本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。
3月31日(木)~4月1日(金)にシンガポールのMarina Bay Sandsで開催されたBlack Hat ASIA 2016 & Arsenalに参加してきました。Arsenalは聴講だけではなく、プレゼンターとしても参加しました。
本Blogでは、筆者らが初めて参加したArsenalの様子と、Briefingsの中から筆者が特に興味を持った研究発表を紹介します。

Fig1. Black Hat ASIA 2016のエントランス
■Arsenal
Arsenalとは、Black HatのBriefingsと並行して開催される「セキュリティに関するツールの展示会」であり、事前審査をクリアした企業の製品や自家製ツールなどが多数出展されます。筆者らは、以前本Blogで紹介した診断AI「SAIVS」(*1)を出展しました。 (*1)MBSD Blog「機械学習を用いた診断AIの概要」をご参照ください。
Arsenalは、「如何に訪問者を退屈させずに場を盛り上げるか」が重視されます。プレゼンターはコアタイムの間(90分)、専用ステーションにてツールを魅力的にアピールし、Arsenalを盛り上げることが求められます。このため、プレゼンターは自分のステーションに多くの訪問者を集めるために、ツールのロゴが入ったTシャツを着たり、大きなポスターを貼り出したり、ツールのデモンストレーションを面白くしたりと、多くの工夫を凝らしてツールを最大限にアピールする必要があります。なお、Briefingsと比較するとカジュアルな雰囲気があり、プレゼンターと訪問者は間近で顔を合わせ、自由闊達に意見交換や討論を行うことができる、といった特徴もあります。
今回のArsenalには全18チーム参加しており、中国やインドからの参加者が多数を占めていました。また、年齢層は20~30代が多くフレンドリーな方々ばかりで、Arsenalが始まる前にお互いのツールの紹介や業務内容をざっくばらんに話すなど、非常に穏やかな空気が流れていました。

Fig2. Arsenalのスケジュールボード
しかし、いざArsenalが始まると穏やかな雰囲気も一変します。筆者らのステーションは会場の入り口付近にあったこともあり、非常に多くの訪問者が殺到しました。そして、訪問者が各々質問やツールの説明/デモを求めてきたため、筆者らはゆっくりと考える暇もなく、とにかく対応に追われることになりました。また、訪問者は非常に真面目で熱心な方が多く、ツールの仕様や性能に関する質問や、(訪問者の)自社の課題解決に役立てないか?などのご相談も多数頂きました。中にはコアタイムが終了しても帰らずに質問を続ける訪問者もいました(笑)。
結果的に2日間合計で約150名の訪問者にお越しいただき、盛況のうちに終えることができました。事前準備や当日の対応など、かなりハードな面もありましたが、世界各国のプレゼンターや訪問者と意見交換ができ、濃密で貴重な経験をすることができました。

Fig3. 筆者(写真奥)らが訪問者に説明している様子①

Fig4. 筆者(写真右)らが訪問者に説明している様子②
展示したツール「SAIVS」に対しては、脆弱性スキャナに機械学習を組み合わせた手法は世界でも前例が少ないため、概ね好意的な評価を得ることができました。特に、脆弱性スキャナを開発している中国のエンジニアの方から、「very cool!」と言われたことが、強く印象に残っています。また、詳細なロジック開示や診断部分へのAI技術の応用などの貴重な要望も多数頂きました。主な要望例は以下の通りです。
- (クローリングだけでなく)診断部分へのAI技術の応用。
- 診断パターンの充実化。
- 大規模/複雑なWebサイトへの適用。
- 脆弱性のリスク付けや脆弱性の自動Fixへの応用。
- 詳細なロジックの開示/オープンソース化。
現在の「SAIVS」はプロトタイプですが、今後はロジックの改良や新機能の追加を行い、クローリング能力や診断能力を強化していく予定です。そして、最終的には実際の診断業務やバグバウンティプログラムにSAIVSを投入したいと考えています。
最後に、筆者らのステーションを訪れたインドのセキュリティコンサルタントの方から、筆者らと近しい研究をしている技術者を数名ご紹介いただきました。ツールの展示だけでなく、他国の技術者とのネットワークも構築することができ、非常に有意義な参加になりました。
■Briefings
筆者らは幾つかのBriefingsを聴講しましたが、ここではコロンビア大学のSivakorn氏らが発表した「I'M NOT A HUMAN: BREAKING THE GOOGLE RECAPTCHA」[1]を紹介します。
本Briefingsは、Googleが提供する「reCAPTCHA」(Fig5)[2]を低コストなシステムでクリアできることを証明した研究です。筆者は以前、機械学習を用いてテキスト形式のCAPTCHAのクリアを試みたことがあったため、Briefingsプログラムが発表された時から非常に興味を持っていました。
なお、reCAPTCHAとは、Webサイトの制限エリアにアクセスを試みるボットを遮断するための仕組みで、従来のCAPTCHAのように面倒な文字入力は必要とせず、画像を選択するだけの簡単な操作でボットではないことを証明できます。Fig5はreCAPTCHAの一例です。この例では、サンプル画像とヒントを手掛かりに、サンプル画像(ワイン)と同じ種類の候補画像を全て選択する必要があります。よって、左上と真ん中の候補画像を選択することで、ボットではないと証明することができます。

