなく、AI開発者・利用者がバックドアの存在に気づくことは困難です。


BadNetsは、モデルの作成・評価工程を狙った「モデル汚染」の1手法です。
2017年に論文「BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain」で発表されました(その後、2019年に更新版を公開)。
BadNetsは、AIにバックドアを設置する手法です。
以下の図は、BadNetsの概要を表しています。
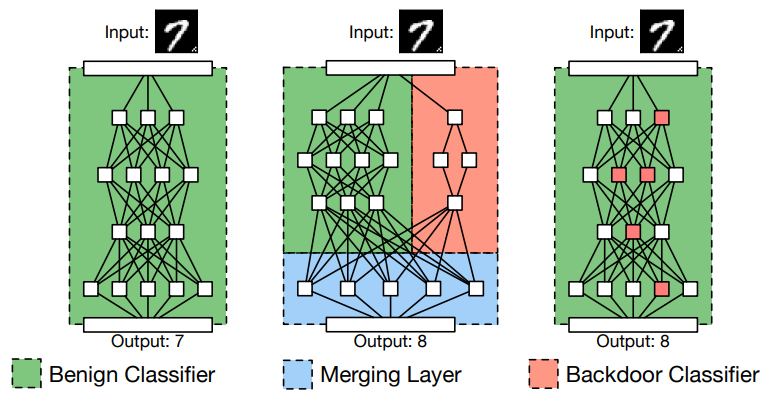
BadNetsは、正常な入力データを正しいクラスに分類する「Benign Classifier」と、(バックドアを起動する)トリガーデータを攻撃者が意図したクラスに誤分類する「Backdoor Classifier」を組み合わせたネットワークになります。
ところで、Backdoor Classifierを作成するためには、前項「データ汚染」と同じ原理でAIのパラメータ(重みなど)を細工する必要があります。そこで本手法では、以下2つのアプローチでBadNetsを作成します。
まずは、「Outsourced Training Attack」から見ていきましょう。
本アプローチは、AIの学習を代行する「悪意のあるMLaaS」を被害者が利用するシナリオを想定しています。
例えば、画像分類器の推論精度を向上させるためには、大量の学習データと数百万以上の重みが必要になります。このため、分類器の学習に伴う計算量は膨大になる場合が多く、高性能なCPU・GPUを使用した場合でも数週間の学習時間を要することがあります。
そこで、豊富な計算資源を有しない個人や企業の多くは、分類器の学習をMLaaSのようなクラウドコンピューティング・サービスに頼ることになります。現在、幾つかのクラウドコンピューティング・プロバイダーによってMLaaSが提供されています。例えば、GoogleのCloud ML Engineは、利用者が(学習前の)モデルと学習データを同サービスにアップロードすることで、クラウド上で学習させることができます。同様のサービスは、Microsoft AzureやAWSなども提供しています。
仮に、利用者が値段の安さなどに釣られて、攻撃者が運営する「悪意のあるMLaaS」を利用した場合、セキュリティ上の問題が生じることになります。
悪意のあるMLaaSを運営する攻撃者は、利用者(被害者)に学習データとモデルのアーキテクチャをアップロードしてもらい、これを基にモデルの学習を行います。この際、攻撃者は前項の「データ汚染」と同じ原理で学習データに少量の汚染データを注入し、モデルに学習させることでバックドアを設置します。そして、バックドアが設置された学習済みのモデルを利用者に返却します。
ところで、必ずしも利用者はMLaaSを完全に信用しているとは限りません。
MLaaSから返却された学習済みモデル(=BadNets)の推論精度が低い場合、モデルが破棄されてしまう可能性があります(攻撃の失敗)。よって、BadNetsによる攻撃が成功する条件は以下になります。
すなわち、正常データに対するモデルの推論精度を落とさずに、トリガーデータのみを誤分類させる必要があります。
以下の図は、Outsourced Training Attackを利用して道路標識認識モデルをBadNetsに仕立て上げ、攻撃を行った様子を表しています。

本攻撃では、黄色のポストイット・ノートをトリガーとし、これを「一時停止標識」に貼り付けることで、道路標識認識モデルに約95%の信頼スコアで「速度制限標識」として誤認識させることに成功しています。
以下の表は、バックドアが設置されていない正常モデル(Baseline CNN)とBadNetsの推論精度の比較を表しています。
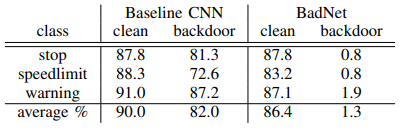
正常な入力データ(clean)に対するBadNetの推論精度は、正常モデルとほぼ同等になっています(正常モデル:90.0%、BadNet:86.4%)。一方、トリガーデータ(backdoor)においては、正常モデルの推論精度は82.0%であるのに対し、BadNetは僅か1.3%であることが分かります。この結果は、BadNetがトリガーデータの98%以上を別のクラスに誤分類させたことを意味しています。
この結果から、BadNetは正常データを正しいクラスに分類し、トリガーデータを誤ったクラスに誤分類させることに成功していると言えます。
ところで、BadNetsがトリガーデータを誤分類する際、BadNets内のノードはどのように活性化しているのでしょうか?