Fig5. reCAPTCHAの一例(出典:[1])
Sivakorn氏らが開発したシステム「Image captcha breaker」は、以下三つのサブシステムで構成されます。
- Image annotation module
GRIS(Google Reverse Image Search)[3]やClarifai[4]などのオンラインサービス、Caffe[5]やNeuralTalk[6]などのオフラインのライブラリ/プログラムを使用し、reCAPTCHAのサンプル画像/候補画像に対応するヒントやタグ(画像の注釈)を付与するシステム。
例)猫の画像にタグ「cat」を付与する、など。 - Tag Classifier
Image annotation moduleで取得したヒントとタグを比較し、画像の種類(e.g., wine, beer, coffee)を分類するシステム。なお、「cat」と「American shorthair」など、画像の種類は同じでもヒントとタグの文字列が完全一致しないことがあるため、自然言語処理用のアルゴリズム「Word2vec」[7]を使用して文字列の類似度を計算し、類似度が近い場合は同一の種類に分類する。 - History Module
reCAPTCHAで使用されるサンプル画像と対応するヒントを紐付けたデータセット。サンプル画像は何度も再利用されるというreCAPTCHAの特性を利用し、事前に大量のサンプル画像とヒントのセットを手動で作成したもの。
上記のサブシステムから分かる通り、このシステムはreCAPTCHAのサンプル画像の「ヒント」と全候補画像の「タグ」を比較し、ヒントと一致するタグを持つ候補画像を選択します。よって、「ヒントとタグの取得」と「ヒントとタグの比較」が非常に重要になります。
以下、Fig5のreCAPTCHAを通してシステムの処理過程を簡単に説明します。
- Image annotation module による候補画像のタグ取得
GRISやClarifaiなどを使用し、候補画像のタグを取得(Fig6, Fig7)。
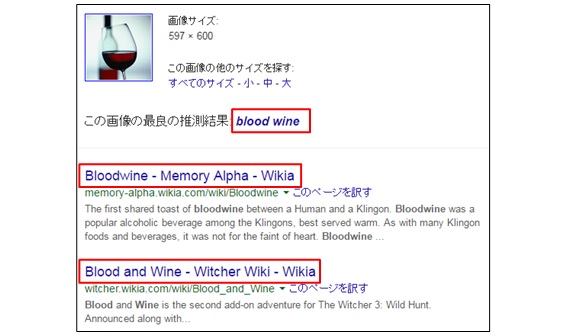
Fig6. GRISで候補画像を検索した様子(赤枠がタグ)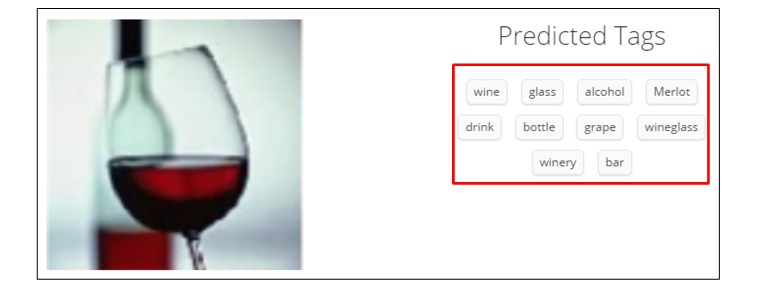
Fig7. Clarifaiで候補画像のタグを取得した様子(赤枠がタグ) - History Moduleによるサンプル画像のヒント取得
reCAPTCHAからヒントを取得できない場合、History Moduleからサンプル画像に対応するヒントを取得(ヒントが取得できた場合は、そのヒントをそのまま使用)。 - Tag Classifierによるヒントとタグの比較 上記1と2で取得したヒントとタグをTag Classifierで比較し、ヒントとタグが完全一致、または、文字列の類似度が近い場合、当該候補画像を「選択」する。
上記の処理を、全ての候補画像とサンプル画像の比較が完了するまで繰り返します。
-評価-
Sivakorn氏らは、Image annotation moduleにオンラインのサービス(Clarifai)を使用した場合と(オンライン)、オフラインのライブラリ(Caffe)を使用した場合(オフライン)の2パターンについて、reCAPTCHAの認識率と平均処理時間を指標に性能評価を行っています。評価結果を以下に示します。
| パターン | 認識率 (%) | 平均処理時間 (s) | 対象CAPTCHA数 |
|---|---|---|---|
| オンライン | 70.78 | 19.2 | 2,235個 |
| オフライン | 41.57 | 20.9 |
オンラインの認識率は「70.78%」であり、非常に高い認識率になっています。一方、オフラインの認識率は「41.57%」になっています。これは、一見すると低いように思えますが、有料のCAPTCHA解析サービス「De-Captcha.com」[8]との比較実験の結果、認識率はDeCaptchaに匹敵しており(DeCaptchaは「44.30%」)、平均処理時間はDeCaptcha以上(DeCaptchaは「22.5s」)とのことでした。このことから、インターネットに接続していないオフラインの環境であっても、有料のDeCaptchaと同等以上の性能を持つことが明らかになりました。
また、本システムの応用として、200個以上のFacebookの画像認証(Fig8)に適用したところ、オンラインのパターンで「83.5%」の認識率をはじき出したとの事でした。
この研究結果は、最新のreCAPTCHAであってもボットによるアクセスを遮断することができないことを示しており、Webサイトのアクセス制限のあり方を見直すきっかけを作ったという意味で、非常に意義深いものと考えられます。