以下の図は、BadNets内の最後の畳み込み層の平均活性度を、正常な入力データ(Clean)とトリガーデータ(Backdoor)、および両者の差分(Difference)をプロットした様子を表しています。
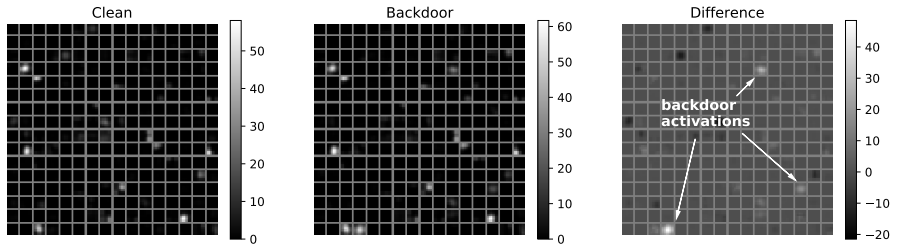
Differenceにて矢印で示すように、トリガーデータの検出に特化していると思われる3つのノードが存在することが分かります。つまり、これらのノードは、トリガーデータが入力された場合にのみ活性化されます。一方、他のノードの活性化は、トリガーデータの影響を受けないことも分かります。
この洞察を踏まえた上で、次の攻撃「Transfer Learning Attack」を見ていきましょう。
本アプローチは、被害者がモデル配布サイトから「攻撃者が細工した事前学習モデル」をダウンロードし、これを独自データセットで転移学習(Transfer Learning)して利用するシナリオを想定しています。
以下の図に示すように本シナリオでは、米国の道路標識データセット(U.S.Training Set)を学習したBadNet(U.S.BadNet)を利用者がダウンロードし、スウェーデンの道路標識データセット(Clean Swedih Training Set)を転移学習(Transfer Learning)して新しいモデル(Swedish BadNet)を作成するシナリオを想定しています。
つまり、U.S.BadNetに仕込まれたバックドアは、転移学習を行って作成したSwedish BadNetでも有効に作動することを確認します。
以下の表は、バックドアが設置されていない正常モデル(Swedish Baseline Network)とSwedish BadNetの推論精度の比較を表しています。
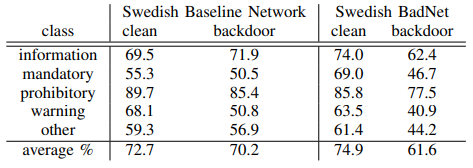
正常な入力データ(clean)に対するSwedish BadNetの推論精度は74.9%であり、正常モデルの推論精度(72.7%)よりも2.2%高くなっています。一方、トリガーデータ(backdoor)に対するSwedish BadNetの推論精度は61.6%に低下しており、これはSwedish BadNetがトリガーデータを別のクラスに誤分類させたことを意味しています(正常モデルは殆ど低下していない)。
以下の図は、Swedish BadNet内の最後の畳み込み層の平均活性度を、正常な入力データ(Clean)とトリガーデータ(Backdoor)、および両者の差分(Difference)をプロットした様子を表しています。
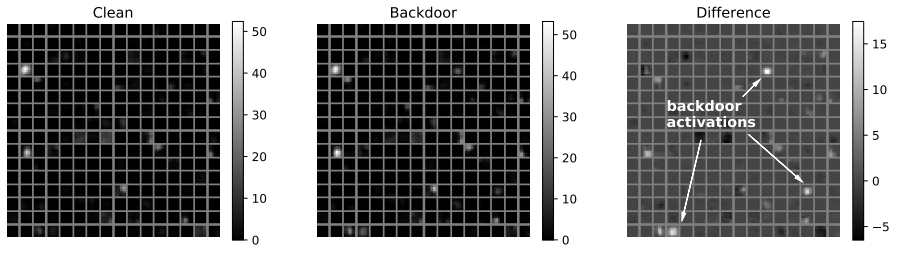
上図の通り、Outsourced Training Attackにおいてトリガーデータのみに反応したノードが、(Transfer Learning Attackで作成した)Swedish BadNetでも活性化することが分かります。つまり、BadNetsを転移学習した場合でも、(ノードの重みが更新されない限り)バックドアが有効に作動し続けることを意味します。
このように、攻撃者は「悪意のあるMLaaS」や「モデル配布サイト経由」でBadNetsを利用者に使用させることができます。よって、AI開発者・利用者は、信頼できるMLaaSを使用することや、インターネット上で公開されている事前学習モデルをむやみに使用しないこと、また、やむを得ず使用する場合はモデルのハッシュ値を検証するなど、極力BadNetsを掴まない努力をする必要があります。
また、上図で示したように、BadNetsにはトリガーデータのみに反応するノードが存在するため、正常データを与えた場合に活性化しないノード(=バックドアに反応するノード)を剪定することで、バックドアを無効化できる可能性もあります。
様々な経路でバックドアが設置され得ることを認識し、モデルの作成に注意を払う必要があると言えます。
より詳細な内容を知りたい方は、論文「BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain」をご参照ください。