Fig8. Facebookの画像認証(出典:[1])
-筆者によるCAPTCHA解析アプローチ-
筆者は以前、テキスト形式のCAPTCHAの認識を多層パーセプトロン(Multilayer Perceptron。以下、MLP。)を用いて試みたことがあります(*2)。ここでは、その際に使用した仕組みの解説や評価結果、考察を簡単に述べたいと思います。なお、MLPとは、入力データと出力データ間の複雑な関係をモデル化したもので、学習を重ねることで、何らかの入力に対する最適な出力を得ることが可能になります。 (*2)テキスト形式のCAPTCHAの自動認識は、既にGoogleのBursztein氏らによって 試みられています。
今回、MLPの評価に使用したCAPTCHAは以下の通りです(Fig9, Fig10, Fig11)。なお、CAPTCHAのノイズ除去のため、事前に二値化して白黒画像に変換しています。
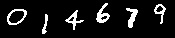
Fig9. CAPTCHAその1(014679)
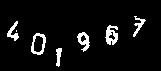
Fig10. CAPTCHA その2(401967)
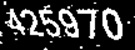
Fig11. CAPTCHA その3(425970)
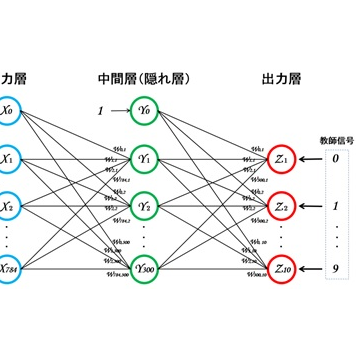
MLPはFig12の通りです。3層構造になっており、入力層のノード数は「784個」、中間層は「300個」、出力層は「10個」で構成されています。
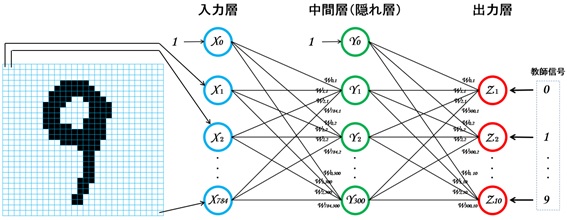
Fig12. CAPTCHA解析用MLP
入力する情報はCAPTCHAの各数字を28×28ピクセルの画像に切り出したもので、各画像をピクセル単位で入力層に入力します。このため、入力層のノード数は「(28×28=)784個」になります。また、出力層は「0~9」の何れかの数字を出力する必要があるため、出力層のノード数は「10個」になります。このMLPを使用することで、入力する数字画像に対して「0~9」の何れかの数字を出力することができます。
前述した通り、MLPで数字画像の認識を行うには、事前にMLPを学習(様々な数字画像と対応するラベル(0,1,2,3…)を覚えさせる)が必要です。本来であれば、Sivakorn氏らのHistory Moduleのように、認識対象CAPTCHAで使用される数字画像を大量に収集し、MLPに学習させた方が認識精度は向上しますが、ここではFig13のMNIST手書き数字データセットを使用します。このデータセットには、28×28ピクセルの手書き数字データ70,000個と、各データに対応するラベル(0,1,2,3…)が含まれています。何となくFig9, Fig10, Fig11のCAPTCHAの数字画像に似ているので、学習データとして使えそうです。

Fig13. MNISTの手書き数字データ(一部抜粋)
先ずは学習データを使ってMLPの学習を行います。筆者の環境(Intel Corei5 1.8GHz、Mem:8.00GB、SSD、GPU未使用)では、学習に3分ほどかかりました。
それでは、早速CAPTCHAの認識を行ってみます。なお、検証に際し、事前にFig9, Fig10, Fig11の各数字画像を28×28ピクセルの画像に切り出した上で、MLPに入力しています。
1番目はFig9のCAPTCHAです。
このCAPTCHAは、実はMNISTの学習データの中から無作為に選んだ6つの数字で構成されています。Sivakorn氏らのHistory Moduleの考え方が正しければ、Fig9のCAPTCHAは完全に認識できるはずです。
実行結果はFig14になりました(”predict”はMLPの予測、answerは答え)。
見事に全ての数字画像を正しく認識できています。対象CAPTCHAから収集したデータをMLPに学習させることで、認識精度が高くなることが分かりました。
No.0 : predict => 0 , answer = > 0 No.1 : predict => 1 , answer = > 1 No.2 : predict => 4 , answer = > 4 No.3 : predict => 6 , answer = > 6 No.4 : predict => 7 , answer = > 7 No.5 : predict => 9 , answer = > 9 00006 / 00006 = 100.00%
Fig14. Fig9のCAPTCHAの認識結果(数字を昇順に表示)
2番目はFig10のCAPTCHAです。
実行結果はFig15になりました。「0」や「1」は正しく認識できていますが、その他は全滅です。学習データとかけ離れた数字画像の場合は、正しく認識できないことが分かりました。
No.0 : predict => 0 , answer = > 0 No.1 : predict => 1 , answer = > 1 No.2 : predict => 6 , answer = > 4 No.3 : predict => 8 , answer = > 6 No.4 : predict => 8 , answer = > 7 No.5 : predict => 3 , answer = > 9 00002 / 00006 = 33.33%
Fig15. Fig10のCAPTCHAの認識結果(数字を昇順に表示)
最後にFig11のCAPTCHAです。
実行結果はFig16になりました。「0」「2」「5」は正しく認識できました。MLPが「9」を「8」と誤認しているのは面白い結果です。確かにFig11の「9」は人間が見ても「8」のように見えるため、MLPが”勘違い”したのかもしれませんね。
No.0 : predict => 0 , answer = > 0 No.1 : predict => 2 , answer = > 2 No.2 : predict => 6 , answer = > 4 No.3 : predict => 5 , answer = > 5 No.4 : predict => 3 , answer = > 7 No.5 : predict => 8 , answer = > 9 00003 / 00006 = 50.00%
Fig16. Fig11のCAPTCHAの認識結果(数字を昇順に表示)
この検証結果から、シンプルなMLPでさえも、テキスト形式のCAPTCHAをクリアできる可能性があることが分かりました。また、Fig14の結果から、認識対象CAPTCHAから収集した数字画像で学習データを作ることで、MLPの認識精度を高められることも分かりました。
-最後に-
Sivakorn氏らの研究や、筆者の簡易的な検証結果から、テキスト形式のCAPTCHAは勿論のこと、最新のreCAPTCHAでさえもボットにクリアされる可能性があることが明らかになりました。CAPTCHAやreCAPTCHAを使用しているWebサイトのオーナーは、CAPTCHAはカジュアルなボットのアクセスを防ぐ程度のものと認識を改め、アクセス制御の手段として過信すべきではないと考えます。
なお、Sivakorn氏らの研究結果は既にGoogleに提示されており、GoogleはボットによるreCAPTCHAの認識精度を下げるため、幾つかの策を講じたとのことでした。とは言え、暫くはボットの認識性能の進化とCAPTCHAの堅牢化のイタチごっこが続くことが予想されます。
筆者は、CAPTCHAが堅牢化され過ぎて、人間でもクリアできないCAPTCHAになってしまわないことを祈るばかりです。
■参考文献
[1] I'm not a human: Breaking the Google reCAPTCHA
[2] Google reCAPTCHA
[4] Clarifai
[5] Caffe
[6] NeuralTalk
[7] Word2vec
[8] De-Captcha.com
おすすめ記事


